ELK
Elasticsearch
基本概念
NRT--Near Real Time
近实时:你对文档进行索引到你能对其进行查询的延时很短(一般是1s)
Cluster--集群
拥有你全量数据并提供索引存储和查询功能的一个或多个es服务节点。
Node--服务节点
服务节点是一台集群中的服务器,为集群提供索引和查询能力。
Index--索引
索引是一个拥有类似特征的文档的集合。
Document--文档
文档是一个可被索引的信息的基本单元。
Shards & Replicas--分区和复制
安装ES
yum
# step1 下载rpm包
# step2 yum install
具体可参考官方。
docker
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.2.4 包含xpack
docker pull docker.elastic.co/elasticsearch/elasticsearch-platinum:6.2.4 包含xpack及30天试用证书
docker pull docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.4 不包含xpack
ES的关键配置
ES只需要很简单的配置即可开始使用,但在投入生产之前,官方建议我们仔细阅读如下配置:
Path Settings
如果用zip或tar包安装,那么数据和日志的文件夹是在$ES_HOME的子文件夹下,如果保持默认配置不变,这两个文件夹很有极大风险被删除。
path:
logs: /var/log/elasticsearch
data: /var/data/elasticsearch
Cluster names
ES会将所有有共同集群名称的服务节点加入集群。
需要注意不同的环境(测试、生产)的配置集群名的区分,否则就会出现不同环境的节点加入同个集群。
cluster.name: logging-prod
Node name
ES会使用随机生成的UUID的前七位作为node id。node id 是永久的并不会因为重启而改变,因此默认的node name也不会改变。
官方建议给出更有意义的命名方式。
node.name: prod-data-2
# 也可以设置为系统的HOSTNAME
node.name: ${HOSTNAME}
Network host
ES会使用回送地址(loopback addresses) 127.0.0.1 和 [::1]。对于单个开发节点来说,这样的配置就足够了。
但是为了集群的节点间通信呢,我们就需要指定一个非回送地址(non-loopback address):
network.host: 192.168.1.10
ES还可以识别其他的特殊值,详见这里。
Discovery settings
ES使用的是一种自定义的集群节点对节点和主从选举发现方式--“Zen Discovery“。这个发现方式有两个重要的配置项:
- discovery.zen.ping.unicast.hosts
在没有任何网络配置的情况下,ES会banding在回送地址并会不断扫描9300-9305端口来连接其他在同个服务器上的其他节点。
如果需要连接其他服务器的节点,则需要我们给出种子节ip地址。种子节点的ip地址可以用如下方式给出:
discovery.zen.ping.unicast.hosts:
- 192.168.1.10:9300
- 192.168.1.11 # 不指定端口会访问默认端口
- seeds.mydomain.com # 这个域名解析出的全部ip
- discovery.zen.minimum_master_nodes
为防止数据丢失,这个配置是非常重要的。有了这项配置,集群中的所有节点就知道选举主节点需要的最少参与节点数。如果没有这项配置,某个节点的网络错误会导致集群分成两个部分,从而导致数据丢失。关于集群分成两个部分,我们可以看这个更详细的描述,在这个更详细的描述中,官方建议集群配置最少需要三个主节点。
# 算法:(master_eligible_nodes / 2) + 1
# 如果我们有三个主节点,则我们需要配置最少2个。(3/2) + 1 = 2
discovery.zen.minimum_master_nodes: 2
Heap size
ES会默认配置1GB的最小/最大堆容量。当我们往生产环境迁移的时候,确保ES有足够的堆容量是很重要的一点。
官方给出如下建议:
- 将最小Xms和最大Xmx的对容量设置为相同数值。
- 为ES配置的对容量越大,ES可使用的缓存越大。需要指出的是,过大的对容量会导致很长的垃圾回收暂停。
- 设置Xmx的时候,不要超过物理RAM容量的50%来保证系统有足够的RAM来提供文件系统的缓存。
- 设置Xmx数值的时候,不要超过JVM为压缩对象指针的隔断。不同java版本的隔断不同,但都接近32GB。我们可以在ES的日志中找到如下这一行,确认一下这个数值:
heap size [1.9gb], compressed ordinary object pointers [true]
- 更好的做法是,我们可以试着将Xmx设置为低于 the threshold for zero-based compressed oops;在大部分系统这个值一般确定在26GB,有些系统是30GB。你可以在ES的启动时对其jvm参数多家两行:XX:+UnlockDiagnosticVMOptions -XX:+PrintCompressedOopsMode 在启动日志寻找如下两行:
heap address: 0x000000011be00000, size: 27648 MB, zero based Compressed Oops
heap address: 0x0000000118400000, size: 28672 MB, Compressed Oops with base: 0x00000001183ff000
PS:实验下来,使用docker启动ES, the cutoff that the JVM uses for compressed object pointers 跟the threshold for zero-based compressed oops这两个数值与docker容器中jvm.options中Xms和Xmx数值挂钩,与分配给docker容器的内存不相关。
Heap dump path
使用RMP和Debian包安装的ES服务,默认的堆转储文件会存放在/var/lib/elsaticsearch。如果这个路径不适合存储,你可以在jvm.options修改这个路径。
