正则化在机器学习中经常出现,但是我们常常知其然不知其所以然,今天Cathy将从正则化对模型的限制、正则化与贝叶斯先验的关系和结构风险最小化三个角度出发,谈谈L1、L2范数被使用作正则化项的原因。Cathy是初学者,理解有限,若有理解错误的地方还望大家批评指正。
首先我们先从数学的角度出发,看看L0、L1、L2范数的定义,然后再分别从三个方面展开介绍。
L0范数指向量中非零元素的个数
L1范数:向量中每个元素绝对值的和 [图片上传失败...(image-93aec5-1568861919446)]L2范数:向量元素绝对值的平方和再开平方[图片上传失败...(image-fa237b-1568861919446)]
应用一:约束模型的特性
1.1 L2正则化——让模型变得简单
例如我们给下图的点建立一个模型:
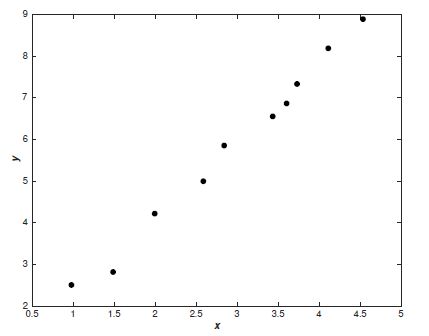
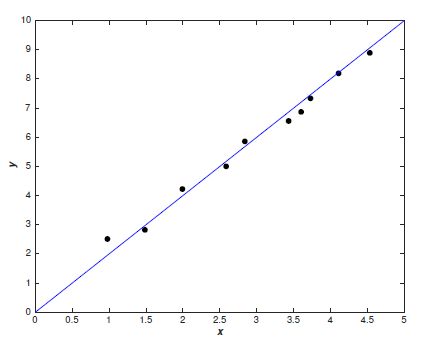
我们可以直接建立线性模型:
也可以建立一个多项式模型:
[图片上传失败...(image-cd7fa-1568861919447)]
:
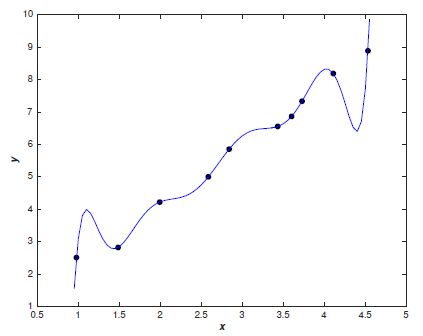
哪种模型更好呢?直观来讲,我们应该会选择线性模型。Occam's razor定律告诉我们,'Entities should not be multiplied unnecessarily'。这可以理解为简单的模型肯定比复杂的模型常见,如果一个简单的模型刚好适合拟合这些数据,那么我们会认为这个简单的模型恰好反应出一些潜在的规律。从这个角度来看,尽管多项式模型在已知的数据点上能近似地很好,但这是学习到了数据噪声的结果,在未知的数据的泛化上很有可能存在问题。
这就是我们常说的模型训练中的过拟合现象,即训练集误差在下降,测试集误差在上升。我们认为这是模型学习到了训练集中局部噪声的结果,它虽然在训练集上表现得好,泛化能力却比较差。因此我们需要更简单的模型,这个模型不会受到单个证据的影响,不会因为某个输入的微小变动而产生较大的行为改变。
L2正则化可以解决模型训练中的过拟合现象,它也被称为权重衰减。在回归模型中,这也被称为岭回归。我们先介绍L2正则化的实现方式,然后定性地介绍一下为什么L2正则化可以防止过拟合。
设损失函数为
[图片上传失败...(image-50def8-1568861919447)]
其中[图片上传失败...(image-e5a82-1568861919447)]
表示没有正则化时的损失函数。对它求w的偏导:
[图片上传失败...(image-6db26a-1568861919447)]
对w进行更新:
[图片上传失败...(image-4c0df2-1568861919447)]
我们知道,没有正则化的参数更新为[图片上传失败...(image-1c347f-1568861919447)]
,而L2正则化使用了一个乘性因子 [图片上传失败...(image-6e25cc-1568861919447)]
去调整权重,因此权重会不断衰减,并且在权重较大时衰减地快,权重较小时衰减得慢。
下面换一种方式来理解L2正则化对权重的限制。我们的目标是最小化下面的损失函数:
[图片上传失败...(image-a3e968-1568861919447)]
为了[图片上传失败...(image-e92eb2-1568861919447)]
最小,需要让[图片上传失败...(image-7c8c51-1568861919447)]
和正则化项的和能够最小。若w变大让[图片上传失败...(image-965f01-1568861919447)]
减小,[图片上传失败...(image-707a15-1568861919447)]
也会变大,后者就会抑制前者,从而让w不会上升地过大。此时[图片上传失败...(image-218aa4-1568861919447)]
就像是一个调整模型拟合精度与泛化能力的权重因子。
现在我们知道了,L2正则化能够限制参数的大小。那么,为什么参数大小被限制了,这个模型就是一个简单的模型,就能够防止过拟合了呢?回到我们最初开始介绍的多项式回归[图片上传失败...(image-bee8a9-1568861919447)]
,当参数很小时,高次方项的影响就会变得十分微弱,这使模型不会对某一个输入太过敏感,从而近似学习到一条简单的曲线,类似最开始的线性模型。也就是说,即使你预设的回归模型是一个9次的多项式回归,通过正则化学习,高次项前的系数 会变得很小,最后的曲线类似一条直线,这就是让模型变成了一个简单的模型。
总结一下,
- 正则化让模型根据训练数据中常见的模式来学习相对简单的模型,无正则化的模型用大参数学习大噪声。
- L2正则化通过权重衰减,保证了模型的简单,提高了泛化能力。
1.2 L0、L1正则化——让模型变得稀疏
我们知道,如果模型中的特征之间有相互关系,会增加模型的复杂程度,并且对整个模型的解释能力并没有提高,这时我们就要进行特征选择。特征选择也会让模型变得容易解释,假设我们要分析究竟是哪些原因触发了事件A,但是现在有1000个可能的影响因子,无从分析。如果通过训练让一部分因子为0,只剩下了几个因子,那么这几个因子就是触发事件A的关键原因。进行特征自动选择,也就是让模型变得稀疏,这可以通过L0和L1范数实现。
L0正则化
L0范数指的是向量中非零元素的个数,L0正则化就是限制非零元素的个数在一定的范围,这很明显会带来稀疏。一般而言,用L0范数实现稀疏是一个NP-hard问题,因此人们一般使用L1正则化来对模型进行稀疏约束。
L1正则化
设损失函数为:
[图片上传失败...(image-8d131e-1568861919447)]
其中[图片上传失败...(image-a2d846-1568861919447)]
表示没有正则化时的损失函数。对它求w的偏导:
[图片上传失败...(image-305edb-1568861919447)]
sgn(w)表示w的符号。对w进行更新:
[图片上传失败...(image-84d07d-1568861919447)]
可以看出,L1正则化是通过加上或减去一个常量[图片上传失败...(image-74c5d7-1568861919447)]
,让w向0靠近;对比L2正则化,它使用了一个乘性因子 [图片上传失败...(image-4b00b2-1568861919447)]
去调整权重,使权重不断衰减。因此可以得出:当[图片上传失败...(image-fb87c9-1568861919447)]
