原理介绍
TimSort是结合了合并排序(合并排序)和插入排序(插入排序)而得出的排序算法,它在现实中有很好的效率.Tim Peters在2002年设计了该算法并在Python中使用是Python中list.sort的默认实现)。该算法找到数据中已经排好序的块 - 分区,每一个分区叫一个run,然后按规则合并这些run.Pyhton自从2.3版本以后一直采用Timsort算法排序,现在Java SE7和Android也采用Timsort算法对数组排序。
内容
1操作
2性能
3JDK源码
Timsort核心的过程
TimSort算法为了减少对升序部分的回馈和对降序部分的性能倒退,将输入按其升序和降序特点进行了分区。每次合并会将两个运行合并成一个运行。合并的结果保存到栈中。合并直到消耗掉所有的运行,这时将栈上剩余的跑合并到只剩一个跑为止。这时这个仅剩的跑便是排好序的结果。
综上述过程,Timsort算法的过程包括
(0)如何数组长度小于某个值,直接用二分插入排序算法
(1)找到各个运行,并入栈
(2)按规则合并运行
1操作
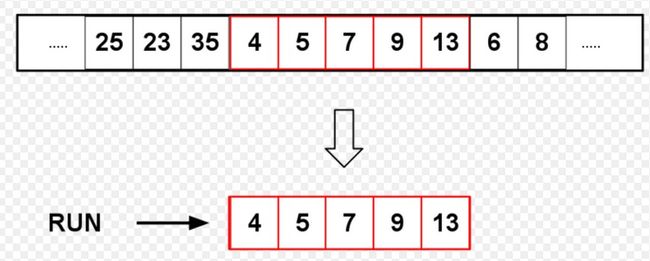
现实中的大多数据通常是有部分已经排好序的,Timsort利用了这一特点.Timsort排序的输入的单位不是一个个单独的数字,而是一个个的分区。其中每一个分区叫一个“运行“(图1)。针对这个run序列,每次拿一个run出来进行归并。每次归并会将两个run合并成一个run。每个run最少要有2个元素.Timesor按照升序和降序划分出每个run:run如果是是升序的,那么运行中的后一元素要大于或等于前一元素(a [lo] <= a [lo + 1] <= a [lo + 2] <= ... );如果run是严格降序的,即运行中的前一元素大于后一元素(a [lo]> a [lo + 1]> a [lo + 2]> ...),需要将run中的元素翻转(这里注意降序的部分必须是“严格”降序才能进行翻转。因为TimSort的一个重要目标是保持稳定性的稳定性。如果在这种情况下进行翻转这个算法就不稳定)。
1.1跑的最小长度
运行是已经排好序的一块分区.RUN可能会有不同的长度,Timesort根据运行的长度来选择排序的策略。例如如果运行的长度小于某一个值,则会选择插入排序算法来排序。运行的最小长度(minrun)取决于数组的大小。当数组元素少于64个时,那么运行的最小长度便是数组的长度,这是Timsort用插入排序算法来排序。当数组元素大于等于63时,对于较大的阵列中,从32到65的范围内选择一个称为minrun的数,使得阵列的大小除以最小游程大小,等于或略小于2的幂。最终的算法只需要数组大小的6个最高有效位,如果剩余的位被设置,则添加一个,并将该结果用作minrun。该算法适用于所有情况,包括数组大小小于64的情况。
1.2优化运行的长度
优化运行的长度是指当运行的长度小于minrun时,为了使这样的运行的长度达到minrun的长度,会从数组中选择合适的元素插入运行中。这样做使大部分的运行的长度达到均衡,有助于后面运行的合并操作。
1.3合并运行
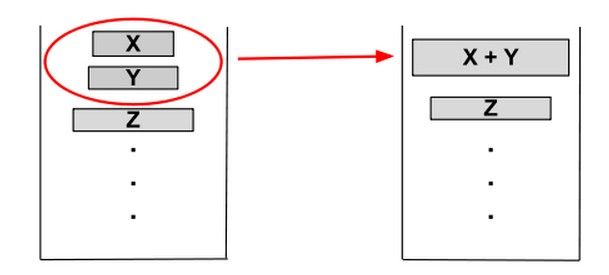
划分run和优化run长度以后,然后就是对各个run进行合并。合并run的原则是run合并的技术要保证有最高的效率。当Timsort算法找到一个run时,会将该run在数组中的起始位置和运行的长度放入栈中,然后根据先前放入栈中的运行决定是否该合并run.Timsort不会合并在栈中不连续的运行(Timsort不会合并非连续运行,因为这样做会导致三条跑道的共同要素相对于中跑来说是失序的。)
