「Item-Based Collaborative Filtering Recommendation Algorithms」是协同过滤的经典paper,其扩展算法广泛应用于推荐系统中,虽然是2001年的文章,但其思路清晰、行文流畅、论证充分,是值得精读的好文章。建议各位直接读原版,但可以先对各种翻译版本做一些概览,减少理解成本。
概要ABSTRACT
基于KNN(K-Nearest-Neighbor)的推荐系统在互联网领域被广泛应用,但因浏览量和信息量的暴增对于这套系统提出挑战,主要表现在数据越来越稀疏、推荐准确度和时效性越来越强(每秒百万级)。
本篇paper会对于item-based的推荐算法作对比分析,包括不同相似度的对比(cosine/Adjusted cosine/相关系数correlation),不同推荐计算方式(加权求和 weighted sum& 回归模型 regression)。最后会通过实验说明相比KNN的提升,可证明item-based 优于现行最优(available)user_based的方法。
1.引言INTRODUCTION
user_based(现行)推荐算法面临两大挑战:
1.实时可扩展(scalability):用户量从万->千万级别的暴增,以及用户对于商品的访问行为暴增,使得秒级处理越来越困难
2.推荐准确度:用户对于不准确的推荐越来越反感。
准确与实时是两个矛盾(conflict)的方面,瓶颈在于用户*商品的矩阵过大,而item-based方法可以规避大计算量。因为商品之前的相似度是相对固定(static)的,而且可以采用部分样本来推广全局(后续会计算多少比例合适)。
1.1 前人工作成果Related Work
贝叶斯网络(Bayesian Network),基于训练集在每个节点上建立决策树DT,边edge代表用户信息。建模需要小时或天级,精度接近KNN,适合更新要求不高的场景。
聚类(Clustering),将相似人群聚集,根据组内其他人群的平均表现进行推荐。缺点是推荐结果不太个性化(personal),而且对于边缘用户的推荐有较大误差。通常用于KNN方法的第一步分组。
Horting,基于图的推荐(graph-based),用户是点(node)用户关系是边(edge),复用与该人有连接的user推荐。与KNN不同的是,这个人不一定有评价过相同商品,推荐表现可以更优。
1.2 本文贡献Contributions
1.分析(analyze)item-based的预测算法,并提出不同的计算子任务(subtask)
2.提出相似度的提前计算模型(precomputed model)来提升在线推荐的扩展性/实时(scalability)
3.实验对比不同的item-based和user_based的结果差异
1.3 论述结构
第二章引入协同过滤背景,并正式介绍常规计算过程,包括两个变种:memory-based和module-based,说明前者面临的挑战有哪些;第三章介绍item-based算法,并将子任务的公式和计算方式说清楚;第四章是实验,包括数据集、评价指标、方法论、结果和讨论;第五章是总结和未来探索方向。
2.基于协同过滤的推荐系统COLLABORATIVE FILTERING BASED RECOMMENDER SYSTEM
2.0.1 协同过滤概览
基于人U={u1,u2,...um}和物品I={i1,i2,...,in}之间,每个ui对应的物品Iui,会输出两种计算结果:
预测值/评分Prediction: Pa,j代表用户ua对于物品ij的喜爱程度(ij不属于Iua),预测值与之前评分范围一致。
