从广义上来讲:数据结构就是
一组数据的存储结构, 算法就是操作数据的方法数据结构是为算法服务的,算法是要作用在特定的数据结构上的。
10个最常用的数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie树
10个最常用的算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
本文总结了20个最常用的数据结构和算法,不管是应付面试还是工作需要,只要集中精力攻克这20个知识点就足够了。
数据结构和算法(一):复杂度、数组、链表、栈、队列的传送门
数据结构和算法(二):递归、排序、通用排序算法的传送门
数据结构和算法(三):二分查找、跳表、散列表、哈希算法的传送门
数据结构和算法(四):二叉树、红黑树、递归树、堆和堆排序、堆的应用的传送门
数据结构和算法(五):图、深度优先搜索和广度优先搜索、字符串匹配算法、Trie树、AC自动机的传送门
数据结构和算法(六):贪心算法、分治算法、回溯算法、动态规划、拓扑排序的传送门
第六章 递归
一、如何理解递归?
-
- 递归是一种应用非常广泛的算法,之后我们要讲的很多数据结构和算法的编码实现都要用到递归,例如DFS深度优先搜索、前中后序二叉树遍历等等,所以搞懂递归非常重要。
-
- 一个例子帮你搞懂递归:周末带女朋友去看电影,女朋友问你咱们现在是第几排?电影院里太黑没法数,你该怎么办?这个时候递归就派上用场了,于是,你问前边一排的人他是第几排,你想只要在他的数字上加1,就可以知道自己是第几排,但是前边的人也看不清啊,所以他也问前边的人,就这样一排一排的往前传,直到问到第一排,告诉说我是第一排,然后再这样一排一排的把数字传递回来,这样你就知道答案了。
-
- 这就是一个标准的递归求解问题的分解过程,去的过程叫做“递”,回来的过程叫做“归”。解决递归问题,需要写出递推公示,刚才这个问题的递推公示是这样的:
刚才这个问题的递推公示:
f(n) = f(n - 1) + 1 , 其中f(1) = 1 //f(n)表示你想知道自己在哪一排,f(n-1)代表你前边的一排的排数
-
- 有了递推公示,我们很方便可以写出递归代码:
func f(_ n: NSInteger) -> NSInteger{
if n == 1 {
return 1
}
return f(n - 1) + 1
}
二、什么情况下使用递归?
满足以下三个条件的问题,就可以使用递归的方法求解
-
- 一个问题可以拆解成几个子问题的解
-
- 这个问题和之后的子问题,除了数据规模以外,求解思路完全相同
-
- 存在递归终止条件
三、如何编写递归代码?
写出递归代码的关键在于:
-
- 写出递推公式
-
- 找出终止条件
总结一下:写出递归代码的关键在于找到将大问题分解成小问题的规律,并基于此写出递推公式,找出终止条件,最后将递推公式和终止条件翻译成实际代码。
注意!! : 不要试图用人脑去分解递归的每一个步骤,只需要搞清一层关系并保证后续规律一致即可。
四、写递归代码要注意的地方
-
- 递归代码要警惕堆栈溢出,讲第四章“栈”的时候讲过,函数的调用是基于函数调用栈的,函数调用栈会保存函数的临时变量,直到函数调用完毕。一旦递归调用层次很深,一直压入栈,就会有堆栈溢出的风险。
-
- 递归代码要警惕重复运算,如下图,我们把看电影数排数的问题分解一下,就会发现其中f(3)被重复计算了很多次,这就是重复计算问题。
