关键词是指能反映文本主题或者主要内容的词语。关键词提取是NLP领域的一个重要的子任务。在信息检索中,准确的关键词提取可以大幅提升效率;在对话系统中,机器可以通过关键词来理解用户意图;在文本分类中,关键词的发现也非常有帮助。
关键词提取的方法主要有:TF-IDF、TextRank、Rake、Topic-Model等。
TF-IDF
TF-IDF的基本思想是:词语的重要性与它在文件中出现的次数成正比,但同时会随着它在语料库中出现的频率成反比下降。
一个文档中多次出现的词总是有一定的特殊意义,但是并不是所有多次出现的词就都是有意义的,如果一个词在所有的文档中都多次出现,那么这个词就没有什么价值了。或者说,如果某个词或者短语在一个文档中出现多次,但是在其他文档中很少出现,就可以认为这个词或短语具有很好的区分性,适合用来对文档进行分类。

TF(Term Frequency)表示一个词在文档中出现的次数。
DF(Document Frequency)表示整个语料库中含有某个词的文档个数
IDF(Inverse Document Frequency)为逆文档频率,其计算公式为:
IDF= log(语料库中文档总数/(包含该词的文档数+1))
+1 的作用是确保分母不为零。
TF-IDF = TF * IDF
由公式可知:一个词在文档中出现的次数越多,其TF值就越大,整个语料库中包含某个词的文档数越少,则IDF值越大,因此某个词的TF-IDF值越大,则这个词是关键词的概率越大。
TF-IDF关键词提取算法的一大缺点是:为了精确的提取一篇文档中的关键词,需要有一整个语料库来提供支持。这个问题的解决方法,通常是在一个通用的语料库上提前计算好所有词的IDF值,jieba就是这么做的。这样的解决方案对于普通文档关键词提取有一定的效果,但是对于专业性稍微强一点的文档,表现就会差很多。
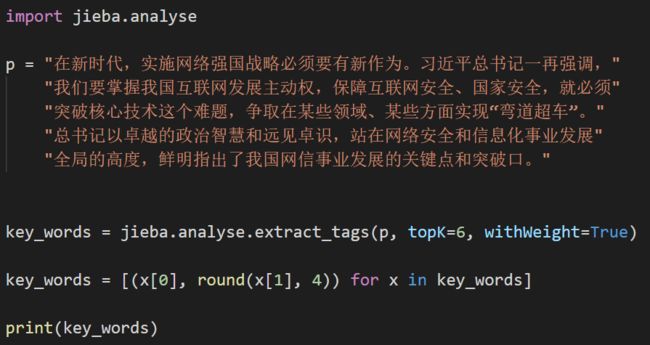
jieba中的已经有TF-IDF关键词提取算法的实现。使用jieba中的TF-IDF关键词提取算法的代码如下:
Rake
Rake的英文全称是Rapid Automatic Keyword Extraction。
Rake算法引入了一个degree(度)的概念,并且对词和短语不做任何区分,因此,它实际上是不仅仅是在提取关键词,也是在提取关键短语。
关于Rake中引入的degree,它其实是图论中的一个概念。在一张图上,任一顶点的degree(度)是指与该顶点相关联的边的条数。在Rake算法中,一个词的degree其实就是它在整个文档中的非重复共现词的数量。
举个例子来说明degree的计算。比如在 “我要买一个小米手机,因为大家都说小米手机很好用!”中,“小米”这个词出现了两次,共现词分别是 【一个,手机,说,手机】,因此,在这句话中,“小米”这个词的degree就是3。
使用Rake算法进行关键词提取不需要一整个语料库的支持,相比于TF-IDF,这是一个很大的优势。
Rake算法的输入参数有三个:1)停用词表(stop words);2)段落分割符;3)词语分割符。针对同一种语言,这三个参数事实上是一样的。
使用Rake算法进行关键词(短语)提取的过程如下:
step 1. 从输入文本中获取候选关键词(candidate keywords)
step 2. 计算所有候选关键词的得分,公式如下:
score = sum(deg(w)/freq(w))
step 3. 拼接候选关键词(以同样的顺序相邻出现两次),获取带有停用词的关键词
step 4. 输出得分最高的前T个候选关键词作为关键词,作者的做法是输出前三分之一
Rake算法的实现,请点击:https://github.com/zelandiya/RAKE-tutorial
TextRank
关于TextRank算法,之前写过一篇,点击直达
参考资料
1、ROSE S, ENGEL D, CRAMER N等. Automatic Keyword Extraction from Individual Documents[G]//Text Mining. Wiley-Blackwell, 2010: 1–20.
2、关键词提取方法学习总结(TF-IDF、Topic-model、RAKE)
3、用 RAKE 和 Maui 做 NLP 关键词提取的教程
4、https://github.com/zelandiya
5、自然语言处理系列篇——关键词智能提取