很大时,L2对权重的衰减速度比L1大得多,当[图片上传失败...(image-d0ef4a-1568861919447)]
很小时,L1对权重的缩小比L2快得多。
这也就解释了为什么L1正则能让模型变得稀疏。L1对于小权重减小地很快,对大权重减小较慢,因此最终模型的权重主要集中在那些高重要度的特征上,对于不重要的特征,权重会很快趋近于0。所以最终权重w会变得稀疏。
1.3 L1、L2正则化的形象理解
理解一:解的表示
L1、L2正则化还有另一种表示方式:
L1:[图片上传失败...(image-94d1dc-1568861919447)]
L2:[图片上传失败...(image-ec1e3-1568861919447)]
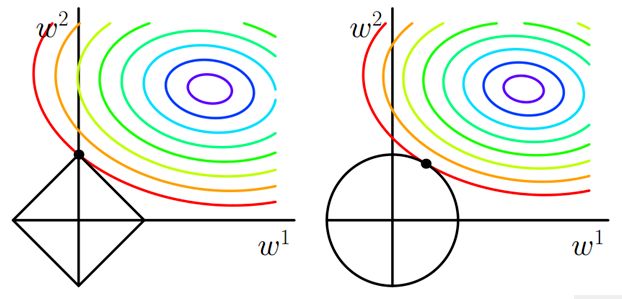
如上图所示,假设w是一个二维的向量,则目标函数可以用一圈圈等值线表示,约束条件用图中黑线表示,而我们要找的最优解,就在等值线和约束线第一次相交的地方。
左图是L1正则化的情况,在特征为二维时,约束线是一个菱形,等值线极有可能最先与顶点相交,在这种情况下有一个维度的特征就会为0,这就带来了稀疏。当特征的维度变高,坐标轴上角与边都会变多,这更会加大等值线与他们先相交的概率,从而导致了稀疏性。
L2正则化不同,如右图所示,它的约束线是一个圆形,等值线可能与它任意一个位置的点首先相切,这个切点在坐标轴上的概率大大 减小,从而不太容易导致稀疏。
理解二:下降速度
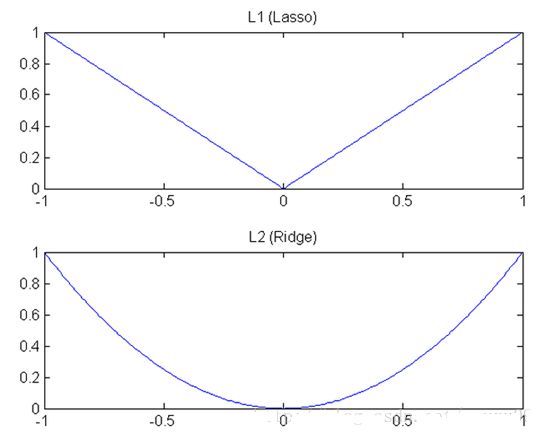
另外从下降速度来看,L1正则化是绝对值函数,L2正则化是二次函数,他们的函数图形如上图所示。可以看出L1正则化的下降速度一直都是一致的,这也符合之间得出的结论:L1正则化通过一个常数
[图片上传失败...(image-ebc6b6-1568861919447)]
来让权重减小:
[图片上传失败...(image-1acd19-1568861919447)]
而L2正则化的下降速度不同,当w大的时候,下降较快,当w小的时候,下降较慢,这也符合我们之前推导的,L2正则化通过一个乘性因子
[图片上传失败...(image-f35376-1568861919447)]
去衰减权重:
[图片上传失败...(image-3d1583-1568861919447)]
这种差异就导致当w较大时,L2的斜率大于L1,L2正则化权重衰减地比L1正则化快;w小时,L2斜率小于L1,L1正则化权重衰减地比L2正则化快。因此L1正则化最终会导致模型保留了重要的大权重连接,不重要的小权重都被衰减为0,产生了稀疏。而L2正则化可以通过限制权重大小让模型变得简单,但却不会导致稀疏。
应用二:贝叶斯学派中,对应于模型的先验概率
频率学派和贝叶斯学派
频率学派往往通过证据推导一件事情发生的概率,而贝叶斯学派还会同时考虑这个证据的可信度。从参数估计的角度来讲,频率学派认为参数[图片上传失败...(image-99acd1-1568861919447)]
是固定不变的,虽然我们不知道它,但是我们可以根据一组抽样值去预测它的结果,这就有了极大似然估计(MLE)。极大似然估计的思想就是,我已经抽样产生了一组值(例如抛硬币5次,得出结果:正正反正反),那么到底是什么参数(抛一次硬币,正面朝上的概率)才让我最有可能抽样出这一组结果呢。即我的目标是求出让似然函数最大的参数[图片上传失败...(image-ca233-1568861919446)]