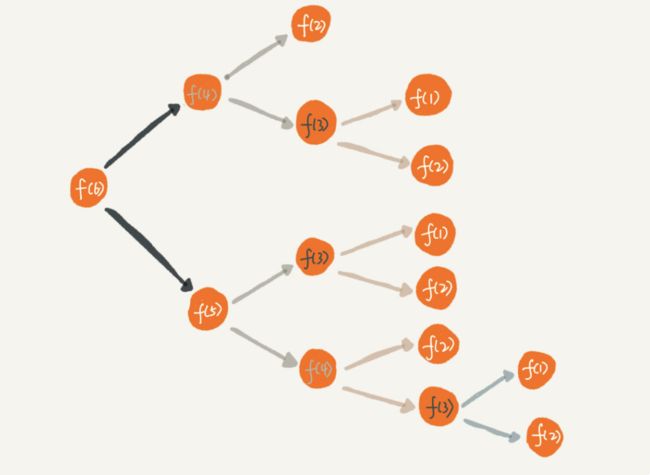 重复计算问题
重复计算问题
为了避免重复计算,我们可以通过一个数据结构(例如散列表)来保存已经求解过的f(k),当递归调用f(k)时,先看下是否已经求解过了,如果是,直接从散列表中取值返回,不需要重复在计算了。
- 递归代码要警惕重复运算,如下图,我们把看电影数排数的问题分解一下,就会发现其中f(3)被重复计算了很多次,这就是重复计算问题。
-
- 递归代码要警惕存在环而导致无限递归的问题,例如A依赖B,B依赖C,C又依赖A,一旦存在这种环,就会出现无限递归的问题,可以用限制递归深度来解决,不过还有更高级的方法,后续再说。
第七章 排序基础知识 + 复杂度为O(n*n)的排序算法
一、如何衡量一个排序算法的好坏:
-
- 最好、最坏、平均时间复杂度,及最好、最好时间复杂度的原始数据 (针对小规模数据排序时,如果是同阶时间复杂度,应该把系数、常数、低阶也考虑进来)
-
- 空间复杂度 (空间复杂度为1的叫做原地排序)
-
- 稳定性 (排序的稳定性是指相等的对象,在排序之后,顺序保持不变)
-
- 对基于比较的排序算法,应该把比较次数和交换次数也考虑进去
二、有序度、逆序度、满有序度
-
- 有序度就是有顺序关系的元素对个数,例如:1、3、4的有序度就是3,(1,3)、(1,4)、(3,4)
-
- 满有序度就是指完全有序的数组,例如:1、2、3、4, 满有序度 = n * (n-1) / 2
-
- 逆序度就是有逆序关系的元素个数,逆序度 = 满有序度 - 有序度
-
- 我们排序的过程就是增加有序度,减少逆序度的过程,最后达到满有序度就说明排序完成了。(交换次数就是逆序度)
三、冒泡排序
-
- 原理:从第一个开始,依次比较相邻元素的大小然后进行交换操作,把大的往后交换,直到没有交换操作为止。
-
- 最好时间复杂度:O(n),当数组刚好是顺序的时候,只需要挨个比较一遍就行了,不需要做交换操作,所以时间复杂度为O(n)
-
- 最坏时间复杂度:O(n * n),当数组刚好是完全逆序的时候,需要挨个比较,并且重复n次,所以时间复杂度为O(n*n)
-
- 平均时间复杂度:O(n * n),当数组是一半的满有序度n * (n-1)/4时,进行计算的话,交换次数就是n * (n-1)/4,比较次数肯定比交换次数多,所以得出来的不准确的平均时间复杂度为O(n * n)
-
- 冒泡的稳定性:元素相同时不做交换,所以冒泡是稳定的排序算法
四、插入排序
-
- 原理: 选取未排序的元素,插入到已排序区间的合适位置,止到未排序区间为空。
-
- 最好时间复杂度: O(n),当数组刚好是完全顺序时,每次只用比较一次就能找到正确的位置,重复n次,就可以清空未排序区间,所以最好时间复杂度为O(n)
-
- 最坏时间复杂度:O(n * n),当数组刚好是完全逆序时,每次都要比较n次才能找到正确位置,重复n次,才能清空未排序区间,所以最坏时间复杂度为O(n * n)
-
- 平均时间复杂度:O(n * n),因为往数组中插入一个元素的平均时间复杂度为O(n),而插入排序可以理解为重复n次的数组插入操作,所以平均时间复杂度为O(n * n)
-
- 插入的稳定性:未出现的元素总会插入到已排序元素的前边,所以插入排序是稳定的排序算法。
五、插入排序为何比冒泡排序更优?