Timsort会合并在栈中2个连续的run.X,Y,Z代表栈最上方的3个游程的长度(图2),当同时不满足下面2个条件是,X,Y这两个运行会被合并,直到同时满足下面2个条件,则合并结束:
(1)X> Y + Z
(2)Y> Z
例如:。如果X
1.4合并运行步骤
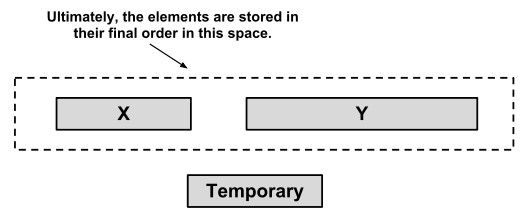
合并2个相邻的运行需要临时存储空闲,临时存储空间的大小是2个运行中较小的运行的大小.Timsort算法先将较小的运行复制到这个临时存储空间,然后用原先存储这2个运行的空间来存储合并后的运行(图3)。
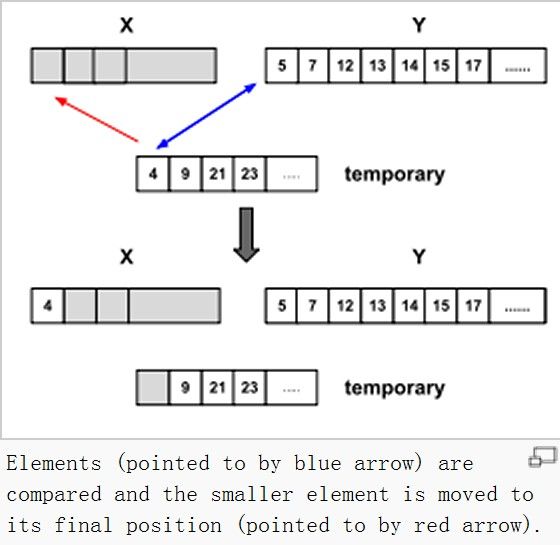
简单的合并算法是用简单插入算法,依次从左到右或从右到左比较,然后合并2个运行。为了提高效率,Timsort用 二分插入算法(二进制合并排序)。先用二分查找算法/折半查找算法(binary search)找到插入的位置,然后在插入。
例如,我们要将A和B这2个run合并,且A是较小的run。因为A和B已经分别是排好序的,二分查找会找到乙的第一个元素在一个中何处插入(图4)。同样,A的最后一个元素找到在乙的何处插入,找到以后,B在这个元素之后的元素就不需要比较了(图5)。这种查找可能在随机数中效率不会很高,但是在其他情况下有很高的效率。
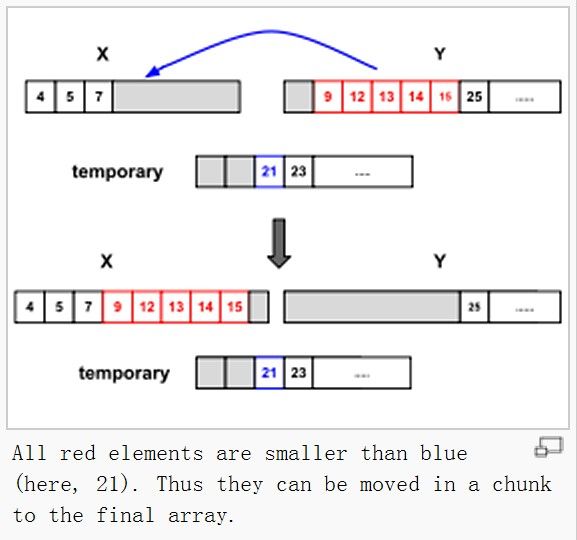
1.5舞动模型
介绍的是类似上述run的合并过程,参见 维基百科Galloping Model
2性能
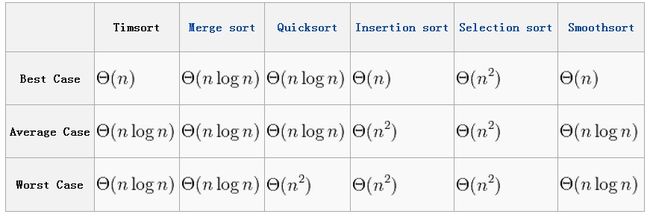
根据信息学理论,在平均情况下,比较排序不会比O(n log n)更快。由于Timsort算法利用了现实中大多数数据中会有一些排好序的区,所以Timsort会比
O对于随机数没有可用利用的排好序的区,Timsort时间复杂度会是log(n!)。下表是Timsort与其他比较排序算法时间复杂度(time complexity)的比较。
空间复杂度(space complexities)比较
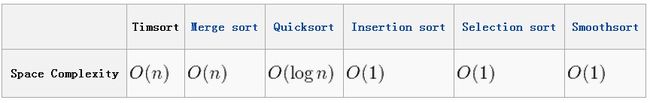
说明:
JSE 7对对象进行排序,没有采用快速排序,是因为快速排序是不稳定的,而Timsort是稳定的。
下面是JSE7中Timsort实现代码中的一段话,可以很好的说明Timsort的优势:
一个稳定的,自适应的迭代mergesort,在部分排序的数组上运行时,需要远远少于n lg(n)的比较,同时在随机数组上运行时性能堪比传统的mergesort。像所有合适的合并类型一样,这种类型是稳定的,并运行O(n log n)时间(最坏情况)。在最坏的情况下,这种类型需要临时存储空间来存放n / 2个对象引用; 在最好的情况下,它只需要很小的恒定空间。
大体是说,Timsort是稳定的算法,当前排序的数组中已经有排序好的数,它的时间复杂度会小于n logn。与其他合并排序一样,Timesrot是稳定的排序算法,最坏时间复杂在最坏情况下,Timsort算法需要的临时空间是n / 2,在最好情况下,它只需要一个很小的临时存储空间
3JDK源码