-XX:HeapDumpPath=/var/lib/elasticsearch
需要指出的是,使用打包好的ES(zip,tar)开启的ES服务,会将堆转储存在ES的工作目录下,如果你想换路径,需要修改jvm.options中# -XX:HeapDumpPath=/heap/dump/path 这一行。
GC logging
ES默认会开启GC logging。这个也是在jvm.options中配置,且与ES日志在相同路径。默认的日志每个文件64M,最多占用2GB磁盘空间。
LogStash
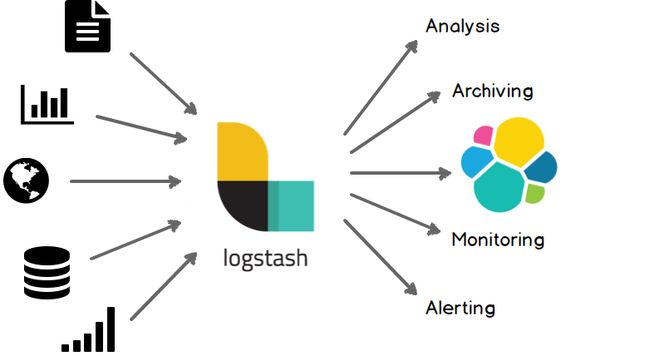
安装LogStash
https://www.elastic.co/guide/en/logstash/current/installing-logstash.html
基本概念
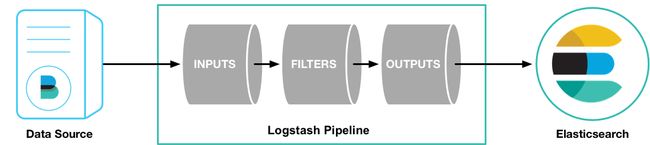
输入 input
- file:文件。从文件系统读取文件,类似命令
tail -0F - syslog:从514端口读取系统日志信息并且用RFC3164格式解析。
- redis:使用redis channels和redis lists读取redis 服务器内容。redis经常扮演“中间人”的角色,将远程的logstash事件按队列传输。
- beats:处理Filebeat传递的事件。
过滤 filter
- grok:对任意文本进行解析和重构。
- mutate:对事件中字段进行通用处理。
- drop:对一些事件直接丢弃,如debug事件。
- clone:对事件进行拷贝,可以添加或移除字段。
- geoip:根据ip地址获取地理位置信息。
输出 output
- elasticsearch:可以将事件直接传递给ES服务器。
- file:可以将事件写入磁盘文件。
- graphite:将事件传递给graphite。
- statsd:将事件传递给statsd。
解编码器 Codecs
- json:以json格式解编码。
- multiline:将多行文件(如java抛出的异常和堆栈信息)合并为单行事件。
一般用法
bin/logstash -f logstash-simple.conf
logstash-simple.conf一般格式
# 这里是注释
# 这里是输入描述
input {
...
}
# 这里是
filter {
...
}
output {
...
}
logstash-simple.conf样例
input {
beat {
port => "5044" # 暴露给filebeat端口,使用docker请记得将5044端口映射出去。
}
}
filter {
dissect {
mapping => {
"message" => "[%{req_msg}] %{ip} () {%{msg_body}} [%{ts} %{+ts} %{+ts} %{+ts} %{+ts}] %{method} %{uri} => %{generated_msg} (%{http_p} %{http_status}) %{other_message}"
}
}
mutate {
replace => {"ip"=> "112.64.179.50"}
}
geoip {
source => "ip"
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
Filebeat

filebeat设计原理如上图所示,主要由两个核心组件组成:Harvester和Prospector。
Harvester
Harvester主要负责读取单个文件的内容。
Prospector
Prospector主要负责管理Harvesters和寻找所有可以读取的源。
目前支持两种Prospector格式:log和stdin
如果格式为log,则filebeat会根据配置,读取全部满足条件的文件,每个文件一个Harvester。
安装Filebeat
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-installation.html
一般配置
日志路径
配置日志所在路径或者某个日志文件。可以使用*代表通配。
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
ES配置
如果希望直接将filebeat读取到的日志文件传输至ES,可以使用如下配置:
output.elasticsearch:
hosts: ["192.168.1.42:9200"]
kibana配置
如果想使用filebeat为kibana提供的dashboard模板,可以使用如下配置:
setup.kibana:
host: "localhost:5601"
配合logstash使用
注意:logstash和ES不能同时使用。
#----------------------------- Logstash output --------------------------------
output.logstash:
hosts: ["127.0.0.1:5044"]
设置filebeat dashboard
filebeat setup --dashboards
配置filebeat modules
一共有三种方法:
1、开启默认module配置:
在/etc/filebeat 路径下(centos7)有一个modules.d文件夹,该文件夹有所有默认模块的默认配置。默认模块包括:apache2、mysql、system等。可以使用modules enable或modules disable开启或关闭。
./filebeat modules enable apache2 mysql
查看支持的modules:
./filebeat modules list
2、在启动filebeat的时候开启:
./filebeat -e --modules nginx,mysql,system
3、在filebeat.yml配置:
可在filebeat.yml最后添加:
filebeat.modules:
- module: apache2
# Access logs
access:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/httpd/access_log*"]