-
- 相同点:插入排序和冒泡排序的平均时间复杂度都是O(n*n),都是稳定的排序算法,都是原地排序,元素交换的次数都是逆序度。
-
- 插入比冒泡的优势:冒泡的交换操作需要三个赋值操作,而插入只需要一步赋值操作,而且插入排序还有很大的优化空间,所以插入更优选一点。
第八章 时间复杂度为O(nlogn)的排序算法
一、归并排序
-
- 原理:将数组分成前后两部分,对这两部分分别进行排序,将排序好的两部分再合并在一起,这样整个数组就有序了。
-
- 方法:使用分治思想,将大问题可以拆解成子问题,子问题的解决思路与大问题一样,所以可以使用递归解决,需要写出递推公式,并找到终止条件
-
- 递推公式:merge_sort(p…r) = merge(merge_sort(p...q),merge_sort(q+1,r)) , p是数组的最小索引值,q是数组的中间索引值,r是数组的最大索引值
-
- 终止条件:p>=r时不在继续分解,也就是分解到只剩下一个的时候就不分解了
-
- 最好、最坏、平均时间复杂度都是:O(nlogn),T(n) = 2T(n/2) + n = O(n*logn)(因为合并两个有序数组的时间复杂度是O(n),所以需要加上n)
-
- 空间复杂度:每次合并操作都需要开辟临时内存空间,所以空间复杂度为O(n),不是原地排序
-
- 归并的稳定性:因为合并的时候相同元素的前后顺序不变,所以归并是稳定的排序算法
二、快速排序
-
- 原理:选取数组中任意一个数据作为pivot分区点,将小于它的放在它的左侧,大于它的放在它的右侧,利用分治思想,继续分别对左右两侧进行同样的操作,直至区间缩小为1。
-
- 方法:使用分治思想,递归的解决问题,需要写出递推公示,找出终止条件
-
- 递归公示: quick_sort(p...r) = quick_sort(p...q-1) + quick_sort(q+1,r),q是分区点,p到q-1的是小于q的,q+1到r时大于q的
-
- 终止条件:p>=r,也就是区间中只剩一个元素时终止
-
- 最好时间复杂度:如果每次选取分区点时,都能把数组等分成两个,此时的时间复杂度和归并一样,都是O(n*logn)
-
- 最坏时间复杂度:如果每次分区都是不均等的,那么就需要n次分区操作,每次分区平均扫描n/2个元素,此时时间复杂度就退化为O(n*n)了
-
- 平均时间复杂度:大部分情况下的时间复杂度都是O(n)
-
- 空间复杂度:使用交换法,使空间复杂度降低为O(1)
-
- 快排的稳定性:因为分区过程涉及交换操作,所以快排是不稳定的排序算法
三、如何在O(n)时间复杂度内,找出无序数组中的第K大元素
-
- 选取数组区间A[0...n-1]的最后一个元素A[n-1]作为分区点,进行原地分区(也就是利用快排的思想,小的放左边,大的放右边,组合在一起行程一个新的数组),数组就变成了三部分A[0...p-1]、A[p]、A[p+1...n-1]
-
- 如果p+1=K,那A[p]就是第K大元素
-
- 如果K>p+1,那么第K大元素就在A[p+1]到A[n-1]区间中,利用递归方法,在用1中的方法把A[p+1]到A[n-1]进行原地分区,
-
- 如果K
- 如果K
-
- 时间复杂度:第一次分区,需要遍历N个元素,第二次分区需要遍历N/2个元素,第三次分区需要遍历N/4,知道区间缩小为1,总共需要遍历N+N/2+N/4+N/8+....+1=2N-1个元素,所以时间复杂度为O(2n-1),忽略常量之后,就是O(n)
-
- 空间复杂度:原理与快排一样,所以空间复杂度为O(1)
第九章 时间复杂度为O(n)的排序算法
一、线性排序
-
- 线性排序算法包括:桶排序、计数排序、基数排序
-
- 线性排序由于不涉及元素间的比较,所以能做到线性时间复杂度O(n)
-
- 对要排序的数据要求很苛刻
二、桶排序
-
- 原理:将数据分到若干个有序的桶里,每个桶里单独排序,之后再将每个桶里的数据顺序取出,组成的序列就是有序的了。(分桶,每个桶内快排)
-
- 对数据的要求:首先,数据必须很容易就分成若干个桶,并且桶和桶之间存在天然的大小顺序;其次,数据在各个桶的分布是比较均匀的。
-
- 时间复杂度:最好为O(n),最坏为O(nlogn),取决于桶的划分,如果桶适量且数据分布均匀则为O(n);如果数据全在一个桶里,然后桶内部排序用了快排,则为O(nlogn)
-
- 空间复杂度:O(n/m),n为数据规模,m为桶的数量
-
- 稳定性:如果每个桶内部都用归并的话,是稳定的,如果用快排的话,就是不稳定的
-
- 适用场景:例如:外部排序,也就是数据存储在外部磁盘,且数据量较大,而内存有限,无法将数据全部加载到内存中。
三、计数排序
-
- 原理:计数排序其实就是特殊的桶排序,划分若干个桶,让每个桶内的数值都是相同的,省去桶内排序的时间 (按值分桶,每个桶内值相同,通过统计计数,实现排序)
-
- 对数据的要求:只能用在数据范围不大的场景中,并且数据范围要与数据规模相差不大,并且只能给非负整数排序
-
- 时间复杂度:O(n)
-
- 空间复杂度:O(n)
-
- 稳定性:稳定
四、基数排序
-
- 原理:按照位进行排序,从后往前一位一位的排序 (在每一位上桶排序)。例如对10万个手机号进行排序,先按照最后一位来排序手机号,然后再按照倒数第二位排序手机号,以此类推,最后按照第一位排序手机号。
-
- 对数据的要求:数据必须可以分出独立的位来,并且位之间有递进关系,高位大则低位就不用比较了,并且每一位的数据范围不能太大,要可以用线性算法排序。
-
- 时间复杂度:O(n)
-
- 空间复杂度:O(n)
-
- 稳定性: 稳定
第十章 如何实现一个通用的、高性能的排序函数?
