hadoop环境搭建,初始如果只有一台可用server虚拟机可单台搭建hdfs环境。生产环境hdfs环境大都采用基于zookeeper实现的高可用集群环境搭建。
机器环境:
10.176.2.101 master
10.176.2.103 zjx03
10.176.2.105 zjx05
hadoop集群准备工作:
主机名设置(三台机器均修改好需要的主机名,根据上篇大数据平台环境搭建准备做过的不用再做)
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=zjx05
需要进行切换用户生效:
su - root
也可百度下设置用户名和密码,另外需要将进行网络通信的主机名与ip加入/etc/hosts 。这里面配置的是其它主机的ip与主机名的映射,由此才可以通过主机名进行访问。
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.176.2.101 master
10.176.2.103 zjx03
10.176.2.105 zjx05
10.176.2.111 yjy11
10.176.2.113 yjy13
10.176.2.115 yjy15
可以使用主机名进行测试:
ssh master date
用户名创建(另两台机器也创建,用户创建生产环境需要创建,此处该步骤省略,均使用root用户)
useradd -u 8000 hadoop
echo '123456' | passwd --stdin hadoop
给hadoop用户增加sudo权限,增加内容(另外两台主机上都得配置)
vim /etc/sudoers
hadoop ALL=(ALL) ALL
主机互信(集群环境必备)
如果之前没有生成过私钥与秘钥,使用下一个步骤生成私钥与密钥,生成文件在家目录下,此处在目录/root/.ssh下
ssh-keygen -t rsa
cd /root/.ssh
ls
ls看到会有公钥与私钥文件:
id_rsa id_rsa.pub (其中id_rsa是私钥,id_rsa.pub是公钥)
cp id_rsa.pub authorized_keys (拷贝一个文件,注意此处是公钥id_rsa.pub文件)
上述在另两台机器上同样进行生成生成authorized_keys。
ssh 10.176.2.101 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh 10.176.2.103 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh 10.176.2.105 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
该操作类似于使用ssh-copy-id root命令操作
出于安全性考虑,将这个授权key文件赋予600权限:
chmod 600 ~/.ssh/authorized_keys
将这个包含了所有互信机器认证key的认证文件,分发到各个机器中去
scp ~/.ssh/authorized_keys 10.176.2.103:~/.ssh/
scp ~/.ssh/authorized_keys 10.176.2.105:~/.ssh/
验证互信,各节点执行下面命令,能不输入密码显示时间,配置成功
ssh 10.176.2.101 date;ssh 10.176.2.103 date;ssh 10.176.2.105 date;
检测成功,上述将authorized_keys分发复制到其它机器上也可以使用脚本(后续多台集群可以参考,此处可暂不用)
vi bulkcp.sh
#! /bin/bash
for((i=101;i<=105;i=i+2))
do
scp -r $1 10.176.2.$i:$2
echo scp -r $1 10.176.2.$i:$2
done
./bulkcp.sh ~/.ssh ~/.ssh
可参考:
https://www.cnblogs.com/jyzhao/p/3781072.html
关闭防火墙
service iptables stop(关闭)
chkconfig iptables off (永久关闭,使用永久关闭,三台机器均操作)
service iptables status
可参考:
https://www.cnblogs.com/maybo/p/5250668.html
重启网络服务
service network restart
jdk安装
考虑安装hadoop(2.7版本),此处使用jdk8,经测兼容
下载jdk1.8oracle官网,1.8.191版本,将tar.gz包jdk1.8.0_191.tar.gz上传至/usr/lib/java/目录下,此处目录任意,为了方便管理上传至此目录。
解压
tar -zxvf jdk1.8.0_191.tar.gz
配置环境变量(环境变量配置,配置环境很常用,建议记住)
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin
刷新环境变量(记住该命令刷新环境变量)
source /etc/profile
将其拷贝至其它机器:
scp -r /usr/lib/java/jdk1.8.0_191 zjx03:/usr/lib/java/
scp -r /usr/lib/java/jdk1.8.0_191 zjx05:/usr/lib/java/
拷贝至另两台机器后也要类似配置环境变量然后source /etc/profile
hadoop相关下载地址:
zookeeper下载
http://archive.apache.org/dist/hadoop/zookeeper/
cdh版本下载
http://archive-primary.cloudera.com/cdh5/cdh/5/
apache hadoop版本:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
hadoop版本下载:
http://central.maven.org/maven2/org/apache/hadoop/
可以配置源下载安装更便捷
hadoop安装配置
mkdir -p /opt/softwares (用于后续存放zookeeper、hadoop等包)
下载好的zookeepertar.gz包上传至该目录(上传至此目录不放家目录是由于开始本人linux虚拟机家目录下分区只有2g):
zookeeper版本:zookeeper-3.4.5-cdh5.12.2
tar -zxvf zookeeper-3.4.5-cdh5.12.2.tar.gz
hadoop版本:hadoop-2.7.7
tar -zxvf hadoop-2.7.7.tar.gz
rm -rf zookeeper-3.4.5-cdh5.12.2.tar.gz
rm -rf hadoop-2.7.7.tar.gz (删除tar.gz包节约空间)
cd /opt/softwares/hadoop-2.7.7
cd share/
rm -rf doc/ (删除不必要的文件 一般是windows下的说明文件,节省空间)
cd ..