import java.util.Arrays;
import java.util.Comparator;
/**
* Created by yxf on 16-5-30.
* 这里对TimSort算法在java中的实现做了注释,部分实现逻辑相似的注释没有处理,直接是原来的注释。
*
*/
class TimSort {
/**
* 参与序列合并的最短长度。比这个更短的序列将会通过二叉插入排序加长。如果整个数组都比这个短,那就不会经过归并排序。
*
* 这个常量的值必须2的幂。Tim Perter 在C语言中的实现版本使用了64,但是根据经验这里的版本使用32更合适。在最坏的情况下,使用了非2的幂赋值,就必须要重写 {@link # minRunLength}这个方法。
* 如果减小了这个值,就需要在构造方法中减小stackLen的值,不然将面临数组越界的风险。
*/
private static final int MIN_MERGE = 32;
/**
* 将要被排序的数组
*/
private final T[] a;
/**
* 这次排序的比较器
*/
private final Comparator c;
/**
* 判断数据顺序连续性的阈值
* 后面结合代码看,会容易理解一点
*/
private static final int MIN_GALLOP = 7;
private int minGallop = MIN_GALLOP;
/**
* 归并排序中临时数组的最大长度,数组的长度也可以根据需求增长。
* 与C语言中的实现方式不同,对于相对较小的数组,我们不用这么大的临时数组。这点改变对性能有显著的影响
*/
private static final int INITIAL_TMP_STORAGE_LENGTH = 256;
/**
* 临时数组,根据泛型的内容可知,实际的存储要用Object[],不能用T[]
*/
private T[] tmp;
/**
* 栈中待归并的run的数量。一个run i的范围从runBase[i]开始,一直延续到runLen[i]。
* 下面这个根据前一个run的结尾总是下一个run的开头。
* 所以下面的等式总是成立:
* runBase[i] + runLen[i] == runBase[i+1];
**/
private int stackSize = 0; //栈中run的数量
private final int[] runBase;
private final int[] runLen;
/**
* 这个构造方法是私有的所以只能在类内部创建。
* 创建这个实例是为了保存一次排序过程中的状态变量。
*/
private TimSort(T[] a, Comparator c) {
this.a = a;
this.c = c;
// 这里是分配临时数组的空间。SuppressWainings是为了消除泛型数组转型的警告
// 临时数组的长度写的很精炼,不明白的自己熟悉一下java位操作。
// 结果就是 数组长度的一半或者是INITIAL_TMP_STORAGE_LENGTH
int len = a.length;
@SuppressWarnings({"unchecked", "UnnecessaryLocalVariable"})
T[] newArray = (T[]) new Object[len < 2 * INITIAL_TMP_STORAGE_LENGTH ?
