[TOC]
SQL语句
表相关语句
创建表
**create [temp|temporary] table [if not exists] table_name(column_definition, ... [, constraints]);**
eg: create table contacts (id integer primary key, name text not null collate nocase, phone text not null default 'UNKNOWN', unique (name, phone));
temp, temporary:表示创建的表是临时表,只在当前会话有效,数据库连接断开时,该表被自动销毁.
column_definition:字段定义由列名,域,字段约束组成.
constraints:表一级的约束, unique (name, phone)定义在字段name和phone上.
修改表
**alert table table_name {rename to name | add column column_definition};**
rename to name:重新对表命名;
add column column_definition:新增一列;
另外:SQLite不支持对表字段的重命名,删除,修改操作.
删除表
**drop table table_name [if exists]**
查询数据
select
**select [distinct] heading from tables where predicate group by columns having predicate order by columns limit count1 offset count2;**
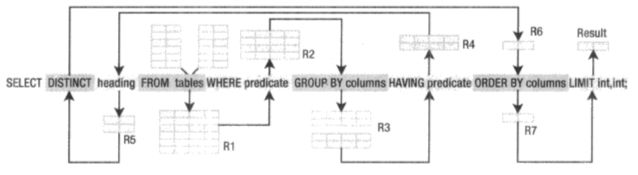
select语句最常见的语法是select heading from tables where predicate;
distinct:表示是否去除重复数据,同时此处还可以使用top count表示取前count的数据;
where子句需要注意的是like和glob操作符,like使用%(多个)和(单个)作为通配符,大小写不敏感,glob使用*(多个)和(单个)作为通配符,大小写不敏感;
limit count1 offset count2 等价于 limit count2, count1.
多表连接:
**select heading from left_table join_type right_table on join_condition**
内连接:
隐式实现:select * from foods, food_types where foods.id = food_types.food_id;
显示实现:select * from foods inner join food_types on foods.id = food_types.food_id;
左外连接:
select * from foods left join food_types on foods.id = food_types.food_id;
右外连接:
select * from foods right join food_types on foods.id = food_types.food_id;
全外连接:
select * from foods cross join food_types;
SQLite不支持右外连接和全外连接,右外连接可以使用左外连接代替,而全外连接可以通过复合查询来实现.
子查询
子查询是指select语句中嵌套select语句.子查询可以用在一般表达式不能使用的地方,也可以应用在select语句中的各个位子.
- select count(*) from foods where type_id in (select id from food_types where name = 'A');
- select name, (select count(id) from foods_episodes where food_id = f.id) count from foods f order by count desc limit 10;
- select * from foods f order by (select count(type_id) from foods where type_id = f.type_id) desc;
- select f.name, types.name from foods f inner join (select * from food_types where id = 6 ) types on f.type_id = types.id;
- etc.
复合查询
复合查询使用三种特殊的关系操作符(联合,交叉连接和差集)处理多个查询的结果,在SQLite中联合-union,交叉连接-intersect,差集-except.复合查询的关系是从左到右处理的,同时复合查询需要满足以下条件:
涉及的关系的字段数目必须相同;
-
只能有一个order by子句,并且在复合查询的最后,对复合查询的结果进行排序.
union操作输入两个关系: A和B, 将两者联合成一个只包含A和B中非重复字段的单一关系.默认情况下,union会消除重复数据,如果想要保留结果中的重复数据,可以使用union all.

intersect操作输入两个关系: A和B, 选择那些既在A也在B的行.
因为复合查询只允许句末有一个order by,可以通过子查询绕过这一限制,子查询独立于复合查询的运行.
except操作输入两个关系: A和B,找出所有在A但不在B的行.
条件结果
case表达式允许在select语句中处理各种情况,case表达式中,只执行一个条件,如果满足的条件超过一个,也只执行第一个;如果没有满足条件,同时没有定义else条件,case返回null.它有两种形式:
- case value
when x then value_x
when y then value_y
when z then value_z
else default_value
接收静态值并列出各种情况下的case返回值.
- case value
when condition1 then value1
when condition2 then value2
when condition3 then value3
else default_value
在when使用表达式,并返回不同情况下的返回值.
null
null是一种支持"未知"或"不可知"的特殊占位符,表示缺失信息,本身不是值. null表示该位置没有值, null不是什么其他值, null不是真,不是假,不是零,也不是空字符串,null就是null.