推荐Recommendation: N个被推荐物品集合Ir,Ir没有被ua购买过。

user-item矩阵A,元素Aij代表用户i对于物品j的评分,有两种推荐计算方式:
memory-based(user_based):优化整个user-item矩阵,先找到一群邻居(可以是对不同物品的近似评价或购买相似商品),然后根据邻居的喜好来推出TopN商品,被称为“近邻算法”or"user-based"算法,应用广泛。
model-based:对于用户评分建立一套模型,包括贝叶斯网络(Bayesian nework)来计算概率、聚类(Clustering)对用户分群、基于规则(rule-based)是通过发现商品被共同购买的规律来。
2.0.2 基于用户的算法面临挑战
1.稀疏性(Sparsity):人群和商品的爆炸,比如亚马逊可能有百万级的商品,但是一个人能发生行为的不足1%,利用临近算法推荐效果差。
2.扩展性(Scalability):行列扩展,计算量呈平方式暴增
解决问题的有效尝试包括,LSI(Latent Semantic Indexing)隐语义模型来降维。本文是引入item-based方法,出发点是一个人会倾向于购买与自己早期交易过的物品关联度高的商品,而早期不喜欢的商品相似度高的物品现在也不会喜欢。接下来会详细介绍。
3. 基于商品的协同过滤推荐算法 ITEM-BASED COLLABORATIVE FILTERING ALGORITHM
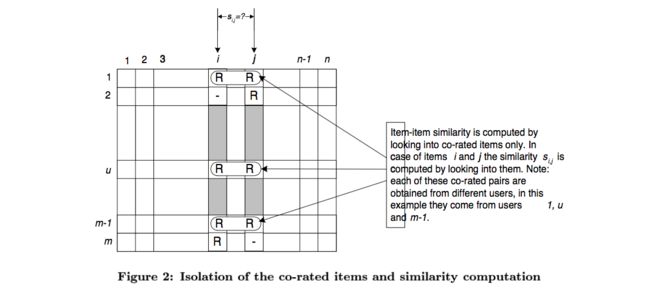
3.1 物品相似度计算
计算物品相似度是item-based算法中最关键的一步,m个用户是行,n个商品是列,物品i和j之间的相似度是通过对他们的评分记录来算。计算相似度有如下三种方式:
3.1.1 余弦相似度Cosine-based Similarity
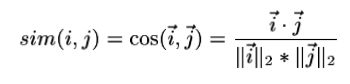
这里两个物品i和j被看做是两个m维向量(m是用户数),相似度是两个向量的夹角余弦值。Sij代表相似度。
3.1.2 相关系数相似度 Correlation-Based Similarity

通过皮尔森相关系数Pearson,U代表对于物品i和j都评价过的用户集合。相关系数是Ri非(上面一横)是代表i物品的评价期望
3.1.3修正相似度 Adjusted Cosine Similarity
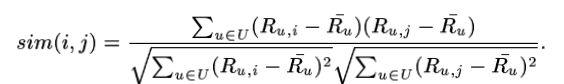
余弦相似度相比user_based的算法有个最大的问题(drawback)是没有考虑不同用户的评分范围(scale)差异。即用户A可能都是打3分以上,用户B都是打3分以下,评价标准不同。为了考虑这个因素,余弦考虑增加Ru非(上面一横)来只看增量,消除人与人之间的差距。
3.2 预测值计算
3.2.1 加权平均Weighted Sum

计算用户u对于物品i的推荐,是计算跟i相似的物品与其相似度的加权平均值。通过除法来时的预测值和真实评分处于同一范围。
3.2.2 回归 Regression
文中原因是余弦或者相关系数计算出来的距离可能很远(欧氏距离),但实际上可能很近,会造成结果不精准。所以采用Rn来代替Ri,计算出真实距离。(注释:实际上归一化的欧氏距离和余弦计算,是可以有效规避这个欧氏距离与实际距离不相同的情况,回归模型的存在意义不是很理解。)
3.3 性能表现
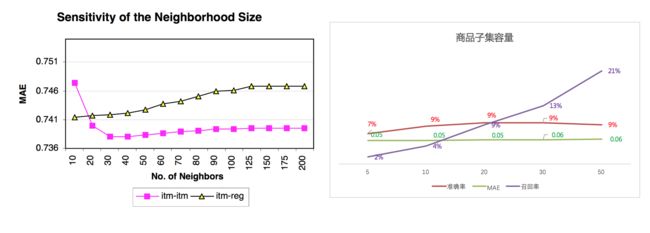
