一.主题式网络爬虫设计方案
1.主题式网络爬虫的名称
链家网站的爬取
2·主题式网络爬虫的内容与数据特征分析
爬虫的内容:
房源信息的名称,小区名称,价格,楼层,代理人,单价,发布时间。
数据特征分析:
对楼层做一个词云并可视化;对发布时间做一个折线图
3,主题式网络爬虫设计方案概述(包括实现思路和技术难点)
实现思路:
创建一个get的类,定义get_alldata()方法用来获取网页上的全部信息,get_detail()方法用来对整数数据的进一步加工和提取,再用字典把数据存储起来。
技术难点:
网站会有反爬取机制,需要模拟用户操作进行爬取。
二,主题页面的结构特征分析
1,主题页面的特征结构
每页30项数据,爬取了50页,数据量为1500条。通过F12查看网页源代码分析需要提取的数据是否存在动态生成的数据,任意查看一个数据项中与原网页中的数据对比后,发现所需要爬取的数据都是静态的。
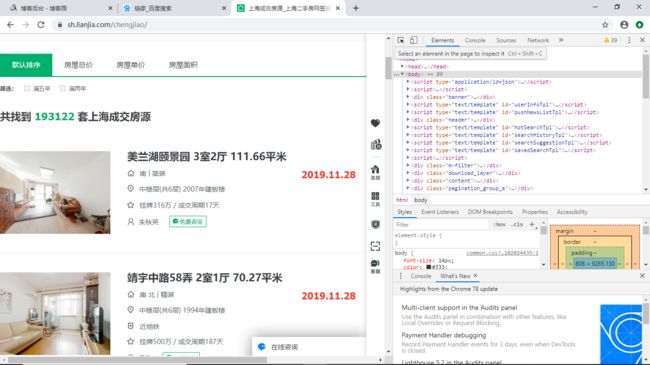
2,HTML页面解析
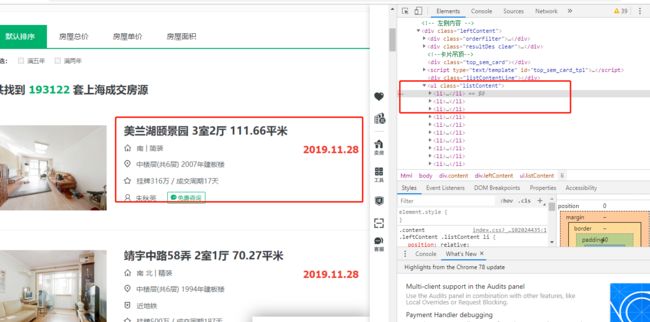
方框内都是要爬取的内容
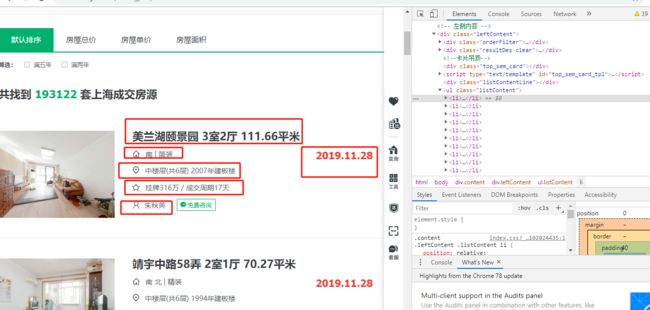
三,网络爬虫程序设计
1,爬虫程序主题要包括以下部分,要附源代码及较详解注释,并在每部分程序后面提供输出结果的截图。
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
import seaborn as sns
#固定url
url_title = "https://sh.lianjia.com/chengjiao/pg"
url_end = "/"
Total_Data = {}
#获取全部的网址信息
class Get:
#获取所有url
def get_url(self):
list1 = []
#取50个
for i in range(0,51):
url = url_title+str(i)+url_end#拼接参数得到完整的url
list1.append(url)
return list1
#解析出网页
def get_alldata(self,url):
#user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
#headers = {'User-Agent': user_agent}
#data = requests.get(url,headers=headers)
data = requests.get(url)
soup = BeautifulSoup(data.text,'lxml')
return soup
#获取title等,并存入字典
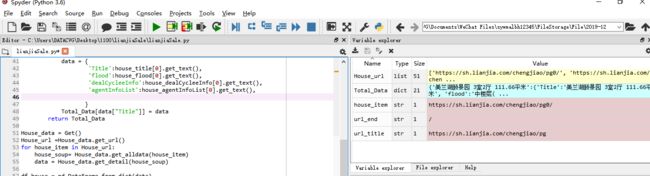
def get_detail(self,soup):
for i in range(0,30):
data1 = soup.select('div[class="info"]')[i]
house_title =data1.find_all("div",class_="title")
house_flood =data1.find_all("div",class_="flood")
house_dealCycleeInfo = data1.find_all("div",class_="dealCycleeInfo")
house_agentInfoList = data1.find_all("div",class_="agentInfoList")
data = {
'Title':house_title[0].get_text(),
'flood':house_flood[0].get_text(),
'dealCycleeInfo':house_dealCycleeInfo[0].get_text(),
'agentInfoList':house_agentInfoList[0].get_text(),
}
Total_Data[data["Title"]] = data
return Total_Data
House_data = Get()
House_url =House_data.get_url()
for house_item in House_url:
house_soup= House_data.get_alldata(house_item)
data = House_data.get_detail(house_soup)
df_house = pd.DataFrame.from_dict(data)
df_house = df_house.T#转置
df_house.index=range(len(df_house))#reindex
#====================================================
#数据清洗
df_house['agent']=df_house['agentInfoList'].apply(lambda x:x.split("免费")[0])
del df_house['agentInfoList']
df_house['price'] = df_house['dealCycleeInfo'].apply(lambda x:x.split("成交")[0]).apply(lambda x:x.split("挂牌")[1])
df_house['time'] = df_house['dealCycleeInfo'].apply(lambda x:x.split("成交")[-1]).apply(lambda x:x.split("周期")[-1])
del df_house['dealCycleeInfo']
df_house['floor']=df_house['flood'].apply(lambda x:x.split(' ')[0])
df_house['floor']=df_house['flood'].apply(lambda x:x.split(' ')[0])
df_house['unitprice']=df_house['flood'].apply(lambda x:x.split(' ')[-1]).apply(lambda x:x.split("楼")[-1])
del df_house['flood']
df_house['time']=df_house['time'].apply(lambda x:x.split("天")[0])
