1. 五种主流的大数据架构
1.1 传统大数据架构
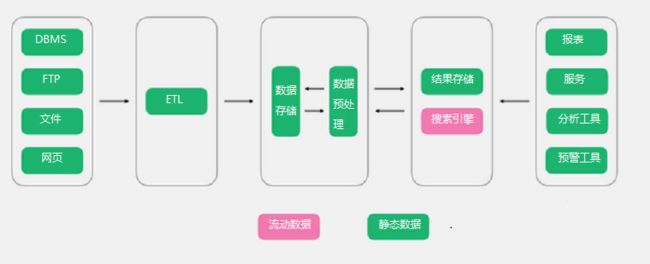
之所以叫传统大数据架构,是因为其定位是为了解决传统BI的问题,简单来说,数据分析的业务没有发生任何变化,但是因为数据量、性能等问题导致系统无法正常使用,需要进行升级改造,那么此类架构便是为了解决这个问题。可以看到,其依然保留了ETL的动作,将数据经过ETL动作进入数据存储。
优点:简单,易懂,对于BI系统来说,基本思想没有发生变化,变化的仅仅是技术选型,用大数据架构替换掉BI的组件。
缺点:对于大数据来说,没有BI下如此完备的Cube架构,虽然目前有kylin,但是kylin的局限性非常明显,远远没有BI下的Cube的灵活度和稳定度,因此对业务支撑灵活度不够,所以对于存在大量报表,或者复杂的钻取的场景,需要太多的手工定制化,同时该架构依旧以批处理为主,缺乏实时的支撑。
适用场景:数据分析需求依旧以BI场景为主,但是因为数据量、性能等问题无法满足日常使用。
1.2 流式架构
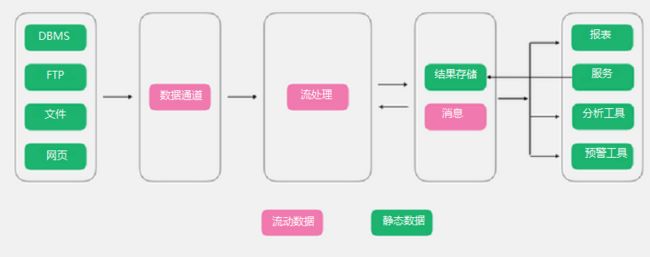
在传统大数据架构的基础上,流式架构非常激进,直接拔掉了批处理,数据全程以流的形式处理,所以在数据接入端没有了ETL,转而替换为数据通道。经过流处理加工后的数据,以消息的形式直接推送给了消费者。虽然有一个存储部分,但是该存储更多的以窗口的形式进行存储,所以该存储并非发生在数据湖,而是在外围系统。
优点:没有臃肿的ETL过程,数据的实效性非常高。
缺点:对于流式架构来说,不存在批处理,因此对于数据的重播和历史统计无法很好的支撑。对于离线分析仅仅支撑窗口之内的分析。
适用场景:预警,监控,对数据有有效期要求的情况
1.3 Lambda架构
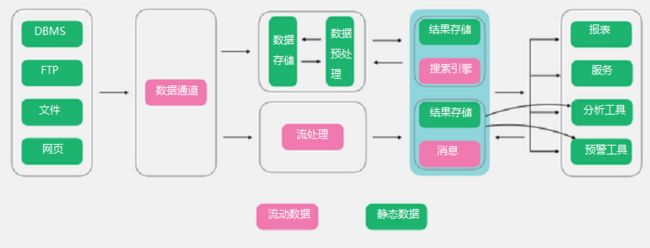
Lambda架构算是大数据系统里面举足轻重的架构,大多数架构基本都是Lambda架构或者基于其变种的架构。Lambda的数据通道分为两条分支:实时流和离线。实时流依照流式架构,保障了其实时性,而离线则以批处理方式为主,保证了最终一致性。流式通道处理为保障实效性更多的以增量计算为主辅助参考,而批处理层则对数据进行全量运算,保障其最终的一致性,因此Lambda最外层有一个实时层和离线层合并的动作,此动作是Lambda里非常重要的一个动作,大概的合并思路如下:
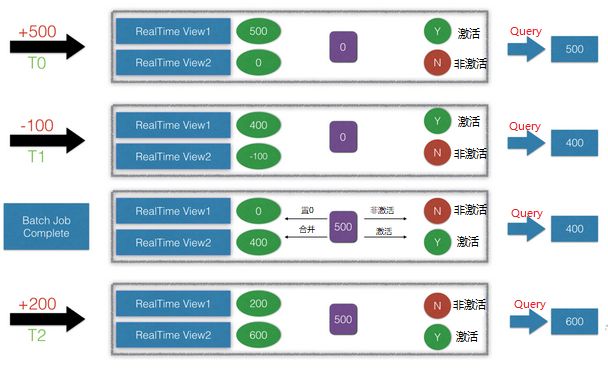
优点:既有实时又有离线,对于数据分析场景涵盖的非常到位。
缺点:离线层和实时流虽然面临的场景不同,但是其内部处理的逻辑却是相同,因此有大量荣誉和重复的模块存在。