- 为了在逻辑表达式中使用null, SQLite使用三值(三态)逻辑, null是真假值之一;
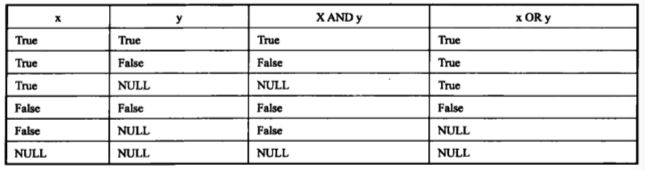
- 可以通过is null 或者 is not null操作符检测null是否存在;
- null不等于其他任何值,包括null,不可以将null与其他值进行比较, null不会大于或者小于,甚至等于其他任何null.
修改数据
insert
**insert into table_name(column_list) values(value_list);**
使用select形式的insert可以一次插入多行数据, eg: insert into foods2 select * from foods;只要字段匹配,就可以插入select结果集中的所有行.
定义为unique的字段插入重复值时.SQLite会停止报错(冲突,停止报错是默认操作).
可以将创建表和插入表的两步操作合并为一步:create temp table foods2 as select * from foods;但使用这种形式时,源表中的任何约束都不会定义在新表中,自增长字段不会在新表中创建,索引也不会创建,unique约束等也不会创建.
update
**update table_name set update_list where predicate;**
delete
**delete from table_name where predicate;**
数据完整性
数据完整性用来定义和保护表内和表之间的数据关系。数据完整性有四种:域完整性,实体完整性,引用完整性(外键关系),用户自定义完整性。数据完整性是通过约束实现的。
域完整性涉及控制字段内的值,实体完整性涉及表中的行,引用完整性涉及表之间的行,实际上就是外键关系,用户自定义完整性则十分广泛。
约束
- unique 唯一性约束
在SQLite中unique约束的字段可以插入任意多个null,但是在某些数据库中只允许插入一个null,甚至DB2禁止插入null。
- primary key 主键约束
主键是一个64bit的整型字段,SQLite为主键提供自增长功能,当插入数据时未给定值时,SQLite会创建默认值,并确保该值是唯一的。组件的最大值为2^63 - 1 (9223372036854775807)。
主键并不是严格的顺序增长,当删除表中的数据时,后面的新增操作可能会使用回收的主键使用,如果需要使用唯一的自动主键值,而不是“填补空白”,需要在主键定义integer primary key后加上关键字autoincrement。
当主键值没有可用的时插入新的数据时,SQLite会返回SQLITE_FULL错误。
- default 默认值
- not null 非空约束
- check约束
check约束允许定义表达式来测试要插入或者更新的字段值,如果值不满足设定的表达式标准,SQLite会报违反约束错误。
- 外键约束
排序规则
排序规则涉及文本值如何比较。SQLite有三种排序规则:默认的是二进制排序规则,该规则使用C函数memcmp()逐字节比较文本值,大小写敏感;nocase是拉丁字母中使用的26个ASCII字符的非大小写敏感排序算法;reverse排序规则,与二进制排序规则相反。
存储类
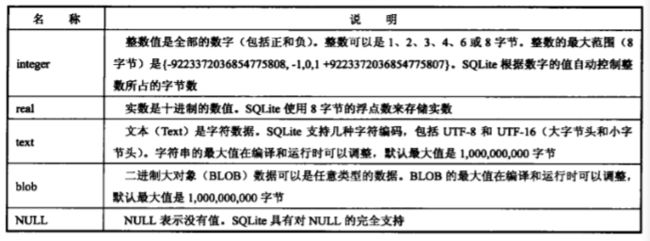
SQLite通过值的表示法来判断其类型,SQL函数typeof()根据值的表示法返回其存储类。
不同存储类的值通过它们各自类的“类值”进行排序,规则如下:
- null存储类具有最低的类值,在null值之间,没有具体的排序顺序;
- integer或real存储类值高于null,它们的类值相等,integer和real通过其数值大小比较;
- text存储类值比integer和real高,即数值永远比字符串的值低,当两个text值进行比较时,其值大小由该值定义的排序法决定;
- blob存储类具有最高的类值。blob之间的比较使用C函数memcmp()。
视图
视图,虚拟表,也称为派生表,因为视图的内容都派生自其他表的查询结果。视图的内容与基本表一样,但是基本表的内容是持久的,而视图的内容是使用时动态产生的。
**create view view_name as select-stmt;**
**drop view view_name;**
视图的内容是动态生成的,当每次使用视图时,会基于数据库的当前数据执行相关的sql语句,产生视图内容。
SQLite不支持可更新的视图,即不能对视图进行insert或者update操作。如果需要,可以使用触发器实现类似的功能。
索引
索引是一种用来在某种条件下加速查询的结构, SQLite使用B-tree实现索引。
索引的缺点:
- 索引会增加数据库的大小;
- 索引的维护是自动的,进行insert,update,delete操作时,除了修改表,数据库还会对相应的索引进行修改,因此虽然索引可以加速查询,但是降低了insert,update,delete操作的性能。
