前言
最近工作中遇到了Electronic Health Record (EHR) 的数据,由于EHR是个很杂很乱的数据,一般来说Deep learning会在这个地方用的比较多,除开deep learning的话可能就是些传统的人工、或者伪机器学习之类的。这里看到一篇比较好的综述般的博客,这里记录一下其中的内容。
电子病历(EHR)
电子病历是一个种类繁多的混乱的数据。其中包括了账单数据、病人信息、药物史、临床诊断、生化检测、用药、理化数据、扫描数据、保险等等的数据,当然不一定所有的EHR都会囊括这里面的所有种类。

应用前景
数据与应用是脱离不开的两个东西,从Deep learning开始风靡的时候开始,已经有很多很多的人对电子病历这一块下手,毕竟电子病历一直是一个储存为主,利用为辅的东西,而又有着非常庞大的数据体量。所以自然有很多已有的模型与文章结合EHR与deep learning。
其中电子病历的应用分为很多,但其中围绕的三个主题还是信息提取(Information Extraction),表征学习(Representing Learning)、临床预测(Clincial Prediction)。

表征学习(Representing Learning)
表征学习其实在日常生活中或者说在电子病历中早就有很多类似的东西,例如说ICD code、问卷、复杂的表格等等,这些都是在以前,整个医疗系统的设计者所意识到的,电子病历中存在的一个很大的问题,也就是信息的冗余。
患者的数量是远远大于疾病的种类数目的,所以说很多的病症的描述或者用药等等在一个EHR系统中,往往都是冗余的,冗余的信息在数据储存、使用、查询上都是一些很大的问题。于是开始使用一些方案,从而达到保存信息,减少冗余的目的。
因为我们表征学习后的数据是要输入一个数学模型的,所以这里,我们也把表征学习叫做向量化。
One-Hot encoding
One-Hot encoding是一种较为原始地、成熟的方法,主要是面对多分类的变量,它将这个变量转化为一个二分类的变量。

但这种方法一方面 增加了数据的维度,把单一的特征拆分成了多个特征。
另一方面仅仅 保留了最简单的是/否的信息。
所以使用的局限性还是很大。
基于分布的嵌入(Distributed Embeddings)
这个名字和这个翻译我也是有很多槽是想吐的,但是也没办法。。。
基于分布的一些别的方法可能还有像是tf-idf、word count之类的,主要都是统计词的出现频率,也就是基于分布的一种向量化的方法了。
但如果加上了Embedding...事情顿时就变得比较复杂了起来。。。
比较简单模型叫做Skip-Gram,这个从别的角度来说也是个十分简单容易理解的模型,只不过加上了神经网络的成分。
简单理解部分:
如果只统计一个词的频率保留的信息太简单,那么不如将左右的词合并一起计算?例如中国人,中国与人就经常放一起,完全可以用一个词而不是字的方式去统计。
简单理解如上,那么如何实现呢。。。这里不多讲,篇幅有限。但是其实Skip-Gram还有一个别的说法,叫n-Gram,就是保留左右多少个字。其实从这个参数就可以看出这个方法的局限性。既然要设定n,意味这个方法很受n的局限,甚至,不同的数据的这个n也不一样。
而它的好处呢,就是可以保留词的信息,而不是字。但EHR的很多数据毕竟不是一个结构化、顺序明确的句子,所以这个方法也很受局限。

也有别的比较特别的方法,例如Choi et al.,他不适用药物或者结果层面的信息,选择更高一层,以病人为单位。将每个病人的信息用二元向量表示,然后再将binary vector放入一个两层神经网络,其中可以加入人体测量学的数据,并加入左右两个不同病人的数据。从而学习得到一个embedding后的向量。
想法上比较独特,但是本质上还是属于Skip-gram的一种。

