文章原创,最近更新:2018-06-20
1.什么是数据标注
2.常见的几种数据标注类型
3.数据标注的过程
4.数据标注产品的设计
5.案例1
6.案例2
参考链接:
1、 小学生也能懂AI——白话监督学习
2、AI产品经理需要了解的数据标注工作入门
3、谈谈人工智能数据标注那些事
前言:通过网上找的文章,通过归纳总结具体如下:
1.什么是数据标注
首先谈谈什么是数据标注。数据标注有许多类型,如分类、画框、注释、标记等等,我们会在下面详谈。
要理解数据标注,得先理解AI其实是部分替代人的认知功能。回想一下我们是如何学习的,例如我们学习认识苹果,那么就需要有人拿着一个苹果到你面前告诉你,这是一个苹果。然后以后你遇到了苹果,你才知道这玩意儿叫做“苹果”。
类比机器学习,我们要教他认识一个苹果,你直接给它一张苹果的图片,它是完全不知道这是个啥玩意的。我们得先有苹果的图片,上面标注着“苹果”两个字,然后机器通过学习了大量的图片中的特征,这时候再给机器任意一张苹果的图片,它就能认出来了。
这边可以顺带提一下训练集和测试集的概念。训练集和测试集都是标注过的数据,还是以苹果为例子,假设我们有1000张标注着“苹果”的图片,那么我们可以拿900涨作为训练集,100张作为测试集。机器从900张苹果的图片中学习得到一个模型,然后我们将剩下的100张机器没有见过的图片去给它识别,然后我们就能够得到这个模型的准确率了。想想我们上学的时候,考试的内容总是不会和我们平时的作业一样,也只有这样才能测试出学习的真正效果,这样就不难理解为什么要划分一个测试集了。
我们知道机器学习分为有监督学习和无监督学习。无监督学习的效果是不可控的,常常是被用来做探索性的实验。而在实际产品应用中,通常使用的是有监督学习。有监督的机器学习就需要有标注的数据来作为先验经验。
在进行数据标注之前,我们首先要对数据进行清洗,得到符合我们要求的数据。数据的清洗包括去除无效的数据、整理成规整的格式等等。具体的数据要求可以和算法人员确认。
2.常见的几种数据标注类型
1.分类标注:分类标注,就是我们常见的打标签。一般是从既定的标签中选择数据对应的标签,是封闭集合。如下图,一张图就可以有很多分类/标签:成人、女、黄种人、长发等。对于文字,可以标注主语、谓语、宾语,名词动词等。
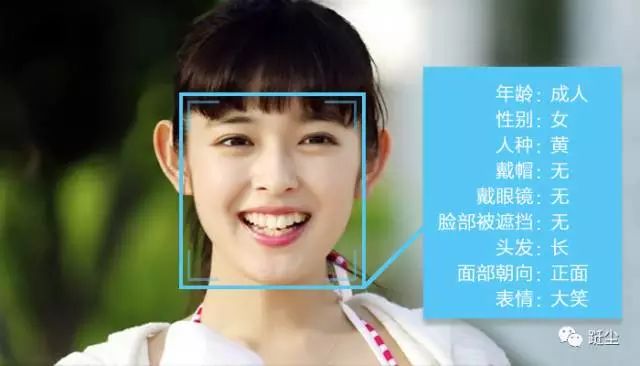
适用:文本、图像、语音、视频
应用:脸龄识别,情绪识别,性别识别
2.标框标注:机器视觉中的标框标注,很容易理解,就是框选要检测的对象。如人脸识别,首先要先把人脸的位置确定下来。行人识别,如下图。