**create index [unique] index_name on table_name(columns);**
**drop index index_name;**
排序规则
索引中的每个字段都有相关的排序规则,当需要索引中的字段按照大小写无关排序时可以使用:create index [unique] index_name on table_name(column_name collate nocase)。
索引使用
当where子句中出现下列表达式中,SQLite将使用单个字段索引:
column {= | > | < | <= | >=} expression
expression {= | > | < | <= | >=} column
column in (expression-list)
column in (subquery)
SQLite多字段索引的处理逻辑是从左到右智能地使用字段,即从左边的字段开始,查询使用字段的条件,然后移动到第二个字段,以此类推,直到where子句中无法找到有效的条件。
eg: create index index_name on table_name(a, b, c, d);
- select * from index_name where a = 1 and b = 1 and d = 1;
此时只有a, b使用索引,d没有使用索引是因为没有条件使用c来缩小到d的差距; - select 8 from index_name where a > 1 and b =1 and c = 1 and d = 1;
只有a使用索引,a > 1被成为最右边的索引字段,因为表达式使用了不等号,在此之后的所有字段作为结果都是不合法的; - select 8 from index_name where a = 1 and b >1 and c = 1 and d = 1;
a, b使用了索引,原因同上。
触发器
当具体的表发生特定的数据库事件时,触发器执行相应的sql命令。
**create [temp | temporary] trigger name [before | after] [insert | delete | update | update of columns] on table action;**
触发器可以用来创建自定义完整性约束,日志改变,更新表和其它事情。
事务
事务定义了一组sql命令的边界,这组命令或者作为一个整体全部执行,或者都不执行,这被成为数据库完整性的原子性原则。
事务的范围
事务由3个命令控制: begin, commit, rollback。
begin开始一个事务,begin之后的所有操作都可以取消,如果连接终止前没有发出commit,begin之后的操作会被取消;
commit提交事务开始后的所有已执行的操作;
rollback还原事务开始后的所有已执行的操作。
SQLite还支持savepoint和release命令,用来扩展事务的灵活性。
可以创建多个savepoint,命令savepoint savepoint_name;
当不需要回滚整个事务时,使用rollback [transaction] to savepoint_name;来回滚到特定的节点。
冲突解决
SQLite有独特的方法允许指定不同的方式来处理约束违反(或者说从约束违反中恢复),这种功能叫做冲突解决。SQLite默认行为是终止命令并回滚所有的修改,保存事务的完整性。
SQLite提供5种可能的冲突解决方法或策略:replace, ignore, fail, abort, rollback。
5种方法定义了错误容忍范围或敏感度,从最宽松的replace,到最严格的rollback。
- replace:当违反了唯一性约束时,SQLite将原始数据删除,插入新的数据替代,sql继续运行且不会报错;当违反了not null约束时,使用该字段的默认值代替null,如果该字段没有默认值,SQLite应用abort策略.
当冲突解决策略为了满足约束而删除记录时,该行的删除触发器不会触发;
- ignore:当约束违反发生时,SQLite允许命令继续执行,违反约束的行保持不变,其他命令继续执行;
- fail:当约束违反发生时,SQLite终止命令,但不恢复约束违反之前已经执行的记录,即在约束违反之前发生的改变都保存;
fail需要注意的是数据更新的操作顺序是不确定的,无法确定SQLite以何种顺序处理它们.因此在大多数情况下,使用ignore会更好.
- abort:当约束违反发生时,SQLite恢复命令所做的所有改变并终止命令;
abort是SQLite中所有操作的默认冲突解决方法,也是sql标准定义的行为.
- rollback:当约束违反发生时,SQLite执行回滚,终止当前命令和整个事务,最终的结果是当前命令所做的改变以及事务中约束违反之前命令造成的改变都被回滚.
rollback是最严格的冲突解决方法,单个约束违反导致事务中执行的所有操作都回滚.