除了以上的方法,表征学习的方法自然还包括了很多其它的方法,其中有以下几种 GloVe, CBOW or stacked autoencoders or attention model
Embedding 的用法方面大致有三种
- 完全跳过向量化的步骤,用监督学习的方式,使用随机生成的向量训练整个模型以生成向量 。(会造成过拟合)
- 部分数据用以训练,剩下的数据生成向量。
- 全部数据用以生成向量。
信息提取(Information Extraction)
EHR中的数据类型正如前文所说,十分的混杂混乱,其中不仅有结构化规整好的数据,也有不少医生自身的笔记、救护车记录、授权同意书细节、用药步骤等等充满了个人主观色彩的语句,完全都可以算是NLP(Natural language processing)领域中常常遇到的问题了。
那么面对如此的数据时,第一时间应该做的自然就是信息提取。如果不讨论各种成本,使用人工的方法自然是最为简单快捷的方案,但是如果面对海量的PB级的数据时,人工的方法就变得耗时耗力又容易出错、无法追溯了。所以开发机器学习处理的方法自然比较迫切。
当然其中有不少的的非机器学习的方法也比较有效,例如使用自动分隔项目-结果数值的Valx,也有专门识别阴性/阳性结果的NegEx。
除开这些小工具以外,神经网络也有不少针对这个方向的方法。
实体识别(Entriry recognition)
在自然语言处理中,语音语义识别是一个研究的重点,而其中最为著名的自然是RNN(递归神经网络),由于EHR的这部分文档的书写者自然是人类,面向的主体一致,数据一致,所以RNN的移植也就理所当然。
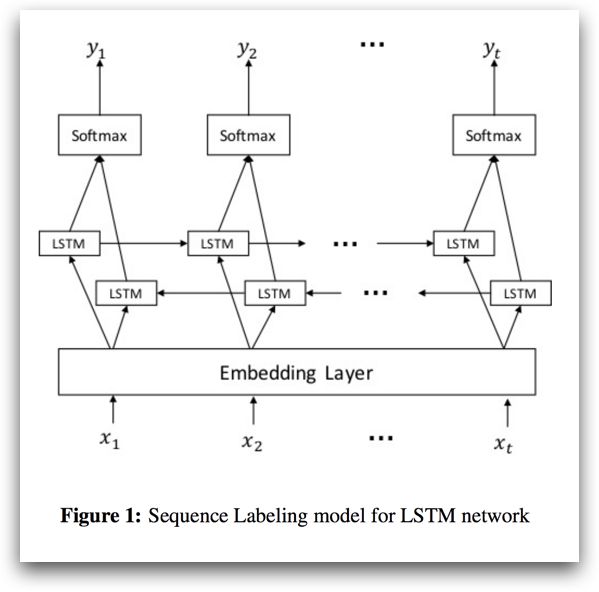
Long short-term memory (LSTM)因为能够处理较长文档中,词与词之间的关联关系,所以备受瞩目。但是缺点则是需要较大的数据量,才能使模型学习到足够的特征以训练数据。
后来Xing et al.使用语言建模(类似于迁移学习)的方式去识别EHR中的各种实体。
1.使用双向语言建模的方法预训练该模型的权值。(相较于随机生成的权值更为有效。)
- 然后再用预训练好的模型与LSTM进行学习。

临床预测(Clinical predictions)
处理好复杂数据的表征学习/向量化之后,当然要利用得到的干净的、结构化的数据进行训练、预测。通过以往的EHR,从而对现有的病人进行预测与干预,从而治疗好病人才是最终的目的。
比较典型的例子就是综合疾病ID、病人体征、检测数据等,使用并预测一个人得某种疾病的概率(属于静态的预测)。
当然更多的场景发生在,一系列的input从而得到一个或者多个的输出,较为简单的例子则为developed Doctor AI ,使用一个来诊病人的ICD码以及持续时间来预测下一个ICD码的概率和持续时间。由于疾病之间是存在一定的关联性的,这在主观上来说也没什么问题。