len >>> 1 : INITIAL_TMP_STORAGE_LENGTH];
tmp = newArray;
/**
* 这里是分配储存run的栈的空间,它不能在运行时扩展。
* C语言版本中的栈一直使用固定值85,但这样对一些中小数组来说有些浪费资源。所以,
* 这个版本我们使用了相对较小容量的栈。
* 在MIN_MERGE减小的时候,这些‘魔法数’可能面临数组越界的风险。
* */
int stackLen = (len < 120 ? 5 :
len < 1542 ? 10 :
len < 119151 ? 24 : 40);
runBase = new int[stackLen];
runLen = new int[stackLen];
}
static void sort(T[] a, Comparator c) {
sort(a, 0, a.length, c);
}
static void sort(T[] a, int lo, int hi, Comparator c) {
if (c == null) {
Arrays.sort(a, lo, hi);
return;
}
rangeCheck(a.length, lo, hi);
int nRemaining = hi - lo;
if (nRemaining < 2)
return; // 长度是0或者1 就不需要排序了。
// 小于MIN_MERGE长度的数组就不用归并排序了,杀鸡焉用宰牛刀
if (nRemaining < MIN_MERGE) {
int initRunLen = countRunAndMakeAscending(a, lo, hi, c);
binarySort(a, lo, hi, lo + initRunLen, c);
return;
}
/**
* March over the array once, left to right, finding natural runs,
* extending short natural runs to minRun elements, and merging runs
* to maintain stack invariant.
*
* 下面将进入算法流程的主体,首先理解源码注释中run的含义,可以理解为升序序列的意思。
*
* 从左到右,遍历一边数组。找出自然排好序的序列(natural run),把短的自然升序序列通过二叉查找排序
* 扩展到minRun长度的升序序列。最后合并栈中的所有升序序列,保证规则不变。
*/
TimSort ts = new TimSort<>(a, c); //新建TimSort对象,保存栈的状态
int minRun = minRunLength(nRemaining);
do {
//跟二叉查找插入排序一样,先找自然升序序列
int runLen = countRunAndMakeAscending(a, lo, hi, c);
// If run is short, extend to min(minRun, nRemaining)
// 如果 自然升序的长度不够minRun,就把 min(minRun,nRemaining)长度的范围内的数列排好序
if (runLen < minRun) {
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen, c);
runLen = force;
}
// Push run onto pending-run stack, and maybe merge
//把已经排好序的数列压入栈中,检查是不是需要合并
ts.pushRun(lo, runLen);
ts.mergeCollapse();
//把指针后移runLen距离,准备开始下一轮片段的排序
lo += runLen;
//剩下待排序的数量相应的减少 runLen
nRemaining -= runLen;
} while (nRemaining != 0);
// Merge all remaining runs to complete sort
assert lo == hi;
ts.mergeForceCollapse();
assert ts.stackSize == 1;
}
/**
* 被优化的二分插入排序
*
* 使用二分插入排序算法给指定一部分数组排序。这是给小数组排序的最佳方案。最差情况下
* 它需要 O(n log n) 次比较和 O(n^2)次数据移动。
*
* 如果开始的部分数据是有序的那么我们可以利用它们。这个方法默认数组中的位置lo(包括在内)到
* start(不包括在内)的范围内是已经排好序的。
*
* @param a 被排序的数组
* @param lo 待排序范围内的首个元素的位置
* @param hi 待排序范围内最后一个元素的后一个位置
* @param start 待排序范围内的第一个没有排好序的位置,确保 (lo <= start <= hi)
* @param c 本次排序的比较器
*/
@SuppressWarnings("fallthrough")
private static void binarySort(T[] a, int lo, int hi, int start,
Comparator c) {
assert lo <= start && start <= hi;
//如果start 从起点开始,做下预处理;也就是原本就是无序的。
if (start == lo)
start++;
//从start位置开始,对后面的所有元素排序
for (; start < hi; start++) {
//pivot 代表正在参与排序的值,
T pivot = a[start];
// Set left (and right) to the index where a[start] (pivot) belongs
// 把pivot应当插入的设置的边界设置为left和right
int left = lo;
int right = start;
assert left <= right;
/*
* 保证的逻辑:
* pivot >= all in [lo, left).