适用:图像
应用:人脸识别,物品识别
3.区域标注:相比于标框标注,区域标注要求更加精确。边缘可以是柔性的。如自动驾驶中的道路识别。

适用:图像
应用:自动驾驶
4.描点标注:一些对于特征要求细致的应用中常常需要描点标注。人脸识别、骨骼识别等。

适用:图像
应用:人脸识别、骨骼识别
5.其他标注:标注的类型除了上面几种常见,还有很多个性化的。根据不同的需求则需要不同的标注。如自动摘要,就需要标注文章的主要观点,这时候的标注严格上就不属于上面的任何一种了。(或则你把它归为分类也是可以的,只是标注主要观点就没有这么客观的标准,如果是标注苹果估计大多数人标注的结果都差不多。)
3.数据标注的过程
3.1标注标准的确定
确定好标准是保证数据质量的关键一步,要保证有个可以参照的标准。一般可以:
设置标注样例、模版。例如颜色的标准比色卡。
对于模棱两可的数据,设置统一处理方式,如可以弃用,或则统一标注。
参照的标准有时候还要考虑行业。以文本情感分析为例,“疤痕”一词,在心理学行业中,可能是个负面词,而在医疗行业则是一个中性词。
3.2标注形式的确定
标注形式一般由算法人员制定,例如某些文本标注,问句识别,只需要对句子进行0或1的标注。是问句就标1,不是问句就标0。
3.3标注工具的选择
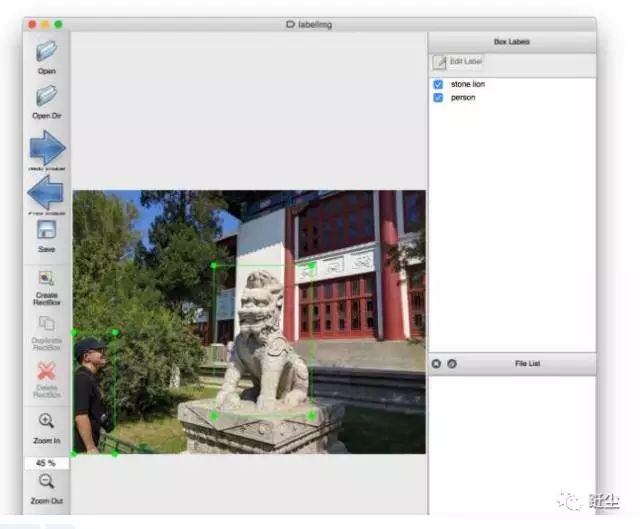
标注的形式确定后,就是对标注工具的选择了。一般也是由算法人员提供。大公司可能会内部开发一个专门用于数据标注的可视化工具。如:

也有使用开源的数据标注工具的,如推荐 Github 上的小工具labelImg
4.数据标注产品的设计
谈谈设计数据标注工具的几个小技巧。

一个数据标注工具一般包含:
- 进度条:用来指示数据标注的进度。标注人员一般都是有任务量要求的,一方面方便标注人员查看进度,一方面方便统计。
- 标注主体:这个可以根据标注形式进行设计,原则上是越简洁易用越好。根据标注所需要的注意力可以分为单个标注和多个标注的形式,可根据需求选择。
- 数据导入导出功能:如果你的标注工具是直接数据对接到模型上的,可以不需要。
- 收藏功能:这个可能是没有接触过数据标注的不会想到。标注人员常常会出现的一种情况就是疲劳,或者是遇到了那种模棱两可的数据,则可以先收藏,等后面再标。
- 质检机制:在分发数据的时候,可以随机分发一些已经标注过的数据,来检测标注人员可靠性。
5.案例1
机器学习主要用来做预测,也就是从已有的数据推测出新数据所具有的属性。预测有很多不同的方法,今天就带大家来了解下一种最常用的方法——监督学习。既然有监督学习,那自然也有无监督学习,更详细点,还有半监督学习。它们直接主要的区别,就在于是否有标注。什么是标注呢?
举个萌萌的例子。
你的院子里生活着一些可爱的猫咪,它们长的各不相同,有胖的,有瘦的,有花的。你很关心哪些猫咪比较亲人,可以让你随意撸。通过观察,你记录下了每一只猫咪的脾性:小黑猫——高冷;胖花猫——给吃就给撸;小白猫——粘人……这就是标注,给已有的数据打好标签或分好类。监督学习便会使用这些已经标注的数据。

而相对的,无监督学习就是没有对数据打标签的,你是不知道小黑猫高冷小白猫粘人这样的对应信息的。你只是根据这些猫咪可能有价值的共同点将它们聚在一起而已,因此无监督学习也会被称为聚类。从实际应用上来说,因为目的性不强,无监督学习的效果比监督学习要差很多。但由于监督学习所需的标注成本,在某些情况下很高,因此无监督的方法还是具有存在的意义的。
监督学习分为两个步骤:学习过程和预测过程,而将这两个过程联系起来的,则是所谓的『模型』。学习过程就是使用标注好的数据,通过某些方法,得到模型。之后当对新的数据进行预测的时候,则可使用学习过程中获得的模型,将新数据作为输入,将得到的输出作为预测结果。

