1、MongoDB概念解析:
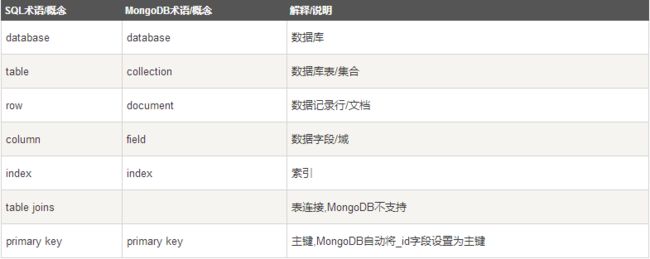
2、数据库:
"show dbs"命令可以显示所有数据的列表。
"db"命令可以显示当前数据库对象或集合。
"use"命令,可以连接到一个指定的数据库。
3、集合:
db.createCollection("mycoll", {capped:true, size:100000})
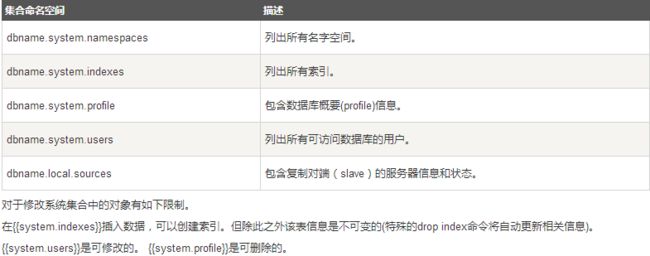
4、元数据:
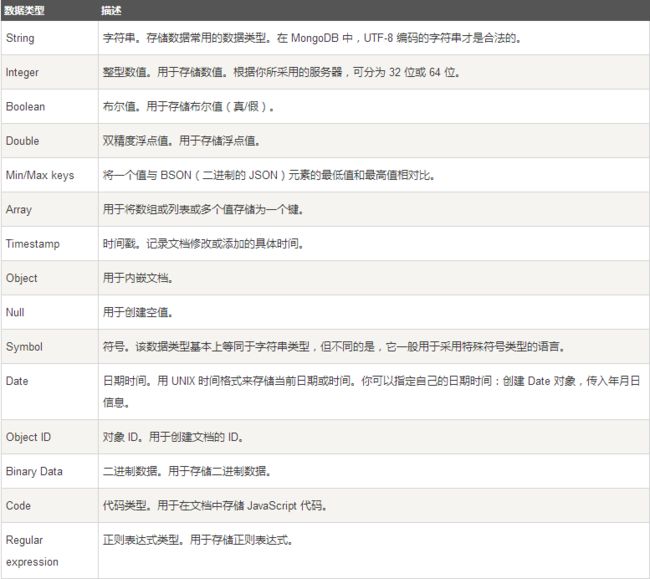
5、MongoDB数据类型:
ObjectId
 ObjectId
ObjectId
6、创建数据库:
use DATABASE_NAME
如果数据库不存在,则创建数据库,否则切换到指定数据库。
db.runoob.insert({"name":"菜鸟教程"})
集合只有在内容插入后才会创建
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
7、删除数据库:
db.dropDatabase()#默认删除test
db.collection.drop()#删除集合
-
例子
>use runoob switched to db runoob >show tables site >db.site.drop() true >show tables >
8、创建集合:
db.createCollection(name, options)
-
创建固定集合 mycol,整个集合空间大小 6142800 KB, 文档最大个数为 10000 个。
>db.createCollection("mycol", {capped: true, autoIndexId: true, size: 6142800, max: 10000}) -
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
>db.mycol2.insert({"name": "徐贝妮"}) >show collections mycol2
9、删除集合:
db.collection.drop()
#例子
db.mycol2.drop()
10、插入文档:
db.COLLECTION_NAME.insert(document)
#例子
>db.mycol.insert({title: 'MongoDB教程',
description: 'MongoDB是一个Nosql数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['MongoDB', 'database', 'NoSQL'],
likes: 100
})
-
查看已插入文档:
db.mycol.find() -
将数据定义成一个变量
> document=({title: 'MongoDB 教程', description: 'MongoDB 是一个 Nosql 数据库', by: '菜鸟教程', url: 'http://www.runoob.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }); >db.mycol.insert(document) >db.mycol.save(document)
11、更新文档:
-
update()方法
db.collection.update(, , { upsert: , multi: , writeConcern: } ) query : update的查询条件,类似sql update查询内where后面的。 update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的 upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。 multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。 writeConcern :可选,抛出异常的级别。 -
实例
#将标题“MongoDB教程”改为“MongoDB”。 >db.mycol.update({'title': 'MongoDB教程'}, {$set: {'title': 'MongoDB'}}) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息 >db.mycol.find().pretty() { "_id" : ObjectId("56064f89ade2f21f36b03136"), "title" : "MongoDB", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 } > >db.mycol.update({'title': 'MongoDB教程'}, {$set: {'title': 'MongoDB'}}, {multi: true}) -
save()方法
db.collection.save(, { writeConcern: } ) document : 文档数据。 writeConcern :可选,抛出异常的级别。 -
推荐使用
db.collection.updateOne() #更新单个文档 db.collection.updateMany() #更新多个文档
10、删除文档:
db.collection.remove(
,
{
justOne: ,
writeConcern:
}
)
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档。