* pivot < all in [right, start).
*/
while (left < right) {
int mid = (left + right) >>> 1;
if (c.compare(pivot, a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
assert left == right;
/**
* 此时,仍然能保证:
* pivot >= [lo, left) && pivot < [left,start)
* 所以,pivot的值应当在left所在的位置,然后需要把[left,start)范围内的内容整体右移一位
* 腾出空间。如果pivot与区间中的某个值相等,left指正会指向重复的值的后一位,
* 所以这里的排序是稳定的。
*/
int n = start - left; //需要移动的范围的长度
// switch语句是一条小优化,1-2个元素的移动就不需要System.arraycopy了。
// (这代码写的真是简洁,switch原来可以这样用)
switch (n) {
case 2:
a[left + 2] = a[left + 1];
case 1:
a[left + 1] = a[left];
break;
default:
System.arraycopy(a, left, a, left + 1, n);
}
//移动过之后,把pivot的值放到应该插入的位置,就是left的位置了
a[left] = pivot;
}
}
/**
* 这一段代码是TimSort算法中的一个小优化,它利用了数组中前面一段已有的顺序。
* 如果是升序,直接返回统计结果;如果是降序,在返回之前,将这段数列倒置,
* 以确保这断序列从首个位置到此位置的序列都是升序的。
* 返回的结果是这种两种形式的,lo是这段序列的开始位置。
*
* A run is the longest ascending sequence with:
*
* a[lo] <= a[lo + 1] <= a[lo + 2] <= ...
*
* or the longest descending sequence with:
*
* a[lo] > a[lo + 1] > a[lo + 2] > ...
*
* 为了保证排序的稳定性,这里要使用严格的降序,这样才能保证相等的元素不参与倒置子序列的过程,
* 保证它们原本的顺序不被打乱。
*
* @param a 参与排序的数组
* @param lo run中首个元素的位置
* @param hi run中最后一个元素的后面一个位置,需要确保lo int countRunAndMakeAscending(T[] a, int lo, int hi,
Comparator c) {
assert lo < hi;
int runHi = lo + 1;
if (runHi == hi)
return 1;
// 找出最长升序序的子序列,如果降序,倒置之
if (c.compare(a[runHi++], a[lo]) < 0) { // 前两个元素是降序,就按照降序统计
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) < 0)
runHi++;
reverseRange(a, lo, runHi);
} else { // 前两个元素是升序,按照升序统计
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) >= 0)
runHi++;
}
return runHi - lo;
}
/**
* 倒置数组中一段范围的元素
*
* @param a 指定数组
* @param lo 这段范围的起始位置
* @param hi 这段范围的终点位置的后一个位置
*/
private static void reverseRange(Object[] a, int lo, int hi) {
hi--;
while (lo < hi) {
Object t = a[lo];
a[lo++] = a[hi];
a[hi--] = t;
}
}
/**
* 返回参与合并的最小长度,如果自然排序的长度,小于此长度,那么就通过二分查找排序扩展到
* 此长度。{@link #binarySort}.
*
* 粗略的讲,计算结果是这样的:
*
* 如果 n < MIN_MERGE, 直接返回 n。(太小了,不值得做复杂的操作);
* 如果 n 正好是2的幂,返回 n / 2;
* 其它情况下 返回一个数 k,满足 MIN_MERGE/2 <= k <= MIN_MERGE,
* 这样结果就能保证 n/k 非常接近但小于一个2的幂。
* 这个数字实际上是一种空间与时间的优化。
*
* @param n 参与排序的数组的长度
* @return 参与归并的最短长度
* 这段代码写得也很赞
*/
private static int minRunLength(int n) {
assert n >= 0;
int r = 0; // 只要不是 2的幂就会置 1
while (n >= MIN_MERGE) {
r |= (n & 1);
n >>= 1;
}
return n + r;
}
/**
* Pushes the specified run onto the pending-run stack.