还拿猫咪举例子。在学习过程中,首先要获得带标注的数据,而这一步很多情况下是需要人来参与的。比如你需要自己去观察记录猫咪的性格特点,并将这些数据整理为学习用数据集,即训练数据,表示为:
训练数据={{小黑猫,高冷},{胖花猫,给吃就给撸},{小白猫,粘人}}
(T={{x1,y1},{x2,y2}…{xN,yN})
而每只猫咪身上,又会包含多种属性(N维特征向量),可以表示为:
猫咪属性={身材,花色,年纪}(x={x(1), x(2)…x(n)})
将属性对应到具体猫身上,便为:
小黑猫={瘦,黑,5岁}(x1={x1(1),x1(2)…x1(n))
当我们拥有了这些数据,就可以计算出『模型』。而所谓的『模型』,一般来说是一个决策函数(y=f(x))或一个条件概率(p(y|x))。对于猫咪事件来说,就是类似『年纪小的猫粘人』或『当猫的年纪小于2岁时,66%的概率是粘人的』这样的判断句。
当得到这样的结论(模型)后,就可以进入预测过程了。当新的小花猫跑入院内,你发现它年纪小于2岁,那么就可以认为它大概率是粘人的。这也说明,很多情况下,预测往往只是提供一个概率,一个最可能的情况,而非一个准确的判断。
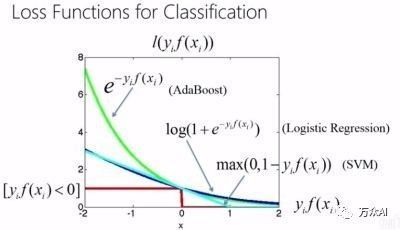
错误衡量的方式(损失函数)有很多种,最简单的方法是,当判断错误了,记为1,当判断正确了,记为0。那么用5只猫来测试,使用『年纪小的猫粘人』这个模型判断,有4只都符合这个结论,1只不符合,那么错误率就是1/5;使用『花色浅的猫粘人』这个模型判断,有3只符合2只不符合,那么错误率是2/5,大于『年纪小的猫粘人』的错误率,因此『年纪小的猫粘人』为最优的模型。
常见的损失函数如下:
1)0-1损失函数
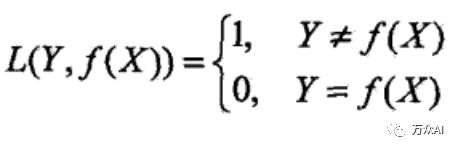
2)平方损失函数
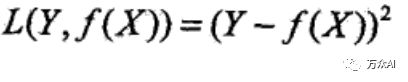
3)绝对损失函数

4)对数损失函数

在更一般的情况下,每一组数据的损失和这组数据发生的概率也是相关的,需要在考虑数据发生概率的情况下,将所有结果累积起来,最终的结果,才是全部数据的整体误差,即损失期望(如下)当此值越小,则说明模型越优。
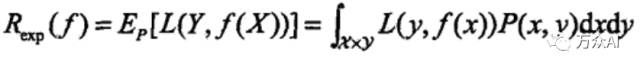
这里不得不提到所谓的『泛化能力』。在学习过程中,使用训练数据作为输入与输出,可以获得与模型相关的代表错误程度的值。而在预测过程中,也可以得到这样一个值。由于机器学习的目的就是为了进行预测,因此是预测中的错误程度值越小越好,而非学习过程中的。而泛化能力就是描述预测过程中错误程度的。预测过程误差越小,泛化能力越大。而评估泛化能力,一般是考虑损失期望的上界,而此与训练数据集的平均误差密切相关。
这里不得不提到所谓的『泛化能力』。在学习过程中,使用训练数据作为输入与输出,可以获得与模型相关的代表错误程度的值。而在预测过程中,也可以得到这样一个值。由于机器学习的目的就是为了进行预测,因此是预测中的错误程度值越小越好,而非学习过程中的。而泛化能力就是描述预测过程中错误程度的。预测过程误差越小,泛化能力越大。而评估泛化能力,一般是考虑损失期望的上界,而此与训练数据集的平均误差密切相关。
而在选择最优模型的过程中很容易出现『过拟合』的问题,也就是过于追求模型在训练数据中的准确度,模型和训练数据太过匹配从而无法对新的数据进行预测。试想,在猫咪例子中,将模型定为『小白猫粘人』,那么对于已有的所有猫咪(训练数据),这个模型的准确度为100%。但是其完全无法进行任何预测,因为其只针对小白猫,而无法处理大部分其他种类的猫。
这种情况一般通过在损失期望后增加『惩罚值』来避免,惩罚值和模型的复杂度密切相关,也就是如果模型过于细致,如相关条件已经精确到『小白猫』的程度了,那么惩罚值会更大,从而增加损失期望,以此来降低模型的优越程度。
以上就是监督学习的基本过程,获得最优模型后就可以进行预测了。
6.案例2
数据可分为两种类型:“被标记过”的数据和“未被标记过”的数据。什么是标记呢?意同“贴标签”,当你看到一个西瓜,你知道它是属于水果。那么你就可以为它贴上一个水果的标签。算法同事用“有标签的数据”去训练模型,这里就有了“监督学习”。
重点就是这里:只要是跟“监督学习”沾边的产品/技术,比如图像识别、人脸识别、自然语言理解等等,他们都有一个必走的流程(如下图)不断地用标注后的数据去训练模型,不断调整模型参数,得到指标数值更高的模型。

6.1模型测试
一般来说模型测试至少需要关注两个指标:
1.精确率:识别为正确的样本数/识别出来的样本数
2.召回率:识别为正确的样本数/所有样本中正确的数
举个栗子:全班一共30名男生、20名女生。需要机器识别出男生的数量。本次机器一共识别出20名目标对象,其中18名为男性,2名为女性。则
精确率=18/(18+2)=0.9
召回率=18/30=0.6
再补充一个图来解释:

而且,模型的效果,需要在这两个指标之间达到一个平衡。