writeConcern :(可选)抛出异常的级别。
-
实例
> db.col.find() { "_id" : ObjectId("56066169ade2f21f36b03137"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 } { "_id" : ObjectId("5606616dade2f21f36b03138"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 } #移除 >db.mycol.remove({'title': 'MongoDB 教程'}) WriteResult({ "nRemoved" : 2 }) # 删除了两条数据 #删除所有数据 >db.col.remove({}) >db.col.find() > -
推荐使用
>db.inventory.deleteMany({}) #删除全部文档 >db.inventory.deleteMany({status: 'A'}) #删除status=A的全部文档 >db.inventory.deleteOne({status: 'D'}) #删除status=D的一个文档
11、查询文档:
db.collection.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
-
易读的方式
>db.collection.find().pretty() #格式化显示所有文档 -
MongoDB与RDBMS where语句比较:

-
AND条件
>db.collection.find({key1: value1, key2: value2}).pretty() >db.mycol.find({'by': '菜鸟教程', 'title': 'MongoDB 教程'}).pretty() -
OR条件
>db.collection.find({$or: [{'by': '菜鸟教程'}, {'title': 'MongoDB 教程'}]}).pretty() -
AND和OR联合使用
>db.collection.find({'likes': {$gt: 50}, $or: [{'by': '菜鸟教程'}, {'title': 'MongoDB 教程'}]}).pretty() -
projection参数使用方法
#若不指定 projection,则默认返回所有键,指定 projection 格式如下,有两种模式 db.collection.find(query, {title: 1, by: 1}) // inclusion模式 指定返回的键,不返回其他键 db.collection.find(query, {title: 0, by: 0}) // exclusion模式 指定不返回的键,返回其他键
12、条件操作符:
(>) 大于 - $gt greater than
(<) 小于 - $lt less than
(>=) 大于等于 - $gte
-
(<= ) 小于等于 - $lte
db.collection.find({likes: {$gt: 100}}) #Select * from collection where likes >=100; db.collection.find({likes: {$lte: 150}}) -
模糊查询
#查询包含“教”字的文档 db.collection.find({title: /教/}) #查询以“教”字开头的文档 db.collection.find({title: /^教/}) #查询以“教”字结尾的文档 db.collection.find({title: /教$/})
13、$type操作符:
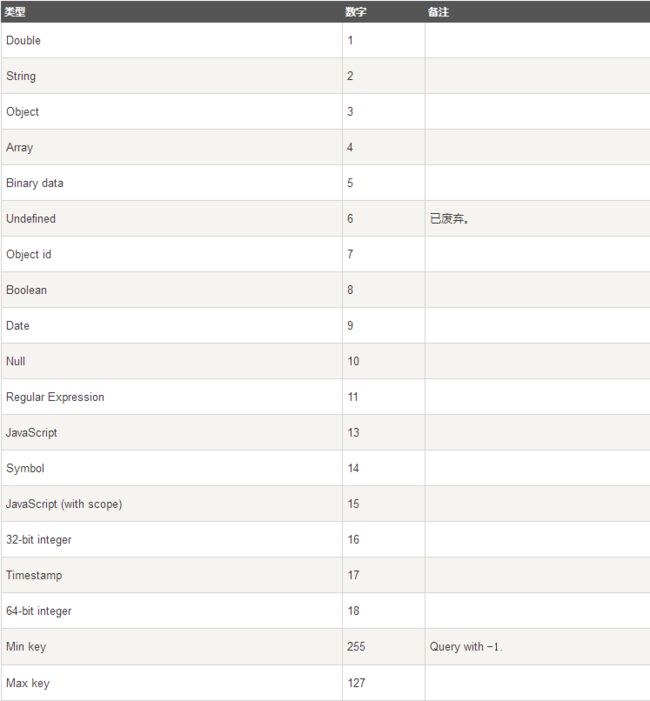
#获取集合中title为字符串的数据
>db.collection.find({'title': {$type: 2}})
>db.collection.find({'title': {$type: 'string'}})
15、Limit与Skip方法:
-
Limit()方法:指定数据记录的数量
>db.COLLECTION_NAME.find().limit(NUMBER) 举例 #第一个 {} 放 where 条件,为空表示返回集合中所有文档。 #第二个 {} 指定那些列显示和不显示 (0表示不显示 1表示显示)。 >db.collection.find({}, {'title': 1, _id: 0}).limit(2) { "title" : "PHP 教程" } { "title" : "Java 教程" } > -
Skip()方法:跳过指定数量的数据
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER) 举例 >db.collection.find({}, {'title': 1, _id: 0}).limit(1).skip(1) #skip默认参数为0 { "title" : "Java 教程" } > -
Limit() 和Skip()联合举例
#想要读取从 10 条记录后 100 条记录,相当于 sql 中limit (10,100)。 >db.COLLECTION_NAME.find().skip(10).limit(100) #假设查询第100001条数据,这条数据的Amount值是:2399927, >db.test.sort({"amount":1}).skip(100000).limit(10) //183ms >db.test.find({amount:{$gt:2399927}}).sort({"amount":1}).limit(10) //53ms >