一、选择合适的排序算法
首先,回顾一下前边讲过的排序算法,如下图所示:
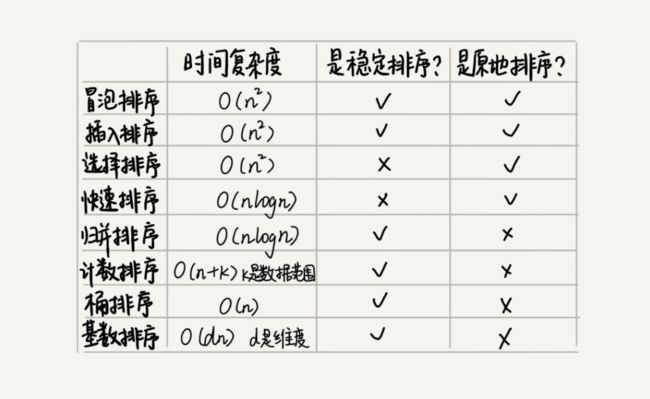
排序算法
-
- 由于线性排序算法对数据要求比较苛刻,所以做通用的排序函数,不能使用线性排序
-
- 如果对数据规模比较小的数据进行排序,可以选择时间复杂度为O(n * n)的排序算法
-
- 对数据规模比较大的数据进行排序,就需要选择O(nlogn)的排序算法了
-
- O(nlogn)的算法有归并排序、快速排序等。归并排序的空间复杂度为O(n),也就意味着排序100M的数据,就需要200M的空间,所以归并不适合;快速排序在平均时间复杂度为O(nlogn),但是如果分区点选择不好的话,最坏时间复杂度为O(n * n),如果可以对分区点的选取进行优化,快排还是不错的选择对象。
二、快排的分区点如何选择
-
- 三数取中法,我们从首、尾、中间各取一个数,选择中间值作为分区点。如果要排序的数组比较大,那么三数取中可能就不太够了,需要“五数取中”或者“十数取中”。
-
- 随机法,每次从要排序的区间内随机选择一个元素作为分区点,从概率学的角度来说,不太可能每次选取的分区点都是很差的,所以平均情况下这么选也是可以的,时间复杂度退化到O(n * n)的概率不大。
三、以Glibc中的qsort()函数为例,具体分析一下工业级的排序函数
-
- 如果你去看源码,你就会知道
qsort()会优先使用归并排序来排序数据,归并排序的空间复杂度为O(n),所以对小规模的数据,例如1KB、2KB而言,这个问题不大,现在计算机的内存都挺大的,这就是以空间换时间的一个典型应用。
- 如果你去看源码,你就会知道
-
- 但是如果数据量比较大的话,再用归并就不合适了,这时候,
qsort()会改用快速排序来排序,qsort()使用了三数取中法来选择分区点。
- 但是如果数据量比较大的话,再用归并就不合适了,这时候,
-
- 对于递归太深会导致堆栈溢出的问题,
qsort()自己实现了一个堆上的栈,用手动模拟递归的办法来解决的。
- 对于递归太深会导致堆栈溢出的问题,
-
- 实际上,
qsort()不仅仅用了归并和快排,还用到了插入排序,在快速排序过程中,当要排序的区间中的元素个数小于等于4时,qsort()就退化为了插入排序,不再用递归做快排了,原因也很简单,因为在小规模数据面前,O(n * n)时间复杂度的算法不一定比O(nlogn)的算法执行的时间长。
- 实际上,
-
- 我们在说复杂度分析的时候说过,算法的性能可以用时间复杂度来分析,使用O表示法的时候,会省略低阶、系数、常数,但是对比小规模数据来说,低阶、系数、常数就不能忽略了,也就是说O(nlogn)在没有忽略这些前,可能是O(klogn+c),k和c可能是一个比较大的数,就可能比O(n^2)大了。
假设k = 1000,c=200时,klogn+c > n^2
knlogn+c = 1000 * 100 * log100 + 200 远大于 10000
n^2 = 100*100 = 10000