时间:2018-12-18 作者:魏文应
一、前 言
通过这个本文,你将知道如何构建一个C++项目:
- 编译一个目标(target)。
- 可视化项目中目标的相互依赖关系。
- 控制包的可见性,也就是限定包的作用域。
其实,就是使你对 bazel 如何组织、编译一个 C++ 项目有一个大致了解。这里,你可以参考 bazel 官方教程《Introduction to Bazel: Building a C++ Project》:
https://docs.bazel.build/versions/master/tutorial/cpp.html
二、bazel 构建一个C++项目
下载示例代码
首先,找个位置,创建一个文件夹用于存放下载的代码,依次执行下面命令:
# 创建一个目录
mkdir ~/wwy-dir
# 进入这个目录
cd ~/wwy-dir
然后,从 github 上下载官方提供的示例代码,执行下面命令:
git clone https://github.com/bazelbuild/examples/
下载完成以后,就会在当前目录下,得到一个名为 examples 的文件夹:

这个项目有 C++、java、android、java-maven等示例,我们进入 C++ 项目的示例:
cd examples/cpp-tutorial/
你可以通过 tree 命令(你还可以指定子目录层级,tree -L 2指定子目录为2),查看一下有哪些文件。下面是目录 examples/cpp-tutorial/ 中的内容:
├── README.md
├── stage1
│ ├── main
│ │ ├── BUILD
│ │ └── hello-world.cc
│ ├── README.md
│ └── WORKSPACE
├── stage2
│ ├── main
│ │ ├── BUILD
│ │ ├── hello-greet.cc
│ │ ├── hello-greet.h
│ │ └── hello-world.cc
│ ├── README.md
│ └── WORKSPACE
└── stage3
├── lib
│ ├── BUILD
│ ├── hello-time.cc
│ └── hello-time.h
├── main
│ ├── BUILD
│ ├── hello-greet.cc
│ ├── hello-greet.h
│ └── hello-world.cc
├── README.md
└── WORKSPACE
上面 stage1、stage2、stage3 是三个示例,是三个独立的工程项目(三个工程之间没有直接关系)。示例 stage1 演示了一个简单的 C++ 程序,示例 stage2 演示了一个 .cc 文件需要引用另一个 .cc 文件的情况,示例 stage3 演示了一个 .cc 文件和 main 程序不在同一个目录下的情况(一个在 main 目录,一个在 lib 目录)。其中,以下几点比较重要:
- WORKSPACE : 工作空间,在项目工程的根(root)目录下,有个
WORKSPACE文件,表示这是一个工程项目。比如,stage1 目录下有一个WORKSPACE文件,说明这个目录下有一个完整的工程项目。- BUILD :
BUILD文件,这个文件会告诉 bazel 如何编译 .cc 源文件,限定多个源文件之间的关系。工作空间中的可能有多个文件夹,每个目录有代码的源文件和BUILD文件,这些有BUILD文件的文件夹,被称为 包(pakege)。
Bazel 去编译构建一个项目(project)时,所有的输入文件和依赖文件,都应该要求在同一个工作空间(WORKSPACE)中。 虽然可以使用某种链接方式,达到使用其它工作空间的文件的目的,但一般不这么使用。
简单认识 BUILD 文件
BUILD 文件包含了一系列不同类型的指令,Bazel 工具执行这些指令,来构建和编译我们的目标(target):
你可能会问:什么是目标target?target 就是你想生成的东西,比如使用源代码生成二进制可执行文件,这个可执行文件就是target。当然,target 还可以是一些 .o中间文件、lib 库文件等等。
BUILD 文件中,最重要命令的就是 构建规则(build rule),它告诉 Bazel 如何去创建和生成我们的目标。比如 cpp-tutorial/stage1/main 目录下的 BUILD 文件,内容如下:
cc_binary(
name = "hello-world",
srcs = ["hello-world.cc"],
)
上面规则中, hello-world 就是 目标target, hello-world.cc 就是 依赖文件,意思就是说,使用 hello-world.cc 文件,编译生成一个我们想要的名为 hello-world 的可执行文件。虽然生成的目标文件 hello-world ,这个命名你可以随意起,但是,我们一般会命名成和源文件名称一致的名字。比如源文件是 srcs = [xxx.cc],那么生成的文件就命名为 xxx 即可。
编译工程
接下来,我们先来尝试编译一个简单的工程。进入 cpp-tutorial/stage1 这个目录,并执行下面命令:
bazel build //main:hello-world
//main: 是相对路径,相对于工作区间 workspace 的根目录的路径。hello-world 是目标target,Bazel工具使用 main 目录下 BUILD 这个文件指定的编译规则,来编译生成目标。编译过程,会打印下面信息:
INFO: Found 1 target...
Target //main:hello-world up-to-date:
bazel-bin/main/hello-world
INFO: Elapsed time: 3.756s, Critical Path: 0.45s
INFO: 2 processes: 2 linux-sandbox.
INFO: Build completed successfully, 6 total actions
恭喜你!第一次使用 Bazel 成功编译了你的项目。这是,项目空间的根目录下,生成目录 bazel-bin ,这个目录中,包含有刚才编译生成的目标:

上图中,bazel- 开头的文件,是编译过程中,bazel 生成的中间文件目标文件。我们来执行一些目标文件:
bazel-bin/main/hello-world
这时,就会运行可执行程序 hello-world ,打印结果如下:

查看依赖关系图
有时你想知道,目标是依赖哪些文件生成的呢?你除了查看 BUILD 文件以外,还可以使用 bazel 工具查看。比如执行下面命令:
bazel query --nohost_deps --noimplicit_deps 'deps(//main:hello-world)' \
--output graph
deps(//main:hello-world) 说的是查看 //main:hello-world 这个目标的依赖关系。--output graph 指定输出格式为图的格式。打印结果如下:
INFO: Invocation ID: 661d04c1-f7f1-4419-a54c-afa1ba9619b4
digraph mygraph {
node [shape=box];
"//main:hello-world"
"//main:hello-world" -> "//main:hello-world.cc"
"//main:hello-world.cc"
}
其中,出去 INFO 中的提示类信息,下面的内容描述的是一个图:
digraph mygraph {
node [shape=box];
"//main:hello-world"
"//main:hello-world" -> "//main:hello-world.cc"
"//main:hello-world.cc"
}
可以将上面这个代码,粘贴到网页版的 Graphviz 中:

然后点击 Generate Graph 这个图标按钮,生成图,//main:hello-world 指向 //main:hello-world.cc, 说明 //main:hello-world 的生成依赖于 //main:hello-world.cc 。对应 ubuntu 用户来说,还可以安装 Graphviz 客户端,执行下面命令安装:
sudo apt update && sudo apt install graphviz xdot
然后使用 graphviz 客户端软件直接在本地显示,执行下面命令:
xdot <(bazel query --nohost_deps --noimplicit_deps 'deps(//main:hello-world)' \
--output graph)
显示效果是一样的,如下:

编译多个目标
在上面的示例中,我们只有一个 .cc 源文件,但我们项目开发中,一般会有多个 .cc 源文件。下面,将演示如何编译多个 .cc 源文件这种情况。先进入示例 stage2 工程目录下:
cd cpp-tuorial/stage2
可以查看该项目下 main 文件夹下的 BUILD 文件,内容如下:
cc_library(
name = "hello-greet",
srcs = ["hello-greet.cc"],
hdrs = ["hello-greet.h"],
)
cc_binary(
name = "hello-world",
srcs = ["hello-world.cc"],
deps = [
":hello-greet",
],
)
上面的 BUILD 脚本,Bazel 会先编译 hello-greet 这个目标,这个目标是一个 C++ 的 lib 库文件(使用 bazel 内建规则 cc_library rule 来生成这个lib)。然后,Bazel 再编译 hello-world 这个目标,这个目标是一个二进制可执行文件。deps 这个属性,告诉 Bazel 编译 hello-world 时,需要用到 hello-greet 这个目标,也就是 hello-world 的生成需要依赖(dependencies) hello-greet 。执行下面命令来编译 stage2 这个工程:
bazel build //main:hello-world
编译完成以后,和刚才的示例 stage1 一样,可以尝试执行一下生成的二进制文件:
bazel-bin/main/hello-world
打印结果如下:
Hello world
Wed Dec 19 03:19:53 2018
如果这时候,你去修改 hello-greet.cc 这个源文件,那么,bazel 只会重新编译 ``hello-greet.cc` 这个文件,其它文件不会被重新编译。其中:
# build 经常被简称为编译,其实是包含了很多步骤:编译、链接等。
# c++ 语言编译过程大致如下:
# - 编译(compile): .cc文件编译生成.o文件。
# - 链接(link): 将所有.o文件链接生成二进制可执行文件。
其实就是如果你 bazel build 编译过一次,就会生成中间缓存文件(.o 文件和其它文件),然后将这些中间文件链接生成最终的二进制可执行文件,这个可执行文件就是我们想要生成的最终的目标。等你下次编译的时候,只会编译你修改过的文件,其它缓存文件不变,最终再次链接这些缓存文件,生成新的最终目标。这么做,就得到了这样一个目的:
编译生成缓存文件的时间比较长,不需要生成缓存文件,节约了编译时间。这样缩减了整个 build 过程的时间,提高构建效率。
同样,执行下面命令,我们可以查看一下依赖关系图:
xdot <(bazel query --nohost_deps --noimplicit_deps 'deps(//main:hello-world)' \
--output graph)
结果如下:

从中可以看出,生成 hello-world 这个目标,需要依赖一个 hello-world.cc 源文件和一个 hello-greet 目标。这种增量式的构建方式,方便我们往项目中添加新的源文件,达到源文件分离、目标分离的效果,减少耦合。
使用多个包
上面,我们讲的是使用多个目标。那么,包(package)又是什么玩意?我们可以看示例 stage3 ,来理解什么是包。示例 stage3 的文件结构如下:
└──stage3
├── main
│ ├── BUILD
│ ├── hello-world.cc
│ ├── hello-greet.cc
│ └── hello-greet.h
├── lib
│ ├── BUILD
│ ├── hello-time.cc
│ └── hello-time.h
└── WORKSPACE
因为目录 stage 下,有两个子目录 main 和 lib,而且子目录内都包含了 BUILD 文件,因此, main 和 lib 被称为 包(package) ,它们是项目 stage3 的两个包。前面 stage1 和 stage2 两个项目中,源文件都在一个目录下,引入包的概念以后,源文件可以在项目空间中的不同目录下。可以看一下 lib/BUILD 这个文件的内容:
cc_library(
name = "hello-time",
srcs = ["hello-time.cc"],
hdrs = ["hello-time.h"],
visibility = ["//main:__pkg__"],
)
以及 main/BUILD 文件中的内容:
cc_library(
name = "hello-greet",
srcs = ["hello-greet.cc"],
hdrs = ["hello-greet.h"],
)
cc_binary(
name = "hello-world",
srcs = ["hello-world.cc"],
deps = [
":hello-greet",
"//lib:hello-time",
],
)
你可以看到,hello-world 这个 target 在 package main 中,需要依赖 target hello-time ,但是 hello-time 这个 target 在 package lib 中。默认情况下,target 只在同一个 BUILD 中有效,其它 BUILD 不可见,也就是无法使用。为了让其它 package 下的 target 也能使用,那么,只需加上 visibility 即可。比如上面的 visibility = ["//main:__pkg__"] 就是告诉 Bazel ,hello-time 这个 target ,main 这个包可以看到,这样 hello-world 就可以使用 hello-time 这个target 了。这就好比:
'''
下面打个形象的比喻:
张三、李四、王五各自家中有一些好吃的。张三拿出他家的红枣给李四看,
并说,李四你可以吃我家的红枣,这时李四才能吃张三家的红枣,至于李四吃
不吃,又是另一回事。同时,张三没有说让王五吃他家红枣,连看都不让王五
看,王五当然吃不到张三家的红枣啦。
'''
这样,每个 package 目录下有一个自己的 BUILD,既可以做到相互独立,也可以做到相互调用,减少耦合,利用维护。你同样可以通过下面命令编译项目 stage3 :
bazel build //main:hello-world
编译完成以后,执行生成的二进制可执行文件:
bazel-bin/main/hello-world
还可以通过下面指令,查看依赖关系图:
xdot <(bazel query --nohost_deps --noimplicit_deps 'deps(//main:hello-world)' \
--output graph)
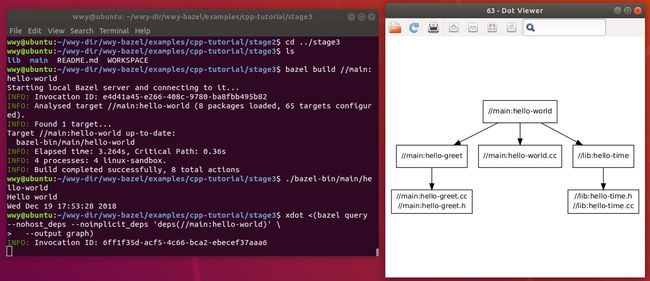
在目标中使用标签
所谓标签,其实就是 路径 + 目标 。在使用命令 bazel build //main:hello-world 和 BUILD 文件中 //main:hello-world ,以及 //lib:hello-time 。其中 //main: 和 //lib: 都是包的相对路径,相对于项目空间的根目录的路径。在命令 bazel build target,如果其中 target 这个目标是一个需要编译的目标,那么这个目标所在的目录下,要有一个 BUILD 脚本,而且这个target 在 BUILD 脚本中要有,名称相同。比如,上面 bazel build //main:hello-world 中的目标 //main:hello-world,在 main/BUILD 中有相应的 target name = hello-world ,两者 hello-world 这个名字一致。
如果 target 和当前 BUILD 脚本在同一个 package 中(其实就是在同一个目录下),那么路径可以不写,比如 : //:hello-world 。如果是在同一个 BUILD 脚本中,可以更简洁一些,这么写 :hello-world 。
三、小 结
至此,我们完成了 C++ 编译的基本操作。