:
[图片上传失败...(image-777503-1568861919446)]
而贝叶斯学派则认为参数[图片上传失败...(image-94eb82-1568861919446)]
本身就是一个随机变量,它也有自己的分布。如果我们现在已经有一组结果(正正反正反),我们可以根据这个结果求出随机变量[图片上传失败...(image-ebbae-1568861919446)]
最有可能的值,这其实就是最大后验概率估计(MAP)。最大后验概率估计是要求出[图片上传失败...(image-fa8825-1568861919446)]
最大的[图片上传失败...(image-cead1e-1568861919446)]
,我们知道:
[图片上传失败...(image-cf7954-1568861919446)]
P(X)作为确定值,我们不考虑它,最大后验概率估计变成了:
[图片上传失败...(image-573b3f-1568861919446)]
可以看出它只是在极大似然估计的基础上乘上了参数的先验概率,也就是说我求出的参数不仅仅有最大的概率产生这组值(正正反正反),它本身出现的概率也必须大。
举个通俗易懂的例子,如果你出门遇到一位算命师傅,他说你最近有桃花运,果然你不久之后就被心仪的人表白,这说明这个师傅算命很准(记作事件A),现在我们来讨论下这个师傅究竟会不会算命(将师傅会算命记作证据B)。从频率学派的角度来看,如果师傅会算命(证据B发生),那么他算对了我的桃花运是一件概率很大的事情。也就是说P(A|B)很大,从极大似然的角度讲,我们应该相信师傅会算命。可事实上我们根本不会相信师傅会算命,因为我们本身对会算命这件事有着先验的不相信,也就是说在我们眼中,P(B)是很小的。这说明我们已经潜移默化地用了贝叶斯思想,在最大后验概率估计中,P(B|A) ~ P(A|B)P(B),即使P(A|B)很大,如果P(B)很小,那么P(B|A)还是会小。
先验概率与L1、L2范数
当模型的目标函数是最大化后验概率[图片上传失败...(image-a91c64-1568861919446)]
,即最大化:
[图片上传失败...(image-54064f-1568861919446)]
连乘导致下溢,我们取负对数将其转化为最小化损失函数:
[图片上传失败...(image-e6d1d6-1568861919446)]
下面我们将证明参数的先验概率如何变成了损失函数的正则化项。
-
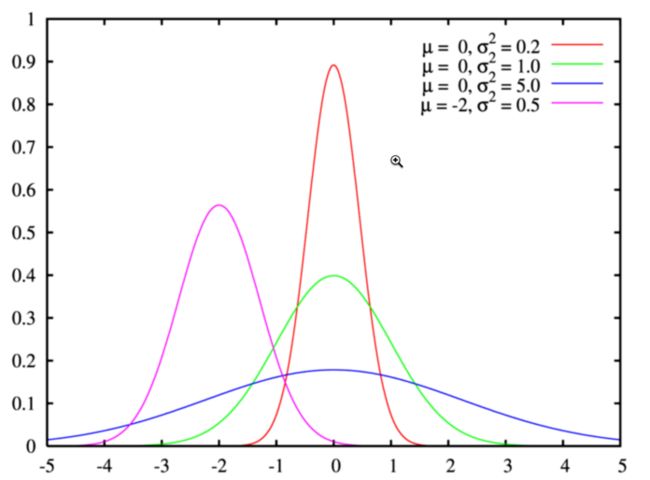
(1)假设[图片上传失败...(image-a800ac-1568861919446)]
的先验分布是高斯分布[图片上传失败...(image-d66137-1568861919446)]
,则:
[图片上传失败...(image-17b71-1568861919446)]其中m表示w的向量维度。最终目标函数为最小化:
[图片上传失败...(image-763438-1568861919446)]其中[图片上传失败...(image-d84115-1568861919446)]
,最终先验概率转变成了L2正则化项。