# Prospector configuration (advanced). Any prospector configuration option
# can be added under this section.
#prospector:
# Error logs
error:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/httpd/error_log*"]
# Prospector configuration (advanced). Any prospector configuration option
# can be added under this section.
#prospector:
具体modules可参考:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-modules.html
Kibana
Kibana是一个开源、基于ES的分析和可视化平台。可以用存储好的数据指标在kibana上进行搜索、查看和互动。在kibana上,你还能对数据进行更进一步的分析并用图表、表格和地图的形式可视化呈现。
搭建kibana服务
安装
https://www.elastic.co/guide/en/kibana/current/install.html
配置
如需正常运行所需的最小配置:
# 任意ip均可访问
server.host: "0"
# 默认端口5601
server.port: 5601
# ES的url
elasticsearch.url: "http://localhost:9200"
其他配置可参考:https://www.elastic.co/guide/en/kibana/current/settings.html
简单使用
需要可视化或查询数据之前,需要在kibana中设置ES的index。
点击左侧边栏"Management"-->"Index Patterns"-->"Create Index Pattern"即可设置。
在kibana 6.x中,会显示ES中已有的index。用户可根据自己的需求,设置index的正则匹配规则,如:
logstash-*
logstash-6.2.4-*
随后便可在页面中,对指定的index进行查询或可视化操作了。
补充:lucene 查询语法
整体搭建流程
环境说明:
- centos7
- docker
ES
# 采用elasticsearch-oss的镜像,oss代表不包含xpack的镜像。xpack收费,提供管理、机器学习等模块。
docker run -itd --restart=always -p 9200:9200 -p 9300:9300 docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.4
将9200(数据交互、API交互端口) 9300(集群发现端口)暴露出来即可。
kibana
由于docker默认的kibana扫描的ES url为'http://elasticsearch.com:9200'
我采用docker build,将kibana.yml复制进docker镜像。
kibana.yml
# Kibana is served by a back end server. This setting specifies the port to use.
server.host: "0"
server.port: 5601
elasticsearch.url: "http://192.168.2.26:9200"
Dockerfile
FROM docker.elastic.co/kibana/kibana-oss:6.2.4
COPY kibana.yml /usr/share/kibana/config/kibana.yml
USER root
RUN chown kibana /usr/share/kibana/config/kibana.yml
USER kibana
Docker build & run
# 在Dockerfile所在文件夹运行
docker build -t kibana-custom:v1 .
# 随后
docker run -itd --restart=always -p 5601:5601 kibana-custom:v1
Logstash
# 配合filebeat使用。
# -e 后面的字符串大家也可以将其复制到.conf文件中 使用conf文件启动logstash。
docker run -it --rm -p 5044:5044 -p 9600:9600 docker.elastic.co/logstash/logstash-oss:6.2.4 -e 'input {beats {port => "5044"}} filter{ dissect {mapping => {"message" => "[%{req_msg}] %{ip} () {%{msg_body}} [%{ts} %{+ts} %{+ts} %{+ts} %{+ts}] %{method} %{uri} => %{generated_msg} (%{http_p} %{http_status}) %{other_message}"}} mutate {replace => {"ip"=> "61.244.37.240"}} geoip {source => "ip"}} output {elasticsearch {hosts => ["192.168.2.26:9200"]}}'
filebeat
filebeat 我采用yum安装。
具体配置可参考之前的配置方法。
在filebeat启动成功后,可看到有Harvester字样输出,即为配置成功。

这篇文章的Press.one签名:
https://press.one/file/v?s=3152ece53ee4f864fe4326ae2166f230d100a4629548ac0aef527cf2e48ea0976608dcb290c439a522a28f5db5ef05dcf3084496dbe2b1b1b53508500065e4760&h=c0f8f2fb26429366f05ddbf3c2230d8eb37e35cfab19a17a17630565813b17f4&a=866597c04655a093a3e1f31a317c7addd0df9123&f=P1&v=2