
Python爬虫涉及的库有:请求库,解析库,存储库,工具库
01 请求库: urllib、re、requests、Selenium
Urllib、re是自带的库,而requests库可使用pip3 install requests安装
>>> import urllib
>>> import urllib.request
>>> import re
pip3 install requests
>>> import requests
>>> requests.get('http://www.baidu.com')
selenium JS渲染时使用的库
Selenium 是为了测试而出生的. 但是没想到到了爬虫的年代, 它摇身一变, 变成了爬虫的好工具. 让我试着用一句话来概括 Seleninm: 它能控制你的浏览器, 有模有样地学人类”看”网页.
pip3 install selenium
import selenium
from selenium import webdriver
driver = webdriver.Chrome() #执行报错,原因是没有安装Chromedriver

打开谷歌搜索Chromedriver,第一个就是,点击Chromedriver2.41


继续点击Chromedriver2.41

找到对应平台即可下载:
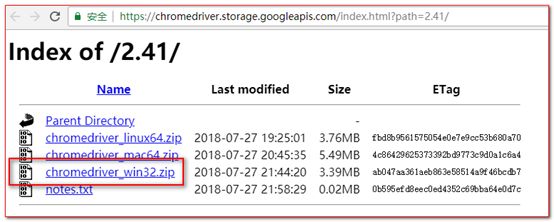
即以下地址:https://chromedriver.storage.googleapis.com/index.html?path=2.41/
下载下来以后将其解压,然后放到自己Python环境变量\Scripts\目录下即可。例如我的路径为:C:\Users\Administrator\AppData\Local\Programs\Python\Python36\Scripts\
打开CMD输入chromedrive回车
C:\Users\Administrator>chromedriver #出现如下提示信息
Starting ChromeDriver 2.41.578737 (49da6702b16031c40d63e5618de03a32ff6c197e) on port 9515
Only local connections are allowed.
^C
>>>from selenium import webdriver
>>>driver = webdriver.Chrome() #执行报错,有可能是由于谷歌版本与chromedriver不相符,如无报错,即可打开浏览器
>>> driver.get('http://www.baidu.com')
>>> driver.get('http://www.zhihu.com')
>>> driver.get('http://www.jianshu.com')
>>> driver.get('https://www.python.org') #即可打开相应的网站
>>> driver.page_source #打印网页源代码

#打印出jianshu源代码

Phantomjs(无界面浏览器)
pip3 install phantomjs
官网:http://phantomjs.org/download.html

https://bitbucket.org/ariya/phantomjs/downloads/
下载下来需要配置环境变量,然后即可完成代码编写!
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\Scripts\phantomjs-2.1.1-windows\bin
C:\Users\Administrator>phantomjs
phantomjs> console.log('hello,world!')
hello,world!
undefined
phantomjs>
02 解析库:lxml、beautifulsoup4、 pyquery
pip3 install lxml
或者从https://pypi.python.org下载,例如,lxml-4.1.1-cp36-cp36m-win_amd64.whl (md5) ,先下载whl文件
pip3 install 文件名.whl
pip3 install beautifulsoup4
pip3 install lxml pyquery
C:\Users\Administrator>pip3 install pyquery
Collecting pyquery
Downloading https://files.pythonhosted.org/packages/09/c7/ce8c9c37ab8ff8337faad3335c088d60bed4a35a4bed33a64f0e64fbcf29/pyquery-1.4.0-py2.py3-none-any.whl
Collecting cssselect>0.7.9 (from pyquery)
Downloading https://files.pythonhosted.org/packages/7b/44/25b7283e50585f0b4156960691d951b05d061abf4a714078393e51929b30/cssselect-1.0.3-py2.py3-none-any.whl
Requirement already satisfied: lxml>=2.1 in c:\users\administrator\appdata\local\programs\python\python36\lib\site-packages (from pyquery) (4.2.4)
Installing collected packages: cssselect, pyquery
Successfully installed cssselect-1.0.3 pyquery-1.4.0
03 存储库:pymysql、 pymongo、redis(分布式爬虫,维护爬取队列)相应的数据库均已安装
打开CMD直接输入:
pip3 install pymysql


pip3 install pymongo

pip3 install redis
redis数据库安装及使用前面一篇文档已经介绍,这里不在展开介绍,如有问题可移步《redis数据库安装》
04 工具库: flask、Django、jupyter
flask(WEB库) Django(分布式爬虫维护系统) jupyter(运行在网页端的记事本,支持markdown,可以在网页上运行代码)
pip3 install flask
pip3 install Django
pip3 install jupyter

此三个工具库在后期使用过程中在做介绍,这里不在展开介绍。
Python爬虫所使用的库基本上就这么几种,若有其他问题欢迎小伙伴一起交流学习哦!
▼
往期精彩回顾
▼
(端午节福利)各大影视VIP解析视频观看方法
Windows激活破解以及office安装破解
Windows10系统盘清理实用攻略
Windows环境下Python3安装
2018年比特币重现江湖
Redis数据库安装
欢迎关注此公众号,您的关注将是我后期不断输出的源泉,点击最上方蓝字或者长按下方二维码关注我吧!如果觉得此文对您有帮助,欢迎点赞、分享、转发!