 image
image -
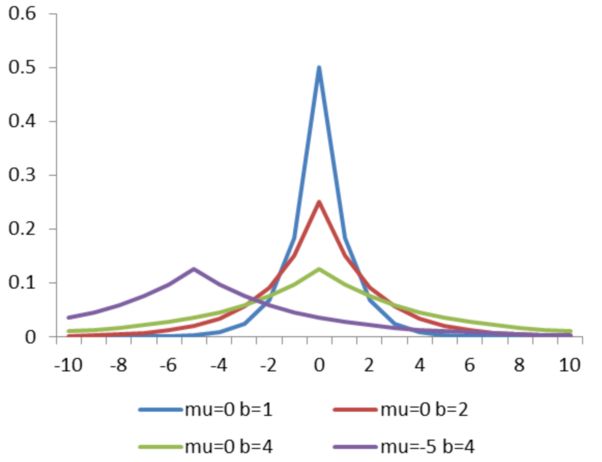
(2)假设w的先验分布时拉普拉斯分布,则:
[图片上传失败...(image-9a5048-1568861919446)]其中m表示w的向量维度。最终目标函数为最小化:
[图片上传失败...(image-e3ccea-1568861919446)]其中[图片上传失败...(image-106b9d-1568861919446)]
,最终先验概率转变成了L1正则化项。
 image
image
总结一下
- 概率目标函数通过负对数转化,将正态分布和拉普拉斯分布的指数项转变成了普通的一次、二次项;
- 先验分布为高斯分布,对于损失函数的L2正则化项,先验分布为拉普拉斯分布,对应损失函数的L1正则化项。
应用三:结构风险最小化
首先介绍一下什么是期望风险、经验风险和结构风险。在机器学习的目标中,理论上我们应该尽力让期望风险(期望损失,expected loss)最小化:
[图片上传失败...(image-57b255-1568861919446)]
但实际上,联合分布P(X,Y)我们是不可能知道的,因此在实际训练中,我们常常最小化经验风险(经验损失, empirical loss):
[图片上传失败...(image-b07664-1568861919446)]
期望风险是模型关于联合分布的期望损失,经验风险是模型关于训练样本集的平均损失,当N趋近于无穷时,经验风险趋近于期望风险,因此我们可以用经验风险最小化去近似期望风险最小化。
然而,我们的训练集样本数量N很有限,用经验风险估计近似期望风险往往不理想,容易产生“过拟合”的现象,因此需要使用结构风险来矫正经验风险。
结构风险(structural risk)最小化的目的是防止过拟合,它是在经验风险上加上表示模型复杂度的正则化项:
[图片上传失败...(image-52982-1568861919446)]
其中J(f)为模型的复杂度。结构风险最小化的目标就是让经验风险与模型复杂度同时小。监督学习的问题实际上也就是经验风险或结构风险最小化问题,对于样本容量大的情况,经验风险最小化可以达到很好的效果,例如极大似然估计;当样本容量不够时,需要使用结构风险最小化来避免过拟合,例如最大后验概率估计,其模型的复杂度由模型的先验概率表示。
以上三种应用的统一
- 结构风险其实是让经验风险与模型复杂度同时小,实际上也是在约束模型的特性。
- 正则化可以约束模型的特性。简单的模型还是稀疏的模型,实际上都来自与我们对这个模型的事先感知,从贝叶斯的角度来理解,也可以认为这是模型的先验。
- 而结构风险是在经验风险后面加上表示模型复杂度的正则化项,最大后验概率估计就是最小化的结构风险,它的模型复杂度由模型的先验概率表示。当模型的先验分布为高斯分布时,认为模型复杂度是平方复杂度;当模型的先验分布为拉普拉斯分布时,认为模型的复杂度是绝对值复杂度。
- 总的来说可以理解为:结构风险考虑了约束模型的特性,模型的特性是由模型的先验知识确定的,先验的不同导致了L1、L2正则化项的不同使用。
本文地址 https://www.jianshu.com/p/4bad38fe07e6
https://cathyforeveryoung.github.io/