1. 论文相关
IJCAI2018: 627-634
2. 摘要
在日常生活或职业积累的丰富知识的帮助下,人类可以自然地深入理解图像。例如,要实现细粒度图像识别(例如,对数百个从属类别的鸟类进行分类),通常需要一个综合的视觉概念组织,包括类别标签和部分级别的属性标签。本文研究了如何将丰富的专业知识与深度神经网络体系结构相结合,提出了一种处理细粒度图像识别问题的知识嵌入表示学习(KERL)框架。具体地说,我们以知识图谱的形式组织丰富的视觉概念,并利用门控图神经网络将节点信息通过图传播,生成知识表示。通过引入一种新的门控机制,我们的KERL框架将这种知识表示融入到识别图像特征学习中,即隐式地将特定属性与特征图(feature map)关联起来。与现有的细粒度图像分类方法相比,我们的KERL框架具有几个吸引人的特性:i)嵌入的高级知识增强了特征表示,从而有助于区分从属类别之间的细微差异。ii)我们的框架可以学习具有有意义的配置的特征图,突出显示的区域与知识图的节点(特定属性)很好地一致。在被广泛使用的加州理工学院的UCSD鸟类数据集上进行的广泛实验,证明了我们的KERL框架优于现有的最优越性的方法。
2.1 主要贡献
1)提出了一种新的知识嵌入表示学习框架,将高层次知识图作为图像表示学习的额外指导。据我们所知,这是第一个调查这一点的工作。2)在知识的指导下,我们的框架可以学习属性感知的特征图,具有有意义和可解释的配置,突出显示的区域与图中的相关属性有很好的关联,这也可以解释性能的提高。3)我们对广泛使用的Caltech UCSD Bird数据集【Wah等人,2011】进行了广泛的实验,并证明了拟议的Kerl框架优于领先的细粒度图像分类方法。
3. 思想
3.1 GCNN 简介
GGNN是一种递归的神经网络结构,它可以通过迭代更新节点特征来学习任意图结构数据的特征。对于传播过程,输入数据表示为图,其中是节点集,是表示图中节点之间连接的邻接矩阵。对于每个节点,它在时间步具有隐藏状态,并且在处的隐藏状态由依赖于手头问题的输入特征向量初始化。因此,基本的循环过程被表述为:
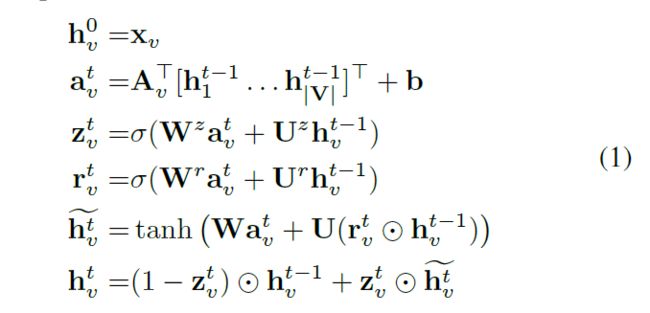
是的子矩阵,表示节点与它相邻节点之间的连接矩阵。和是logistic sigmoid
和双曲正切(hyperbolic tangent)函数。表示元素之间的乘积操作(element-wise multiplication operation)。重复传播过程,直到固定的迭代次数。我们可以得到最终的隐藏状态。为了更简化的表示,我们把等式(1)的计算过程表示为:。
3.2 知识图谱构建
知识图谱是一个视觉概念库的组织,其中包括类别标签和部分级别的属性,节点表示视觉概念,边表示它们的相关性。该图是基于训练样本的属性标注构建的。Caltech-UCSD 鸟类数据集的示例知识图谱如图所示:
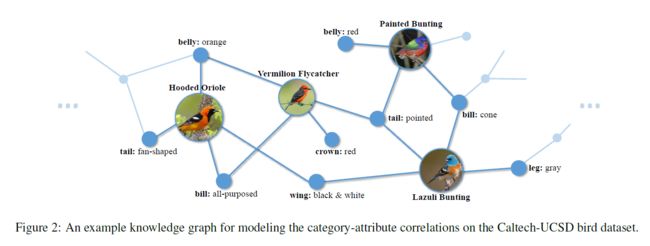
(1)视觉概念(Visual concepts):视觉概念指的是类别标签或属性。属性是对象的中间语义表示,通常它是区分两个子类别的关键。给定一个包含个对象类别和个属性的数据集,图有一个个元素的节点集。
(2)相关性(Correlation):类别标签和属性之间的相关性指该类别是否具有相应的属性。但是,对于细粒度任务,它常见的情况是,仅某个类别的某些实例具有特定的属性。例如,对于特定类别,一个实例可能具有特定属性,但另一个实例没有。因此,此类类别和属性之间的相关性是不确定的。幸运的是,我们可以为一个属性对象/实例对分配一个分数,该分数表示这个实例具有该属性的可能性。然后,我们可以对属于一个特定类别的所有实例的属性/对象实例对的得分进行汇总,得到一个得分来表示这个类别拥有该属性的置信度。所有分数均线性归一化为以获得一个的矩阵。请注意,两个对象类别节点之间或两个属性节点之间不存在任何连接,因此完整的邻接矩阵可以表示为:
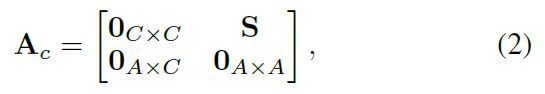
However, for the fine-grained task, it is common that merely some instances of a category possess a specific attribute. For example, for a specific category, it is possible that one instance has a certain attribute, but another instance does not have. Thus, such category/attribute correlation is uncertain.
3.3 知识表示学习
在构建了知识图谱之后,我们利用GGNN在图中传播节点信息,并计算出每个节点的特征向量。然后将所有特征向量连接起来,以生成知识图谱的最终表示。
我们表示给定图像中该类别的置信度的分数来初始化引用类别标签的节点,并用零向量初始化引用每个属性的节点。所有类别的得分向量由将在第4.1节中详细介绍的预训练的分类器生成。因此,每个节点的输入特征可以表示为:

其中是一个维数为的零向量。如上所述,在传播过程中,所有节点的消息都会相互传播。利用方程1的计算过程,被用来将消息从某个节点传播到其相邻节点,并利用矩阵进行信息反向传播。因此,邻接矩阵是
对于每个节点,使用初始化其隐藏状态,并且在时间步(timestamp),使用如方程(1)所示的传播过程更新隐藏状态,,表示为:
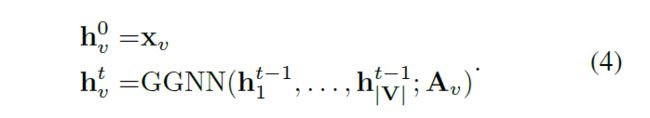
在每次迭代中,每个节点的隐藏状态由其历史状态和相邻节点发送的信息决定。这样,每个节点都可以聚合来自其邻居的信息,同时将其信息传递给其邻居。这个过程如图3所示。在次迭代之后,每个节点的信息都会在图中传播,我们可以得到图中所有节点的最终隐藏状态,即。
与[Li et al.,2015]相似,节点水平的特征被计算通过:
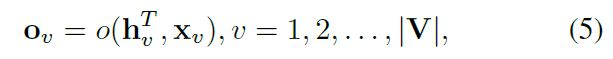
其中是由全连接层实现的输出网络。最后,将这些特征连接起来以生成最终的知识表示。
3.4 联合表示学习
在这部分中,我们介绍了嵌入知识表示的门控机制(gated mechanism),以增强图像表示学习。
(1)图像特征提取:我们首先介绍图像特征提取。由于紧凑双线性模型在细粒度图像分类方面工作良好,因此我们直接将该模型用于提取图像特征。具体地说,给定一幅图像,我们使用全卷积网络(FCN)提取尺寸为的特征图,并使用一个紧凑的双线性算子生成特征图。注意,我们没有像[Gao等人,2016]那样执行和池化(sum pooling),因此的大小还是。为了与现有工作进行公平比较,我们使用VGG16-NET网络的卷积层实现FCN,并按照[gao等人,2016]默认设置为8192。
[Gao等人,2016]将所有特征同等重要的对待,并简单地执行和池化,以获得用于预测的维特征。在细粒度图像分类的背景下,关键是要注意区分有判别力的区域,捕捉不同子类别之间的细微差别。此外,知识表示对类别属性关联进行编码,可以捕捉到具有识别性的属性。因此,我们将此表示嵌入到图像特征学习中,以学习与此属性对应的特征。具体地说,我们引入了一种门控机制,在知识的指导下,可以选择性地允许信息性特征通过,同时抑制非信息性特征,这可以用公式表示为:

表示在位置的特征向量。充当一个门控机制,决定哪个位置更重要。是一种神经网络,它以和的串联作为输入,并输出一个维真实值向量。它由两个堆叠的完全连接层实现,第一层是10752(8192+512×5)到4096,随后是双曲正切函数,第二层是4096到8192。然后将特征向量输入到一个简单的全连接层,以计算给定图像的分数向量。
3.5 总体结构

sum pooling操作是什么?
4. 方法
4.1 实验结果
通过知识嵌入,我们的框架可以学习具有直观配置的特征图,突出显示的区域总是与相关属性相关。在这里,我们在sum pooling之前可视化特征图,以便更好地评估图5中的这一点。我们对每个位置的通道的特征值进行求和,并将其规范化为[0,1]。在每一行,我们展示了从一个特定类别中获取的几个样本的学习特征图和一个显示了这个类别与其属性的相关性的知识图谱子图。我们发现,同一类别样本的突出显示区域指的是相同的语义部分,这些部分与能够很好地区分该类别与其他类别的差异性的属性具有很好的一致性。
以“Sayornis”类别为例,我们的框架始终强调所有样本的喉和翼,对应两个关键属性,即“喉:浅黄色和白色”和“翼:浅黄色和棕色”(图5中用橙色圆圈突出显示)。这表明我们的kerl框架可以学习属性感知特性,这些特性可以更好地捕获不同从属类别之间的细微差异。此外,它还可以为框架的性能改进提供解释。
为了清楚地证明是知识嵌入带来了如此吸引人的特性,我们进一步将CB-CNN模型生成的特征图可视化如图6。我们将与图5中前两个类别相同的样本进行可视化,以便进行直接比较。据观察,一些突出的区域位于背景中,一些分散在鸟类的全身。


5.代码
参考资料
[1] 《Knowledge-Embedded Representation Learning for Fine-Grained Image Recognition》论文笔记
论文
[1] Knowledge-Embedded Representation Learning for Fine-Grained Image Recognition