16、排序Sort()方法:
# 通过使用1和-1来指定排序的方式
>db.COLLECTION_NAME.find().sort({KEY: 1})
#举例
>db.collection.find({}, {'title': 1, _id: 0}).sort({'likes': -1})
{ "title" : "PHP 教程" }
{ "title" : "Java 教程" }
{ "title" : "MongoDB 教程" }
>
- 注:skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit()。
17、索引——createIndex()方法
>db.collection.createIndex(keys, options)
#key为需要创建索引字段,1 为指定按升序创建索引
举例
>db.collection.createIndex({'title': 1})
#使用多个字段创建索引(关系型数据库中称作复合索引)
>db.collection.createIndex({'title': 1, 'description': -1})
18、聚合——aggregate()方法
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
-
集合
{ _id: ObjectId(7df78ad8902c) title: 'MongoDB Overview', description: 'MongoDB is no sql database', by_user: 'runoob.com', url: 'http://www.runoob.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }, { _id: ObjectId(7df78ad8902d) title: 'NoSQL Overview', description: 'No sql database is very fast', by_user: 'runoob.com', url: 'http://www.runoob.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 10 }, { _id: ObjectId(7df78ad8902e) title: 'Neo4j Overview', description: 'Neo4j is no sql database', by_user: 'Neo4j', url: 'http://www.neo4j.com', tags: ['neo4j', 'database', 'NoSQL'], likes: 750 }, -
举例
#计算每个作者所写的文章数 >db.collection.aggregate([{$group: {_id: '$by_user', num_tutorial: {$sum: 1}}}]) { "result" : [ { "_id" : "runoob.com", "num_tutorial" : 2 }, { "_id" : "Neo4j", "num_tutorial" : 1 } ], "ok" : 1 } > 类似于 select by_user, count(*) from collection group by by_user

-
管道的概念
 聚合框架中常用的几个操作
聚合框架中常用的几个操作
1、$project实例
>db.mycol.aggregate(
{$project:{
title: 1,
author: 1,
}});
2、$match实例
#$match用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
>db.mycol.aggregate([
{$match: {score: {$gt: 70, $lte: 90}}} ,
{$group: {_id: null, count: {$sum: 1}}}
]);
3、skip实例
>db.mycol.aggregate(
{$skip: 5});
19、MongoDB关系:
1:1
1:N
N:1
N:N
-
嵌入式关系
{"_id":ObjectId("52ffc33cd85242f436000001"), "contact": "987654321", "dob": "01-01-1991", "name": "Tom Benzamin", "address": [ { "building": "22 A, Indiana Apt", "pincode": 123456, "city": "Los Angeles", "state": "California" }, { "building": "170 A, Acropolis Apt", "pincode": 456789, "city": "Chicago", "state": "Illinois" }] } #查询用户地址 db.users.findOne({"name": "Tom Benzamin"}, {"address": 1}) -
引用式关系