适用场景:同时存在实时和离线需求的情况。
1.4 Kappa架构
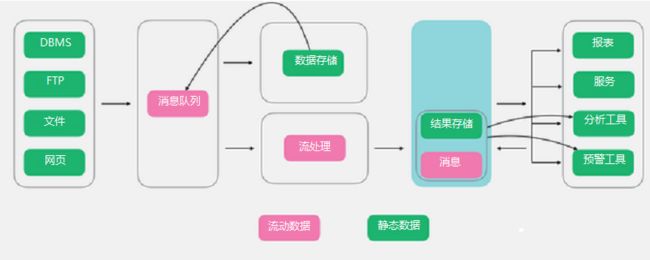
Kappa架构在Lambda的基础上进行了优化,将实时和流部分进行了合并,将数据通道以消息队列进行替代。因此对于Kappa架构来说,依旧以流处理为主,但是数据却在数据湖层面进行了存储,当需要进行离线分析或者再次计算的时候,则将数据湖的数据再次经过消息队列重播一次即可。
优点:Kappa架构解决了Lambda架构里面的冗余部分,以数据可重播的超凡脱俗的思想进行了设计,整个架构非常简洁。
缺点:虽然Kappa架构看起来简洁,但是实施难度相对较高,尤其是对于数据重播部分。
使用场景:和Lambda类似,改架构是针对Lambda的优化。
1.5 Unifield架构
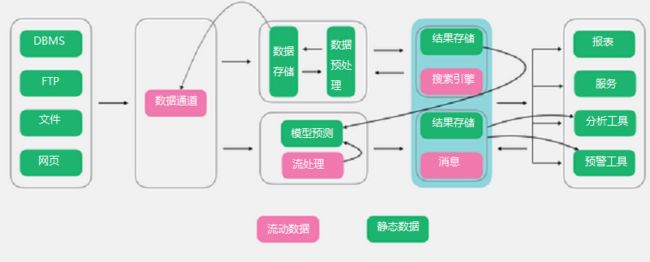
以上的种种架构都围绕海量数据处理为主,Unifield架构则更激进,将机器学习和数据处理揉为一体,从核心上来说,Unifield依旧以Lambda为主,不过对其进行了改造,在流处理层新增了机器学习层。可以看到数据在经过数据通道进入数据湖后,新增了模型训练部分,并且将其在流式层进行使用。同时流式层不单使用模型,也包含着对模型的持续训练。
优点:Unifield架构提供了一套数据分析和机器学习结合的架构方案,非常好的解决了机器学习如何与数据平台进行结合的问题。
缺点:Unifield架构实施复杂度更高,对于机器学习架构来说,从软件包到硬件部署都和数据分析平台有着非常大的差别,因此在实施过程中的难度系数更高。
适用场景:有着大量数据需要分析,同时对机器学习方便又有着非常大的需求或者有规划。
2. 收集各大互联网公司大数据平台架构
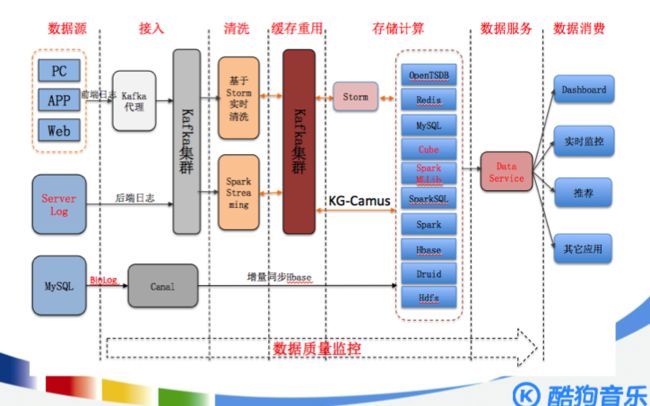
1. 酷狗音乐的大数据平台架构:
https://www.infoq.cn/article/kugou-big-data-platform-restructure
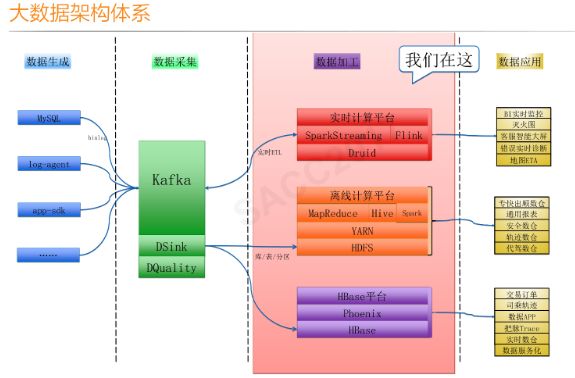
2. 滴滴大数据离线和实时平台架构和实践:
https://myslide.cn/slides/15307
3. 美图大数据平台lamda架构:
https://www.infoq.cn/article/QycsTZSz0REAFTgmh_J0
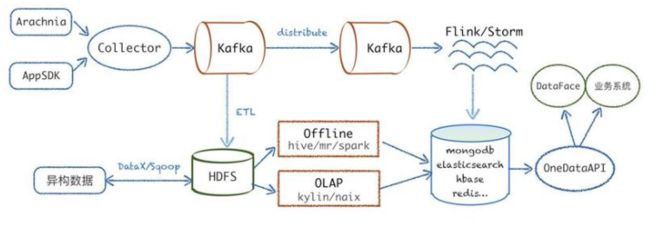
持续更新中......
【参考资料】
https://blog.csdn.net/scgyus/article/details/82259316