cd etc/
cd hadoop/
rm -rf *.cmd
1.单机版hadoop环境搭建
单机版搭建参考如下链接,可以直接看第3部分基于zookeeper的hadoop环境搭建如下配置,只是配置文件内容有所差异,单机版相对更容易搭建
https://www.cnblogs.com/dulixiaoqiao/p/6939818.html
2.hadoop三台集群搭建(未使用zookeeper实现高可用集群搭建)
参考下篇,该搭建较好,也主要是配置文件差异,三者主要是对Secondary的高可用实现机制差异,推荐看第三种基于zookeeper的hadoop集群环境搭建(完整安装):
https://www.cnblogs.com/winter1519/p/10201142.html
3.基于zookeeper的hadoop集群环境搭建
安装配置zookeeper
cd /opt/softwares/zookeeper-3.4.5-cdh5.12.2/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
# dataDir=/tmp/zookeeper
#下述新增在注释的dataDir后面
dataDir=/opt/softwares/zookeeper-3.4.5-cdh5.12.2/zkData
# 下述server配置放在该文件最末
server.1=master:2888:3888
server.2=zjx03:2888:3888
server.3=zjx05:2888:3888
dataDir=/opt/softwares/zookeeper-3.4.5-cdh5.12.2/zkData 这个下面是myid文件,必须这样写,最后的添加2888端口是leader和flower之间通信的端口,3888端口是flower之间选举的端口。
mkdir /opt/softwares/zookeeper-3.4.5-cdh5.12.2/zkData
touch /opt/softwares/zookeeper-3.4.5-cdh5.12.2/zkData/myid
echo 1 > /opt/softwares/zookeeper-3.4.5-cdh5.12.2/zkData/myid
myid中的值和server.1,server.2,server.3中的对应应分别按照机器写入1,2,3),创建的文件夹zkData存储zookeeper产生的数据(类似后续hadoop配置中创建的tmp文件夹,此处也可以创建为tmp)
将配置好的zookeeper拷贝到其它节点
scp -r /opt/softwares/zookeeper-3.4.5-cdh5.12.2 zjx03:/opt/softwares/
scp -r /opt/softwares/zookeeper-3.4.5-cdh5.12.2 zjx05:/opt/softwares/
修改zjx03、zjx05机器节点上对应的myid
zjx03:
echo 2 > /opt/softwares/zookeeper-3.4.5-cdh5.12.2/zkData/myid
zjx05:
echo 3 > /opt/softwares/zookeeper-3.4.5-cdh5.12.2/zkData/myid
启动zookeeper
cd /opt/softwares/zookeeper-3.4.5-cdh5.12.2/bin
./zkServer.sh start
./zkServer.sh status
后续停止zookeeper为./zkServer.sh stop
由于安装于本机测试使用,每次需要停止集群(生产环境一般不会停止集群,只会对单个宕机的节点进行启动修复),此处将zookpeer配置环境变量,方便启动,同样对另两台进行同样配置
vim /etc/profile
export ZOOKEEPER_HOME=/opt/softwares/zookeeper-3.4.5-cdh5.12.2
export PATH=$ZOOKEEPER_HOME/bin:$PATH
source /etc/profile
启动zookeeper
zkServer.sh start
查看zookeeper状态
zkServer.sh status
停止zookeeper
zkServer.sh stop
安装配置hadoop
配置hdfs(hadoop2.x所有的配置文件都在HADOOP_HOME/etc/hadoop目录下)
配置环境变量
vim /etc/profile
export HADOOP_HOME=/opt/softwares/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
安装配置
cd /opt/softwares/hadoop-2.7.7/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_191
vim core-site.xml
fs.defaultFS
hdfs://ns1
hadoop.tmp.dir