#通过引用文档的id字段来建立关系 { "_id":ObjectId("52ffc33cd85242f436000001"), "contact": "987654321", "dob": "01-01-1991", "name": "Tom Benzamin", "address_ids": [ ObjectId("52ffc4a5d85242602e000000"), ObjectId("52ffc4a5d85242602e000001") ] } #这种方法需要两次查询: #第一次查询用户地址的对象id; #第二次通过查询的id获取用户的详细地址信息。 >var result = db.users.findOne({"name": "Tom Benzamin"}, {"address_ids": 1}) >var addresses = db.address.find({"_id": {"$in": result["address_ids"]}})
20、数据库引用:
-
使用DBRefs
{$ref: , $id: , $db: }
id:引用的id
$db:数据库名称,可选参数
{ "_id":ObjectId("53402597d852426020000002"),
"address": {
"$ref": "address_home",
"$id": ObjectId("534009e4d852427820000002"),
"$db": "runoob"
},
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin"
}
#通过指定$ref参数(address_home集合)来查找集合中指定id的用户地址信息
>var user = db.users.findOne({"name": "Tom Benzamin"})
>var dbRef = user.address
>db[dbRef.$ref].findOne({"_id": (dbRef.$id)})
#返回结果
{
"_id" : ObjectId("534009e4d852427820000002"),
"building" : "22 A, Indiana Apt",
"pincode" : 123456,
"city" : "Los Angeles",
"state" : "California"
}
21、查询分析:
-
使用explain()
#在集合中创建索引 >db.users.ensureIndex({gender: 1, user_name: 1}) >db.users.find({gender: "M"}, {user_name: 1, _id: 0}).explain() #查询结果 { "cursor" : "BtreeCursor gender_1_user_name_1", "isMultiKey" : false, "n" : 1, "nscannedObjects" : 0, "nscanned" : 1, "nscannedObjectsAllPlans" : 0, "nscannedAllPlans" : 1, "scanAndOrder" : false, "indexOnly" : true, "nYields" : 0, "nChunkSkips" : 0, "millis" : 0, "indexBounds" : { "gender" : [ [ "M", "M" ] ], "user_name" : [ [ { "$minElement" : 1 }, { "$maxElement" : 1 } ] ] } }
indexOnly: 字段为 true ,表示我们使用了索引。
cursor:因为这个查询使用了索引,MongoDB 中索引存储在B树结构中,所以这是也使用了 BtreeCursor 类型的游标。如果没有使用索引,游标的类型是 BasicCursor。这个键还会给出你所使用的索引的名称,你通过这个名称可以查看当前数据库下的system.indexes集合(系统自动创建,由于存储索引信息,这个稍微会提到)来得到索引的详细信息。
n:当前查询返回的文档数量。
nscanned/nscannedObjects:表明当前这次查询一共扫描了集合中多少个文档,我们的目的是,让这个数值和返回文档的数量越接近越好。
millis:当前查询所需时间,毫秒数。
indexBounds:当前查询具体使用的索引。
-
使用hint()
使用hint来强制MongoDB使用一个指定的索引。#如下查询实例指定了使用 gender 和 user_name 索引字段来查询: >db.users.find({gender: "M"}, {user_name: 1, _id: 0}).hint({gender: 1, user_name: 1}) #可以使用 explain() 函数来分析以上查询: >db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()
22、原子操作:
原子操作常用命令:
-
$set:用来指定一个键并更新键值,若键不存在则创建
{ $set : { field : value } } -
$unset:用来删除一个键。
{ $unset : { field : 1} } -
$inc:可以对文档的某个值为数字型(只能为满足要求的数字)的键进行增减的操作。
{ $inc : { field : value } } -
$push:把value追加到field里面去,field一定要是数组类型才行,如果field不存在,会新增一个数组类型加进去。
{ $push : { field : value } } -
$pushAll:一次可以追加多个值到一个数组字段内。
{ $pushAll : { field : value_array } } -
$pull:从数组field内删除一个等于value值。
{ $pull : { field : _value } } $addToSet:增加一个值到数组内,而且只有当这个值不在数组内才增加。
-
$pop:删除数组的第一个或最后一个元素