user_based的计算瓶颈在于矩阵太大,实时计算不现实;item-based是提前计算好,但计算量没有变少,对于n个物品计算复杂度O(n^2)。这种方案是对于物品j,仅保留其最相关的k个(k< 采用MovieLens的100K数据集(下载链接),943用户*1682电影的共10W条记录,稀疏度 (1-非零点/所有评价)=(1-100000/943*1682)=0.9369。 (1) 统计指标:此处采用平均绝对误差MAE,值越小越精准。均方根误差RMSE也可用。 (2)决策指标:2.5以下是不选,4以上是选。 实验步骤:先区分训练集和测试集;在正式开始实验之前,对于训练集上利用10-fold交叉验证,对不同计算方式和不同参数进行对比,确定最优组合。 benchmark/user_based:采用Pearson系数的近邻计算。 实验平台:文中是C语言,600MHZ/2GB内存的奔腾III的Linux机器上(本次采用python2.7在阿里云上运行) 实验结果包括效果指标(quality/推荐准确)和性能指标(performance/计算速度),在评价效果之前,需要对参数敏感性进行校正,包括近邻size、训练和测试集比例x、不同相似度的计算。对这些指标计算限于训练集。 论文原作者计算,根据MAE(作图Figure 4)来看是Adjusted-Cosine最优。通过手写代码实践,TopN推荐且测试集比例20%,Jaccard的准确率最高9%(MAE这里表现比较奇怪);如果是全量推荐,则Cosine/Adjusted-Cosine/Pearson准确率12%近似,Jaccard反而表现最差。常见应用场景是TopN的商品推荐(如电商推荐商品受位置限制),故以Jaccard推荐做base来继续实验(原文是基于Adjusted-Cosine) 原始是从Adjusted-Cosine测试集x=0.2开始,MAE持续下降;通过手工测算Jaccard,在x=0.2-0.4之间的准确率和召回率最高。 商品子集,原文的MAE在10->20之间发生大规模下降,之后维持稳定;手工测算发现「准确率」变化不大,MAE一再在提升。 原文概述item-based方法比user_based方法优秀。 原文代表请参考github:https://github.com/lichald/CF 运行环境:Anacoder/py 27/MBP 8G内存 关于手写代码,没有对regrssion的推荐做计算、未对比user_based和item-basde的区别。因计算结果与原文不一致,请各位发现我代码中问题在讨论区留言,互相提高。 数据集链接:下载链接4.实验评估 EXPERIMENTAL EVALUATION
4.1 数据集
4.2 评价指标
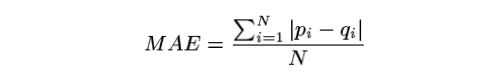
4.2.1 实验过程
4.3 实验结果
4.3.1 相似度对比
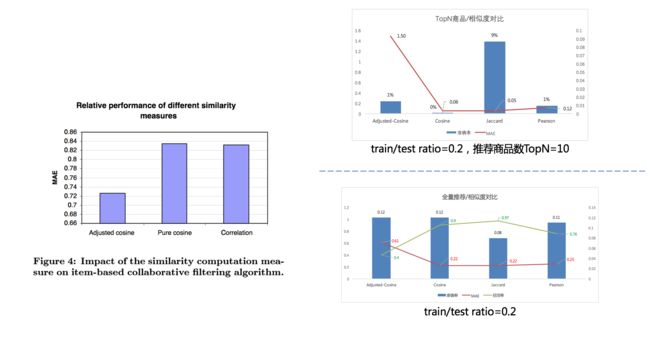
4.3.2 训练和测试集合比例

4.3.3 商品子集容量size
5. 结论 CONCLUSION
基于amazon.com的类似文章《Amazon.com Recommendations item-to-item collaborative filtering》的结论,user_based方法实时计算不现实,cluster计算推荐效果粗糙(同一类人群的推荐一致),search-based方式是推荐效果无趣(基于同一主题或同一作者)。只有item-based方式,线上实时计算时间可接受(离线已计算数据),且推荐效果还不错。附录:手写代码