很多时候我们需要从GEO(https://www.ncbi.nlm.nih.gov/geo/)下载RNA-seq数据,一个典型的下载页面是https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE76381(搜 GSE76381)。
这里你会看到数据的总览:
GSM2268339 1772067089_A01
GSM2268340 1772067089_A02
GSM2268341 1772067089_A03
Supplementary file Size Download File type/resource
SRP/SRP067/SRP067844 (ftp) SRA Study
GSE76381_ESMoleculeCounts.cef.txt.gz 5.9 Mb (ftp)(http) TXT
GSE76381_EmbryoMoleculeCounts.cef.txt.gz 5.3 Mb (ftp)(http) TXT
GSE76381_MouseAdultDAMoleculeCounts.cef.txt.gz 1.0 Mb (ftp)(http) TXT
GSE76381_MouseEmbryoMoleculeCounts.cef.txt.gz 6.1 Mb (ftp)(http) TXT
GSE76381_iPSMoleculeCounts.cef.txt.gz 1001.2 Kb (ftp)(http) TXT现在我们已经从ftp上下载了该文章的所有sra数据。
名称 大小 修改日期
[上级目录]
SRR4055063/ 2016/8/24 上午8:00:00
SRR4055064/ 2016/8/24 上午8:00:00
SRR4055065/ 2016/8/24 上午8:00:00
SRR4055066/ 2016/8/24 上午8:00:00
......
里面每一个文件夹里对应一个或多个sra文件。
比对,SRR4061391.sra文件是一个二进制文件,需要使用sra工具来转化为fastq。
转换之后的fastq如下:
@SRR4061391.sra.1 Run0289_BC69A1ACXX_L7_T1101_C8 length=51
ATTCAAGGGAGTTATAAGCAGAGTCAATAATGAATTTCTTCCTGCGTCTCC +SRR4061391.sra.1
Run0289_BC69A1ACXX_L7_T1101_C8 length=51
CCCFFFFFHDHFHIJJJJJGJIIEHHIJJJJIIIIJJIIJIJJJIJJJJJJ
@SRR4061391.sra.2 Run0289_BC69A1ACXX_L7_T1101_C18 length=51
TTGATTGGGCACCTAGAAGCCAAGGACTCTCTAAGTCCTAGTCTGTTTGGT +SRR4061391.sra.2
Run0289_BC69A1ACXX_L7_T1101_C18 length=51
CCCFFFFFHHHHHJJJGIJIIJJJJJJJJJJJJJJIIJJIIIJJJJJJJJF
可以看到,fastq文件里没有任何有价值的样品信息(物种、样品名、细胞名、组织)。
此时你只能去文章里找相关信息:
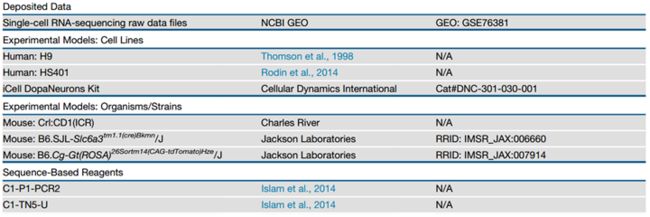
文章里真正实用的信息很少,
The molar concentrations of the libraries was determined with KAPA Library Quant qPCR (Kapa Biosystems) and size distribution was evaluated after PCR (12cycles) using an Agilent BioAnalyzer. Sequencing was performed on an Illumina HiSeq 2000 with C1-P1-PCR2 as read 1 primer and C1-TN5-U as index read primer. Reads of 50 bp as well as 8 bp index reads corresponding to the cell-specific barcodes were generated. Reads were mapped using bowtie and processed as described previously (Zeisel et al., 2015), adding the more strict criteria for UMI counting: we removed all singletons (molecules supported by a single read).
也没说太清楚,下载的数据中找不到那8bp的barcode,说明数据已经按照barcode拆好了。
Reads of 50 bp were generated along with 8 bp index reads corresponding to the cell-specific barcode. Each read was expected to start with a 6 bp unique molecular identifier (UMI), followed by 3-5 guanines, followed by the 5’ end of the transcript
绕了一大圈,真正有价值的信息原来在引文中,所以现在的大牛真是喜欢拽,非要别人去读他之前的文章。
总结:到此,该文献的全部数据是下下来了,也已经转换为fastq,知道fastq的格式信息,但是我们还不知道没一个fastq的样品信息。
回到开始的页面,貌似有样品的信息:
GSM2268339 1772067089_A01
GSM2268340 1772067089_A02
GSM2268341 1772067089_A03
这是全部的信息:

确实是样品信息,样品编号,物种信息。
点击GSM2268340会发现一些更详细的样品信息:
[](javascript:void(0); "复制代码")
Status Public on Oct 06, 2016 Title 1772067089_A02
Sample type SRA
Source name ventral midbrain
Organism Homo sapiens
Characteristics tissue: ventral midbrain
Sex: pooled male and female
age: 7w inferred cell type: hRgl2a
总结:但是到目前我们还是找不到SRR文件的样品信息,只是找到了GSM的.
那么怎么找SRR和GSM之间的关系呢?
直接在GEO搜索SRR4061391,结果如下:
终于找到了对应关系,SRX2050530: GSM2274293: 1772096111_A02; Mus musculus; RNA-Seq
GSM2274293包含了两个SRR文件。

总结:到目前为止,已经能手动查找到下载的SRR文件对应的样品信息了。但总共有6k多个,不可能这么手动查吧。
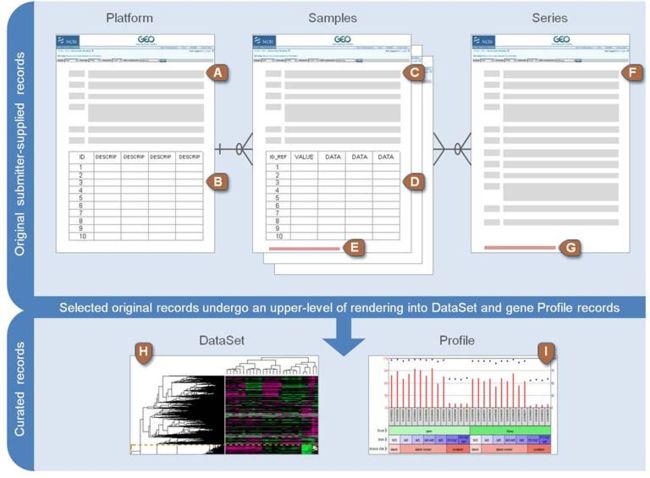
开始科普:About GEO DataSets
Lists the DataSet (GDS), Series (GSE) or Platform (GPL) accession number, followed by title and organism.
lists the Sample accessions numbers (GSM) and titles.
GDS编号:数据集
GSE编号:系列
GPL编号:平台
GSM编号:样品登陆号
参考:
About GEO DataSets
GEO Overview
Question: From A Geo Gsm Id, How To Obtain The Corresponding Raw File(S) Hosted On Sra?