冲突解决方法可以在sql命令中指定,也可以再表和索引的定义中指定,即冲突解决方发可以在insert,update,create table和create index中指定.
冲突解决方法在inset和update中的语法:
**insert or resolution into table(column-list) values(value-list);**
**update or resolution table set(column-list) where predicate;**
冲突解决方法紧跟在insert或update命令后面,并在之间加入or, insert or replace表达式可以缩写成replace.
冲突解决方法是语句级(DML)的,可以覆盖对象级(DDL)定义的.eg:
create table a(name text unique on conflict rollback);
insert or replace into a values('a');
对象级(DDL):表a中的name字段,该字段的冲突解决方法;
语句级(DML):insert or replace命令中的replace;
因此,replace冲突解决方法会覆盖a.name中定义的rollback冲突解决方法.
数据库锁
SQLite使用锁逐步提升机制,读数据库只需要获得共享锁,而为了写数据库,连接需要主机获取排它锁.SQLite有5种锁状态:未加锁(unlocked),共享(shared),预留(reserved),未决(pending),排它锁(exclusive),每个数据库连接在同一时刻只能处于一种状态,除未加锁状态外,其它每一种状态都有一种锁与之对应.
- 最初的状态是未加锁状态,在此状态下,连接还没有访问数据库,当连接一个数据库,甚至已经用begin开始了一个事务时,连接都还处于未加锁状态;
- 未加锁状态的下一个状态是共享状态,为了能够在数据库中读数据,连接必须进入共享状态,即获得一个共享锁.多个连接可以同时获得并保持共享锁,也就是多个连接可以同时从同一个数据库中读数据,但只要有一个共享锁没有释放,也不允许任何连接写数据库;
- 当一个连接想要写数据库操作时,必须首先获得一个预留锁,在此阶段,SQLite在缓存区进行数据库修改操作,对读出内容所做的修改保存在内存缓存区中,而不是实际写到磁盘;
一个数据库同时只能有一个预留锁,预留锁可以与共享锁共存,预留锁既不阻止其他拥有共享锁的连接读取数据库,也不阻止其它连接获取新的共享锁.
- 当连接想要提交修改时,预留锁提升为未决锁,,在这个阶段,其它连接不再能够获取新的共享锁,但已经拥有的共享锁的连接能够继续正常的读数据库,此时,拥有未决锁的连接等待其它拥有共享锁的连接完成工作并释放其共享锁;
未决锁可以理解为一个中间状态,从限制小的状态往限制高的状态变化的一个过程.
- 一旦其它共享锁都被释放,未决锁提升为排它锁,此时,该连接可以对数据库进行修改,所有以前所缓存的修改都会被写到数据库文件中.
当某个连接拥有预留锁,而其它连接的共享锁始终无法被释放时,数据库会陷入死锁.

事务的类型
SQLite有三种不同的事务类型,它们以不同的锁状态启动事务.事务可以开始于:deferred,immediate,exclusive.事务类型在begin命令中指定:
**begin [deferred | immediate | exclusive] transaction;**
- deferred:直到必须使用时才获取锁;
对于延迟事务,begin语句本身不会做什么事情,它从未锁定状态开始,这是默认情况.如果仅仅使用begin开始一个事务,那么事务就是延迟的,停留在未锁定状态.多个连接可以在同一时刻未创建任何锁的情况下开始延迟事务,这种情况下,第一个对数据库的读操作获取共享锁,第一个对数据库的写操作试图获取预留锁.
- immediate:在begin执行时试图获取预留锁;
如果由begin开始的immediate事务获取预留锁成功,begin immediate保证没有其它的连接可以写数据库,这也导致了没有其它连接能成功启动begin immediate或者begin exclusive命令,当其它连接执行这些命令时SQLite会返回SQLITE_BUSY错误,但这些命令会不断尝试以确保它们最终能开始immediate事务.
- exclusive:在begin执行时试图获取排它锁;
如果由begin开始的exclusive事务获取排它锁成功,则保证了数据库中没有其它的活动连接.exclusive的工作方式和immediate工作方式类似.
事务类型使用的基本准则:如果使用的数据库没有其它连接,用begin就可以了,但如果使用的数据库还有其它对数据库进行写操作的连接,就需要使用begin immediate或者begin exclusive开始事务.