更新于2017年6月26日,在第二部分数据探索时,根据@Radon的建议,为了消除极值对结果的影响,在统计比例前去除了离群点(outliers)的用户。
前言
是的,继《摆渡人》后豆瓣又被《李雷和韩梅梅》制作方控诉了。
电影《李雷和韩梅梅》出品人陈永宁发出的公开信称,《李雷和韩梅梅》在上映后获得诸多影评人、著名专家学者如饶曙光、尹鸿、周黎明、史航等人的认可,已经获得了三千万票房,但在“阿北”“领导下的豆瓣”该片得分只有4.2分,陈永宁表示“已经出离愤怒”,他认为豆瓣已经成为“绑票和敲诈的现场”。
作为豆瓣7年忠实用户,我觉得这个帽子扣的很不讲道理呀,出于探索精神,我去看了下这部电影的豆瓣页面。

粗粗一看,这不就是很典型的被誉为“绝世烂片”的L型电影嘛!
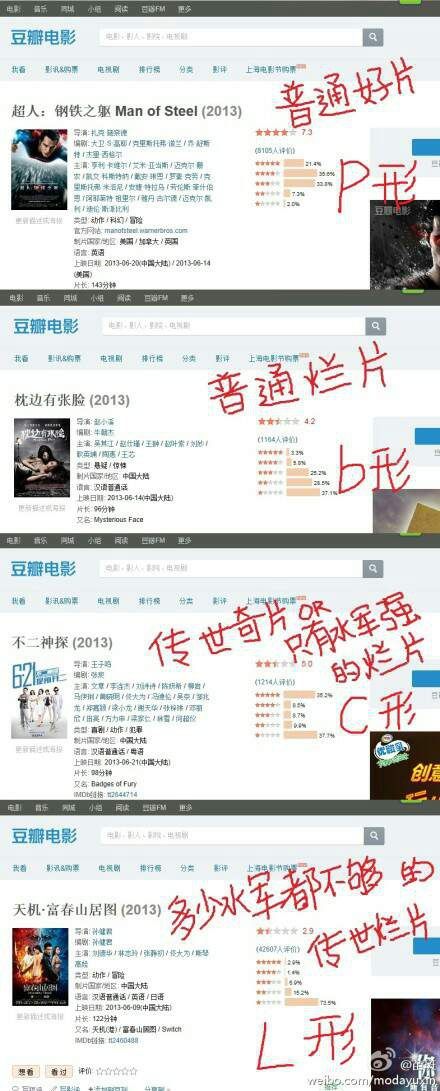
当然,只凭着评分形状来判断一部电影好坏也是比较片面,我想从数据分析的角度,从尽量客观的角度来对《李雷和韩梅梅》的评分做一个研究,希望能证明这部电影是否有恶意带节奏或者大量非正常用户评分评论的情况,活生生把一部优秀的电影刷成了绝世烂片。
数据搜集及处理
首先,应该从具体的评分和评分用户入手。因此,我决定抓取我们所能看到的评论信息。
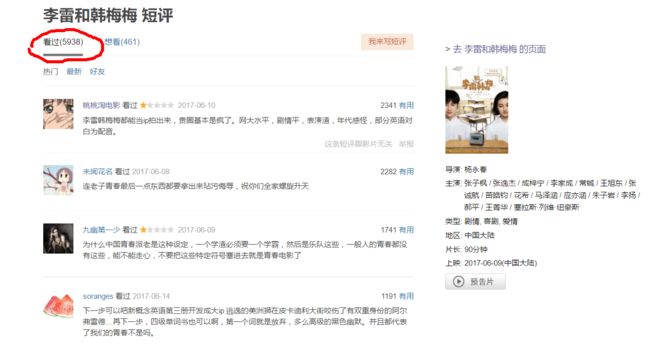
截至到我开始爬数据的时候,在一万多的用户里有5938人撰写了观后的短评。所以我开始抓取这些人的评论以及个人信息。数据包含的字段如下(后来补上了一个评论时间):

这其实是一个两层抓取,首先抓取在电影页面上的评论,然后再针对每一条评论,转到该评论用户的个人页面,抓取他的其他信息。最后得到了1838条数据,也就是说普通用户在网站上能看到的关于这部电影的评论只有1838条,还有一部分是被豆瓣给隐藏了。
问题一:豆瓣是否有故意隐藏评分高的评论而展示评分低的评论的行为?
在1838条数据中,只有1765条数据是有打分,剩下的是评论了但是没有打分,我对者1765条数据计算了所占比例,如下:


我们可以看出来,在我们所能看到的短评中,5星人数有9%,4星人数有7%,而1星所占的比率降到了50%。也就是说,在短评展示页面里,在我们所能看到的有限的短评里,3星及以上评论的人数的比例是超过了整体的评分情况。第一个问题的答案也就不言而喻。
另外如果按照短评打分情况来算电影评分的话,李雷和韩梅梅应该可以再稍微高一点,整体分会在3-4分左右。我觉得公开信中提到的4.2分是比较接近短评的整体评分。
问题二:究竟是哪些人打了分?
根据用户信息,在去掉离群点后的用户中,平均每个人标记“看过”电影63部,标记“想看”电影3部,平均注册时间为 2015年4月29日。针对不同打分等级以及不同的特征,得到如下图表:
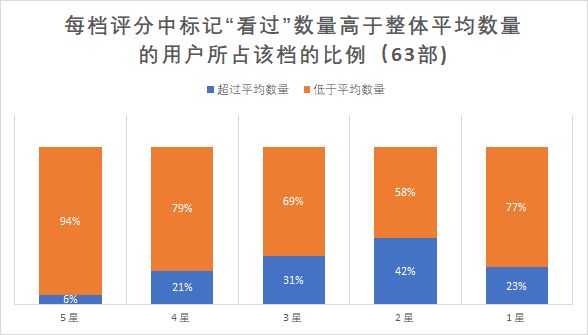


从以上三张图表我们可以看出,其中打5星和4星的用户,无论是“看过”,“想看”,还是“注册日期”上,达到所有用户中平均水平的人数比例都相当之低。由此可得,在5星和4星评分中,充斥着“标记影片数量少,注册日期晚”的用户。而反过来看打分低的用户,其中打2星的用户有42% 的人所标记的“看过”电影数量高于整体平均水平,五个档次中比例最高,其次是3星和1星。值得注意的是,在注册时间上,打1星的用户注册时间早于2015年4月29日的达到了40%,和5星的最低比例21%形成了强烈的反差,这类用户属于“注册时间早,标记影片数量多”,的确都较多集中在了低分档。为了更加直观表现用户分类,我们可以看下面这张数据透视图:

此时,我们大概知道给《李雷和韩梅梅》这部电影评分的1765个用户是怎么样子的了:打五星的用户,以豆瓣新用户为主,他们注册时间比较短,使用豆瓣次数比较少,标记“看过”和“想看”的电影也比较少。打一星和二星的用户以豆瓣老用户为主,豆瓣重度使用者,经常标记看过的电影,部分用户“看过”电影的数量惊人。
不过,由于在制片方控诉豆瓣后,有部分义愤填膺的用户涌入评论区,给电影打1分出气,所以1星用户情况可能和现实有点差距,个人认为2星到4星分布的用户特征比较符合实际的情况(即,如果没有这件“控诉”事,这部电影自然的打分情况)
问题三:究竟有没有非正常评分用户混在评论群体中?
豆瓣CEO在上一次评分风波中写了一篇文章,豆瓣电影评分八问,比较客观的介绍了豆瓣目前打分机制以及对水军的预防机制。
水军是有的,但豆瓣评分很难刷得动。
豆瓣这两年的原则是“所有能判断属于非正常评分的一概不算”,不分高低贵贱颜色。
这时候我就在想,我们所能看到的1765条评论中,是否如豆瓣所说,非正常评分评论一概不算,不会显示出来。为此,我们需要利用数据分析的方式对其做一个简单粗略的检测。
为了检测出是否有“非正常评分用户”的存在,我给他们下了大致的定义(我所理解的定义),比如只看过一两部电影,其中就包括《李雷和韩梅梅》,或者注册时间很短,豆瓣除了一部电影的内容,再无其他,没有“想看”标记,豆瓣活跃度极低,或者是好几个评论时间出现在差不多的时候而且都给了最高分或者最低分,还有一部分就是恶意打分,喷子这类。比如这些:
-
这是一个我认为比较有代表性的“非正常评分用户”,两个月注册无动态,看过和想看的内容有重复,评论矛盾。
 非正常评分用户1
非正常评分用户1 -
这是另外一个疑似“非正常评分用户”,注册当天即评论,而且评论标点符号使用诡异。
 非正常评分用户2
非正常评分用户2 -
这也是另外一个“非正常评分用户”,注册即评论,无头像,除了这部电影外没有其他内容。
 正常评分用户3
正常评分用户3 -
像这个就是属于正常评分用户,虽然给这部电影打了五星高分,但是从其他信息我们还是能看出来他并不是“非正常评分用户”
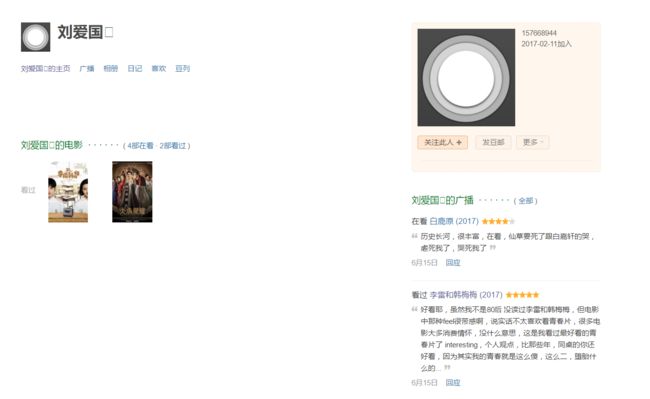 正常评分用户1
正常评分用户1 -
这个虽然给电影打了五分,但是根据注册时间,注册名字,观影数量来看,这是一个真实的用户,还是李易峰的粉丝......
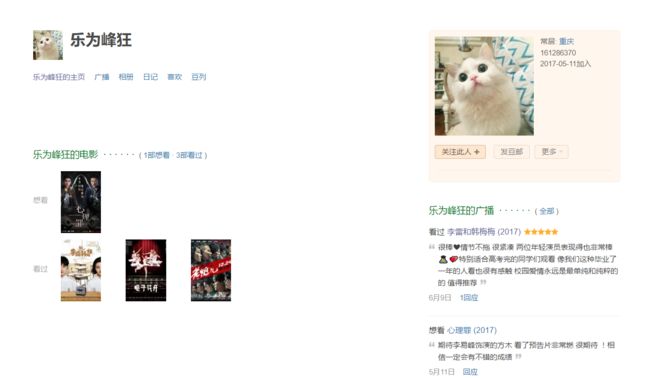 正常评分用户2
正常评分用户2
当然我不可能一个个去识别识别水军,这时候就要机器学习出马了!说到机器学习,我想起了下面这张图:

具体怎么做呢?(注意:本操作不具有科学性,仅供参考)
我随机从1765个样本中随机抽取了200个样本(其实并不是随机,由于非正常用户数量比例肯定较少,我人工加了一些预判为非正常用户),人工对他们进行了是否为正常用户的判断,主要将每个样本分为“正常评分用户”和“非正常评分用户”两类,不过对于那些模棱两可我实在无法判断的用户,将其标记为“疑似非正常评分用户”,就这样我完成了200个样本的构建,用于训练模型。
在训练前,我选取了四个特征值,分别是“看过”的电影数,“想看”的电影数,“注册日期”和“评论日期”。并且对数据做了标准化。
这次用到的模型是决策树模型,200个样本我选取了120个作为测试集,80个作为训练集,拟合了一下,准确率达到了90.6基本可以了,然后应用的到了所有的数据集,最后结果如下:


从结果来看,的确还是有“非正常评分用户”混迹在评分中,不过如果按照我的定义,给电影打1星的“非正常评分用户”其实是小于给电影打5星的“非正常评分用户”,也就是说其实绝大部分的打分都是用户看法的一个实际反映。
此外,还有一个值得注意的是根据这个结果,在打分为2星的用户中,非正常评分用户和疑似非正常用户所占的比例最小,这似乎也从另一个方面印证了前面我所提到的“打两星的用户是比较正常的”。
总结和局限性
通过对三个问题的分析,基本可以坐实豆瓣没有故意对这部电影进行打压,以及也没有大规模的非正常用户对电影评分进行影响,评分的结果还是比较接近豆瓣用户对这部电影的看法——烂片无疑。
本次数据分析简单应用了机器学习,其实还是有很多水分,比如特征值比较少,没有很强的说服力,不过这也给之后的研究提供了方法,我们可以通过提取用户个人主页一切所能提取的特征,然后再对其进行身份识别,最后这个识别水军的模型肯定是越来越准确。