{ $pop : { field : 1 } } -
$rename:修改字段名称
{ $rename : { old_field_name : new_field_name } } -
$bit:位操作,integer类型
{$bit : { field : {and : 5}}}
举例
> t.find()
{ "_id" : ObjectId("4b97e62bf1d8c7152c9ccb74"), "title" : "ABC", "comments" : [ { "by" : "joe", "votes" : 3 }, { "by" : "jane", "votes" : 7 } ] }
> t.update( {'comments.by':'joe'}, {$inc:{'comments.$.votes':1}}, false, true )
> t.find()
{ "_id" : ObjectId("4b97e62bf1d8c7152c9ccb74"), "title" : "ABC", "comments" : [ { "by" : "joe", "votes" : 4 }, { "by" : "jane", "votes" : 7 } ] }
23、高级索引:
{
"address": {
"city": "Los Angeles",
"state": "California",
"pincode": "123"
},
"tags": [
"music",
"cricket",
"blogs"
],
"name": "Tom Benzamin"
}
-
索引数组字段
>db.users.ensureIndex({"tags": 1}) #创建索引后,检索集合的tags字段 >db.users.find({tags: "music"}) >db.users.find({tags: "music"}).explain() -
索引子文档字段
>db.users.ensureIndex({"address.city": 1, "address.state": 1, "address.pincode": 1}) >db.users.find({"address.city": "Los Angeles"}) >db.users.find({"address.state":"California","address.city":"Los Angeles"}) >
24、ObjectId:
-
ObjectId格式:
前4个字节表示时间戳
接下来的3个字节是机器标识码
紧接的两个字节由进程id组成(PID)
最后三个字节是随机数#创建新的ObjectId >newObjectId = ObjectId() ObjectId("5349b4ddd2781d08c09890f3") #创建文档的时间戳 >ObjectId("5349b4ddd2781d08c09890f4").getTimestamp() #返回文档创建时间 ISODate("2014-04-12T21:49:17Z") #ObjectId转换为字符串 >new ObjectId().str #返回Guid格式的字符串 5349b4ddd2781d08c09890f3
25、Map Reduce:
-
MapReduce基本语法:
>db.collection.mapReduce( function() {emit(key, value);}, //map函数 function(key, values) {return reduceFunction}, //reduce函数 { out: collection, query: document, sort: document, limit: number } )
注:使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value),遍历 collection 中所有的记录,将 key 与 value 传递给 Reduce 函数进行处理。
参数说明
**map **:映射函数 (生成键值对序列,作为 reduce 函数参数)。
reduce:统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
out:统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
query:一个筛选条件,只有满足条件的文档才会调用map函数。(query,limit,sort可以随意组合)
sort:和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
limit:发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)-
举例
在集合 orders 中查找 status:"A" 的数据,并根据 cust_id 来分组,并计算 amount 的总和。
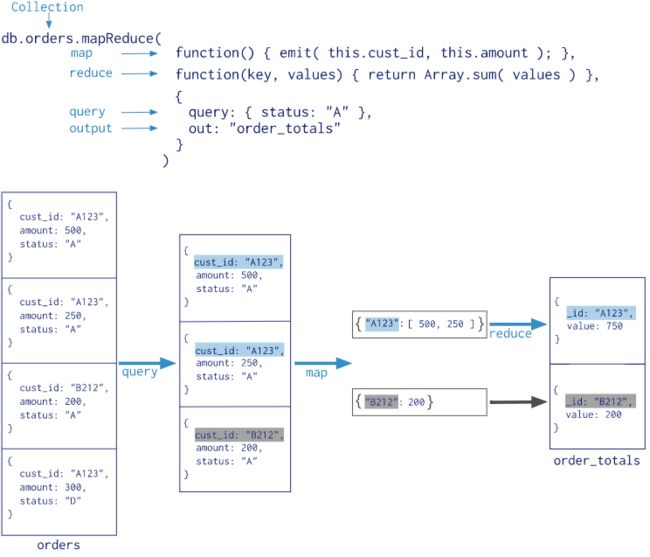
>db.posts.mapReduce( function() { emit(this.user_name,1); }, function(key, values) {return Array.sum(values)}, { query:{status:"active"}, out:"post_total" } ) #输出结果 { "result" : "post_total", "timeMillis" : 23, "counts" : { "input" : 5, "emit" : 5, "reduce" : 1, "output" : 2 }, "ok" : 1 }
未完待续...