除了疾病ID这些数据以外,还有别的种类的数据同样的可以用来进行预测。
临床记录
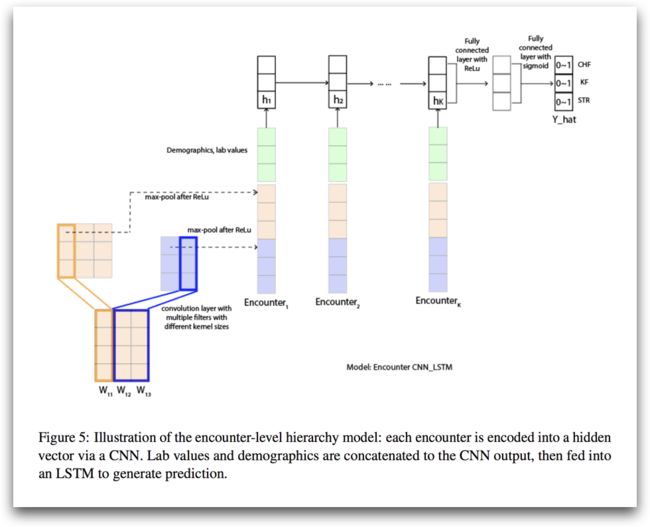
临床记录应该是最为接近医生的主观判断的数据了,里面可以详细的看到医生的诊断、病人的病情等等的数据,也是糅合了最多医生主观诊断的数据。虽然因为记录的主观性太强,导致数据难以结构化、规整、向量化。但仍有人朝着这个方向努力, Liu et al.使用CNN和RNN的模型,预测在一定时间内病人的发病概率。
- 使用医学杂志上的摘要进行Skip-Gram模型学习,并用以向量化数据集。
- 利用CNN不同的一维卷积核对临床数据进行卷积,池化后,与体征数据、监测数据连接,并input进入LSTM模型
- LSTM则负责记录、关联1000个input以内的长时、短时关联等
- 最终获得预测结果
贡献的可视化
由于这个模型中LSTM的input是一个类似于时间序列的东西,并且学习后具有不同的权值。于是最终可以可视化成如下容易理解与解释的结果。
 Noisy results from the gradient based approach.
Noisy results from the gradient based approach.
时序数据(Time-series data)
临床记录是个信息量十分巨大的文本数据,而除开文本数据这样的数据分类标准,还有一个在医院中或者说日常生活中十分常见的数据也就是时序数据。在医院中,这个类型的数据往往是由各种各样的体征监测设备产生。这也带来了易于处理、结构化的好处,而坏处往往则是太大了,太多了。。。。
同样地,这里讨论神经网络中使用时序数据的文章。
Gotlibovych et al.使用时序数据(光测量心房体积大数据)来监测心房颤动。而且也很巧合的一样是使用了卷积和递归联用的模型去处理。
- 规整对其时序数据到合适的区间,并使用CNN进行处理。从中提取信息并降低维度
- CNN的输出作为LSTM的输入,最后使用sigmoid激活函数得到心房颤动的预测概率。

医学影像(Medical scans)
最后则是不同于时序、文本数据的一类数据----图像数据。医学影像学从诞生开始就为医生深入了解病人不同病灶的时空状态提供了非常有利的工具,而在深度学习出来之前,计算机技术对医学影像学的作用也仅仅作为一个工具的作用,还远远达不到诊断或者辅助诊断的作用。
自从有了深度学习以后,CNN这种从一开始就是针对图像数据的模型在各个领域起着不同的作用。对于医学影像学而言,虽然还不能如医生一样以图像数据进行诊断。但可以起着不同于医生的作用,例如诊断分类、肿瘤边界识别等等
在以上的临床预测中,几乎大部分的模型与方法都应用在了这个方面,而且几乎所有的模型与方法都在逐渐的强调可解释度(interpretability )。
除开以上的这三个主要领域,还有很多比较新的领域。
新兴的领域
- 关系提取 Relationship extraction
从EHR中找到一些内在的潜藏的关系,从而补充或者验证一些医学知识。- 生成采样 Generative sampling
EHR中也有一个特点,也是医学领域的数据的普遍特点。也就是数据量的bias,罕见病毕竟在少数,而且不同的疾病的记录数也不一样。如何用随机生成模型模拟数据,是该领域的主要问题- 多任务学习 Multitask learning
该领域主要针对跨领域的有监督模型,同一个模型会有主要的任务与辅助的任务,其中辅助的任务可能与主要的任务为不同的领域,但是其中会有潜藏的关系可以相互的帮助提高预测能力- 推荐系统 Recommendation systems
推荐系统对网上冲浪的人们就很常见了,例如百度、谷歌等搜索引擎,或者淘宝、京东这些网上购物平台。而在医学上呢,推荐系统更像是精准治疗。通过模型的学习和微调,改善已有的、固有的干预手段,从而达到对不同疾病阶段、不同体征病人的更好的治疗效果。- 反事实推理 Counterfactual reasoning
反事实推理这个就很顾名思义了。。。我就不说些啥了。。。
告辞。。。原文还是很好的,虽然不深入,但是广度还是在的,如果是一个对神经网络有一定了解的人是一个很好的读物。而一个对神经网络不是很了解的医学生之类的呢,也是可以有很好的一个全局的概览,可以了解与计算机领域能合作些什么。
参考资料
goku blog EHR
原文附录
EHR data sources
De-identified (to preserve privacy) EHR datasets:
- Medical Information Mart for Intensive Care III (MIMIC-III)
- Stanford Medicine Research Data Repository (STARR)
- Informatics for Integrating Biology & the Bedside (i2b2) - clinical notes only
Auxiliary datasets:
- International Statistical Classification of Diseases and Related Health Problems (ICD) - diagnosis codes
- Current Procedural Terminology (CPT) - medical procedure codes
- Logical Observation Identifiers Names and Codes (LOINC) - laboratory codes
- RxNorm - medication codes