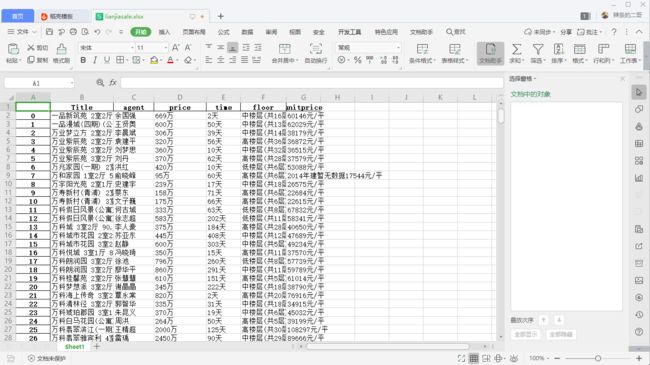
writer = pd.ExcelWriter(r'C:\Users\DATACVG\Desktop\1100\lianjiasale.xlsx')
df_house.to_excel(r'C:\Users\DATACVG\Desktop\1100\lianjiasale.xlsx')
#词云
cut_text = "".join(df_house['floor'])
wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1000,height=880).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
cut_text = "".join(df_house['agent'])
wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1000,height=880).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
#=================================================
#数据可视化
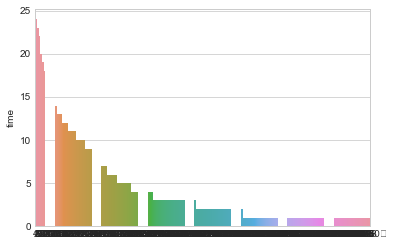
#柱状图
s =df_house['time'].value_counts()
sns.barplot(x=s.index,y=s)
运行过程如下
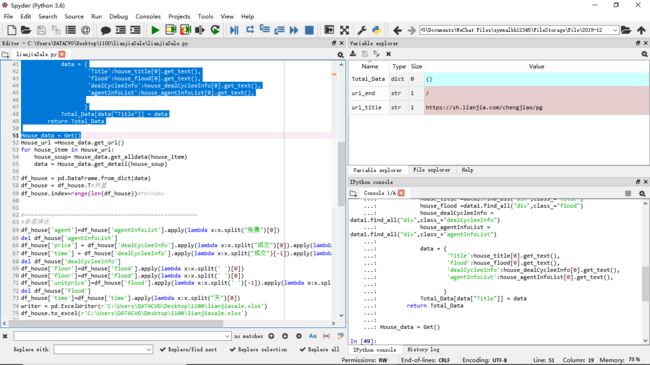
数据清洗
df_house['agent']=df_house['agentInfoList'].apply(lambda x:x.split("免费")[0])
del df_house['agentInfoList']
df_house['price'] = df_house['dealCycleeInfo'].apply(lambda x:x.split("成交")[0]).apply(lambda x:x.split("挂牌")[1])
df_house['time'] = df_house['dealCycleeInfo'].apply(lambda x:x.split("成交")[-1]).apply(lambda x:x.split("周期")[-1])
del df_house['dealCycleeInfo']
df_house['floor']=df_house['flood'].apply(lambda x:x.split(' ')[0])
df_house['floor']=df_house['flood'].apply(lambda x:x.split(' ')[0])
df_house['unitprice']=df_house['flood'].apply(lambda x:x.split(' ')[-1]).apply(lambda x:x.split("楼")[-1])
del df_house['flood']
df_house['time']=df_house['time'].apply(lambda x:x.split("天")[0])
writer = pd.ExcelWriter(r'C:\Users\DATACVG\Desktop\1100\lianjiasale.xlsx')
df_house.to_excel(r'C:\Users\DATACVG\Desktop\1100\lianjiasale.xlsx')
#词云
cut_text = "".join(df_house['fitment'])
wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1000,height=880).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
cut_text = "".join(df_house['roomnum'])
wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1000,height=880).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
#=================================================
#数据可视化
#柱状图
s =df_house['follow'].value_counts()
sns.barplot(x=s.index,y=s)
#3.文本分析(可选):jieba分词、wordcloud可视化
#4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
#词云
cut_text = "".join(df_house['floor'])
wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1000,height=880).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
#=================================================
#数据可视化
#柱状图
s =df_house['time'].value_counts()
sns.barplot(x=s.index,y=s)

5.数据持久化
写入csv文件
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
结论一:单价低的房子更容易卖出。
结论二:代理人对房子的销售影响很大。
结论三:客户更倾向于中层的房子。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次的爬取对本课程有了更加深度的认识,在网上看视频一步一步的学习最后终于完成了本次爬取(链家房屋成交的影响因素),通过对网络数据采集以及对大数据分析让我们更好更清楚的看到我们想要的数据。还需继续学习有待进步。
--------------------------------------------------------------------------------------------------------------------------------------------------------