/opt/softwares/hadoop-2.7.7/data/tmp
ha.zookeeper.quorum
master:2181,zjx03:2181,zjx05:2181
vim hdfs-site.xml
dfs.nameservices
ns1
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
master:9000
dfs.namenode.http-address.ns1.nn1
master:50070
dfs.namenode.rpc-address.ns1.nn2
zjx03:9000
dfs.namenode.http-address.ns1.nn2
zjx03:50070
dfs.namenode.shared.edits.dir
qjournal://master:8485;zjx03:8485;zjx05:8485/ns1
dfs.journalnode.edits.dir
/opt/softwares/hadoop-2.7.7/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.permissions
false
vim mapred-site.xml
mapreduce.framework.name
yarn
vim yarn-env.xml
export JAVA_HOME=/usr/lib/java/jdk1.8.0_191
vim yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
master
yarn.resourcemanager.hostname.rm2
zjx03
yarn.resourcemanager.zk-address
master:2181,zjx03:2181,zjx05:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
vim slaves (用于指定集群在网络中的主机节点有那些)
master
zjx03
zjx05
将配置好的hadoop拷贝到其他节点
scp -r /opt/softwares/hadoop-2.7.7 zjx03:/opt/softwares/
scp -r /opt/softwares/hadoop-2.7.7 zjx05:/opt/softwares/
配置完成,启动,先启动zookeeper(三台机器均启动zookeeper,此时查看zookeeper状态会有leader与flower节点),再启动hdfs
zkServer.sh start (三台均启动)
启动验证效果
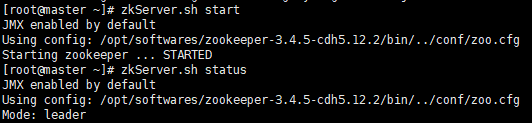
hadoop-daemons.sh start journalnode (三台均启)
格式化hdfs(只需要格式化一次,后续启动集群不用再格式化,不要格式化多次,多次格式化会造成namenodeId不一致,需要删除/opt/softwares/hadoop-2.7.7/data/tmp/下所有文件重新格式化才不报错)
hdfs namenode -format
首次格式化后/opt/softwares/hadoop-2.7.7/data/tmp下的文件复制到另外两个节点对应目录下
scp -r /opt/softwares/hadoop-2.7.7/data/tmp zjx03:/opt/softwares/hadoop-2.7.7/data/
scp -r /opt/softwares/hadoop-2.7.7/data/tmp zjx05:/opt/softwares/hadoop-2.7.7/data/
格式化ZK(在master上执行,若不能启动结点再在其他机器上执行,作用是协助namenode进行高可靠,向zookeeper汇报)
hdfs zkfc -formatZK (同样只需要格式化一次)
启动zk
hadoop-daemon.sh start zkfc
启动HDFS(master上执行)
start-dfs.sh
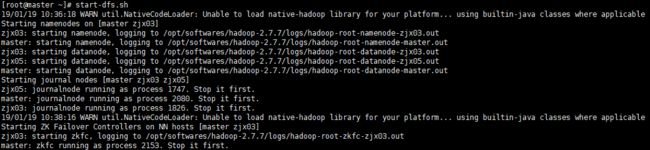
启动YARN(zjx03上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,分开了就要分别在不同的机器上启动)
start-yarn.sh

启动后效果如下:
jps查看集群进程如下
[root@master ~]# jps
2080 JournalNode
2417 DataNode
2982 Jps
2153 DFSZKFailoverController
2841 NodeManager
2313 NameNode
1994 QuorumPeerMain
[root@zjx03 ~]# jps
2289 ResourceManager
2145 DFSZKFailoverController
1826 JournalNode
1909 NameNode
1978 DataNode
2556 Jps