* 将指定的升序序列压入等待合并的栈中
*
* @param runBase 升序序列的首个元素的位置
* @param runLen 升序序列的长度
*/
private void pushRun(int runBase, int runLen) {
this.runBase[stackSize] = runBase;
this.runLen[stackSize] = runLen;
stackSize++;
}
/**
* 检查栈中待归并的升序序列,如果他们不满足下列条件就把相邻的两个序列合并,
* 直到他们满足下面的条件
*
* 1. runLen[i - 3] > runLen[i - 2] + runLen[i - 1]
* 2. runLen[i - 2] > runLen[i - 1]
*
* 每次添加新序列到栈中的时候都会执行一次这个操作。所以栈中的需要满足的条件
* 需要靠调用这个方法来维护。
*
* 最差情况下,有点像玩2048。
*/
private void mergeCollapse() {
while (stackSize > 1) {
int n = stackSize - 2;
if (n > 0 && runLen[n - 1] <= runLen[n] + runLen[n + 1]) {
if (runLen[n - 1] < runLen[n + 1])
n--;
mergeAt(n);
} else if (runLen[n] <= runLen[n + 1]) {
mergeAt(n);
} else {
break; // Invariant is established
}
}
}
/**
* 合并栈中所有待合并的序列,最后剩下一个序列。这个方法在整次排序中只执行一次
*/
private void mergeForceCollapse() {
while (stackSize > 1) {
int n = stackSize - 2;
if (n > 0 && runLen[n - 1] < runLen[n + 1])
n--;
mergeAt(n);
}
}
/**
* 在一个序列中,将一个指定的key,从左往右查找它应当插入的位置;如果序列中存在
* 与key相同的值(一个或者多个),那返回这些值中最左边的位置。
*
* 推断: 统计概率的原因,随机数字来说,两个待合并的序列的尾假设是差不多大的,从尾开始
* 做查找找到的概率高一些。仔细算一下,最差情况下,这种查找也是 log(n),所以这里没有
* 用简单的二分查找。
*
* @param key 准备插入的key
* @param a 参与排序的数组
* @param base 序列范围的第一个元素的位置
* @param len 整个范围的长度,一定有len > 0
* @param hint 开始查找的位置,有0 <= hint <= len;越接近结果查找越快
* @param c 排序,查找使用的比较器
* @return 返回一个整数 k, 有 0 <= k <=n, 它满足 a[b + k - 1] < a[b + k]
* 就是说key应当被放在 a[base + k],
* 有 a[base,base+k) < key && key <=a [base + k, base + len)
*/
private static int gallopLeft(T key, T[] a, int base, int len, int hint,
Comparator c) {
assert len > 0 && hint >= 0 && hint < len;
int lastOfs = 0;
int ofs = 1;
if (c.compare(key, a[base + hint]) > 0) { // key > a[base+hint]
// 遍历右边,直到 a[base+hint+lastOfs] < key <= a[base+hint+ofs]
int maxOfs = len - hint;
while (ofs < maxOfs && c.compare(key, a[base + hint + ofs]) > 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs)
ofs = maxOfs;
// 最终的ofs是这样确定的,满足条件 a[base+hint+lastOfs] < key <= a[base+hint+ofs]
// 的一组
// ofs: 1 3 7 15 31 63 2^n-1 ... maxOfs
// lastOfs: 0 1 3 7 15 31 2^(n-1)-1 < ofs
// 因为目前的offset是相对hint的,所以做相对变换
lastOfs += hint;
ofs += hint;
} else { // key <= a[base + hint]
// 遍历左边,直到[base+hint-ofs] < key <= a[base+hint-lastOfs]
final int maxOfs = hint + 1;
while (ofs < maxOfs && c.compare(key, a[base + hint - ofs]) <= 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs)
ofs = maxOfs;
// 确定ofs的过程与上面相同
// ofs: 1 3 7 15 31 63 2^n-1 ... maxOfs
// lastOfs: 0 1 3 7 15 31 2^(n-1)-1 < ofs
// Make offsets relative to base
int tmp = lastOfs;
lastOfs = hint - ofs;
ofs = hint - tmp;
}
assert -1 <= lastOfs && lastOfs < ofs && ofs <= len;
/*
* 现在的情况是 a[base+lastOfs] < key <= a[base+ofs], 所以,key应当在lastOfs的
* 右边,又不超过ofs。在base+lastOfs-1到 base+ofs范围内做一次二叉查找。
*/
lastOfs++;
while (lastOfs < ofs) {