代码:
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
import seaborn as sns
#固定url
url_title = "https://sh.lianjia.com/chengjiao/pg"
url_end = "/"
Total_Data = {}
#获取全部的网址信息
class Get:
#获取所有url
def get_url(self):
list1 = []
#取50个
for i in range(0,51):
url = url_title+str(i)+url_end#拼接参数得到完整的url
list1.append(url)
return list1
#解析出网页
def get_alldata(self,url):
#user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
#headers = {'User-Agent': user_agent}
#data = requests.get(url,headers=headers)
data = requests.get(url)
soup = BeautifulSoup(data.text,'lxml')
return soup
#获取title等,并存入字典
def get_detail(self,soup):
for i in range(0,30):
data1 = soup.select('div[class="info"]')[i]
house_title =data1.find_all("div",class_="title")
house_flood =data1.find_all("div",class_="flood")
house_dealCycleeInfo = data1.find_all("div",class_="dealCycleeInfo")
house_agentInfoList = data1.find_all("div",class_="agentInfoList")
data = {
'Title':house_title[0].get_text(),
'flood':house_flood[0].get_text(),
'dealCycleeInfo':house_dealCycleeInfo[0].get_text(),
'agentInfoList':house_agentInfoList[0].get_text(),
}
Total_Data[data["Title"]] = data
return Total_Data
House_data = Get()
House_url =House_data.get_url()
for house_item in House_url:
house_soup= House_data.get_alldata(house_item)
data = House_data.get_detail(house_soup)
df_house = pd.DataFrame.from_dict(data)
df_house = df_house.T#转置
df_house.index=range(len(df_house))#reindex
#====================================================
#数据清洗
df_house['agent']=df_house['agentInfoList'].apply(lambda x:x.split("免费")[0])
del df_house['agentInfoList']
df_house['price'] = df_house['dealCycleeInfo'].apply(lambda x:x.split("成交")[0]).apply(lambda x:x.split("挂牌")[1])
df_house['time'] = df_house['dealCycleeInfo'].apply(lambda x:x.split("成交")[-1]).apply(lambda x:x.split("周期")[-1])
del df_house['dealCycleeInfo']
df_house['floor']=df_house['flood'].apply(lambda x:x.split(' ')[0])
df_house['floor']=df_house['flood'].apply(lambda x:x.split(' ')[0])
df_house['unitprice']=df_house['flood'].apply(lambda x:x.split(' ')[-1]).apply(lambda x:x.split("楼")[-1])
del df_house['flood']
df_house['time']=df_house['time'].apply(lambda x:x.split("天")[0])
writer = pd.ExcelWriter(r'C:\Users\DATACVG\Desktop\1100\lianjiasale.xlsx')
df_house.to_excel(r'C:\Users\DATACVG\Desktop\1100\lianjiasale.xlsx')
#词云
cut_text = "".join(df_house['floor'])
wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1000,height=880).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
cut_text = "".join(df_house['agent'])
wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1000,height=880).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
#=================================================
#数据可视化
#柱状图
s =df_house['time'].value_counts()
sns.barplot(x=s.index,y=s)
#折线图