2397 NodeManager
1774 QuorumPeerMain
[root@zjx05 ~]# jps
1985 NodeManager
1747 JournalNode
1637 QuorumPeerMain
1829 DataNode
2118 Jps
页面监测:
http://10.176.2.101:50070
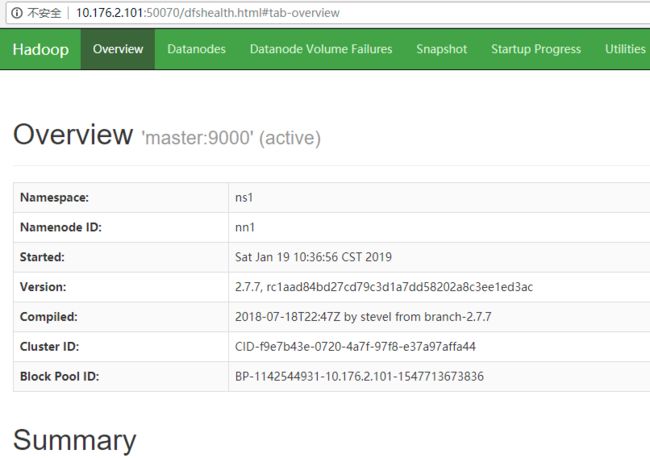
http://10.176.2.103:50070
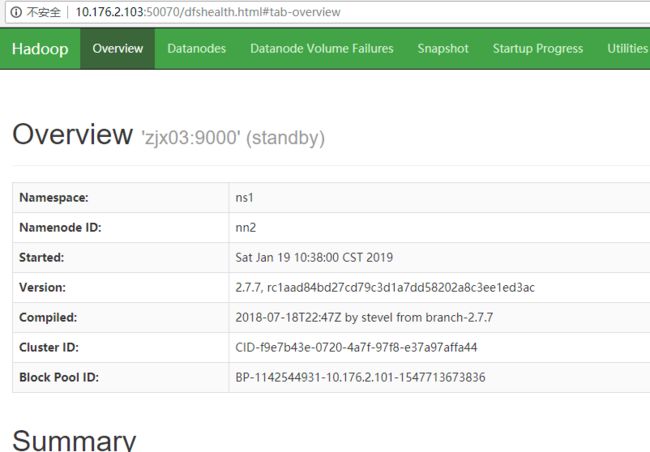
hadoop 总有警告解决办法:
vim /opt/softwares/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
hdfs与mapreduce测试
[root@master tmp]# hadoop fs -mkdir -p /tmp/zhoujixiang
[root@master tmp]# hadoop fs -ls /tmp/
[root@master tmp]# hdfs dfs -ls /tmp/
[root@master tmp]# cd /opt/softwares/hadoop-2.7.7/data/tmp
[root@master tmp]# touch test.txt
[root@master tmp]# vim test.txt
[root@master tmp]# hadoop fs -put ./test.txt /tmp/zhoujixiang/
19/01/19 11:56:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@master tmp]# hadoop fs -ls /tmp/zhoujixiang
19/01/19 11:57:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 3 root supergroup 78 2019-01-19 11:56 /tmp/zhoujixiang/test.txt
[root@master tmp]# hadoop fs -cat /tmp/zhoujixiang/*
hello hadoop
hello hdfs
hello zookeeper
hello mapreduce
hello hdfs mapreduce
[root@master mapreduce]# hadoop fs -mkdir -p /tmp/zhoujixiang/input
[root@master mapreduce]# hadoop fs -mv /tmp/zhoujixiang/test.txt /tmp/zhoujixiang/input/
[root@master mapreduce]# hadoop fs -ls /tmp/zhoujixiang/input/
[root@master mapreduce]# hadoop jar /opt/softwares/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /tmp/zhoujixiang/input/test.txt /tmp/zhoujixiang/output/
[root@master mapreduce]# hadoop fs -cat /tmp/zhoujixiang/output/*
hadoop 1
hdfs 2
hello 5
mapreduce 2
zookeeper 1
[root@master mapreduce]# yarn application -list
至此已经安装配置okay,且做了简单练习,各位老板看到这里辛苦了!
经过安装练习,结合hadoop架构,从而更好了解其整个架构体系,包括从2.x的secondNameNode交给zookeeper集群管理,zookeeper的管理架构(zkfc、quoru)。
后续启动hdfs集群顺序如下:
zkServer.sh start (三台均启)
hadoop-daemons.sh start journalnode (三台均启)
hadoop-daemon.sh start zkfc (master上启动即可)
start-dfs.sh (master上启动即可)
start-yarn.sh (zjx03节点启动,非主节点启动)
后续停止集群停止顺序与启动顺序相反:
stop-yarn.sh (zjx03节点停止,在启动节点上停止)
stop-dfs.sh (master节点停止,在启动节点上停止,停止后其它server均停,除过zkServer)
zkServer.sh stop(三台均停)
参考链接:
https://blog.csdn.net/a1275302036/article/details/75268862
https://blog.csdn.net/qq_30003943/article/details/83788377
不足之处还望指正,谢谢 Q:1098077157