int m = lastOfs + ((ofs - lastOfs) >>> 1);
if (c.compare(key, a[base + m]) > 0)
lastOfs = m + 1; // a[base + m] < key
else
ofs = m; // key <= a[base + m]
}
assert lastOfs == ofs; // so a[base + ofs - 1] < key <= a[base + ofs]
return ofs;
}
/**
* 与gallopLeft相似,不同的是如果发现key的值与某些元素相等,那返回这些值最后一个元素的位置的
* 后一个位置
*
* @param key 需要查找待插入位置的那个值
* @param a 待排序的数组
* @param base 被查找的序列中第一个元素的位置
* @param len 被查找的序列的长度
* @param hint 开始查找的位置,0 <= hint < len.它越接近结果所在位置,查找越快。
* @param c 本次排序的比较器
* @return 一个整数 k, 满足0 <= k <= n 并且 a[b + k - 1] <= key < a[b + k]
*/
private static int gallopRight(T key, T[] a, int base, int len,
int hint, Comparator c) {
assert len > 0 && hint >= 0 && hint < len;
int ofs = 1;
int lastOfs = 0;
if (c.compare(key, a[base + hint]) < 0) {
// Gallop left until a[b+hint - ofs] <= key < a[b+hint - lastOfs]
int maxOfs = hint + 1;
while (ofs < maxOfs && c.compare(key, a[base + hint - ofs]) < 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs)
ofs = maxOfs;
// Make offsets relative to b
int tmp = lastOfs;
lastOfs = hint - ofs;
ofs = hint - tmp;
} else { // a[b + hint] <= key
// Gallop right until a[b+hint + lastOfs] <= key < a[b+hint + ofs]
int maxOfs = len - hint;
while (ofs < maxOfs && c.compare(key, a[base + hint + ofs]) >= 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs)
ofs = maxOfs;
// Make offsets relative to b
lastOfs += hint;
ofs += hint;
}
assert -1 <= lastOfs && lastOfs < ofs && ofs <= len;
/*
* Now a[b + lastOfs] <= key < a[b + ofs], so key belongs somewhere to
* the right of lastOfs but no farther right than ofs. Do a binary
* search, with invariant a[b + lastOfs - 1] <= key < a[b + ofs].
*/
lastOfs++;
while (lastOfs < ofs) {
int m = lastOfs + ((ofs - lastOfs) >>> 1);
if (c.compare(key, a[base + m]) < 0)
ofs = m; // key < a[b + m]
else
lastOfs = m + 1; // a[b + m] <= key
}
assert lastOfs == ofs; // so a[b + ofs - 1] <= key < a[b + ofs]
return ofs;
}
/**
* 合并在栈中位于i和i+1的两个相邻的升序序列。 i必须为从栈顶数,第二和第三个元素。
* 换句话说i == stackSize - 2 || i == stackSize - 3
*
* @param i 待合并的第一个序列所在的位置
*/
private void mergeAt(int i) {
//校验
assert stackSize >= 2;
assert i >= 0;
assert i == stackSize - 2 || i == stackSize - 3;
//内部初始化
int base1 = runBase[i];
int len1 = runLen[i];
int base2 = runBase[i + 1];
int len2 = runLen[i + 1];
assert len1 > 0 && len2 > 0;
assert base1 + len1 == base2;
/*
* 记录合并后的序列的长度;如果i == stackSize - 3 就把最后一个序列的信息
* 往前移一位,因为本次合并不关它的事。i+1对应的序列被合并到i序列中了,所以
* i+1 数列可以消失了
*/
runLen[i] = len1 + len2;
if (i == stackSize - 3) {
runBase[i + 1] = runBase[i + 2];
runLen[i + 1] = runLen[i + 2];
}
//i+1消失了,所以长度也减下来了
stackSize--;
/*
* 找出第二个序列的首个元素可以插入到第一个序列的什么位置,因为在此位置之前的序列已经就位了。
* 它们可以被忽略,不参加归并。
*/
int k = gallopRight(a[base2], a, base1, len1, 0, c);
assert k >= 0;
// 因为要忽略前半部分元素,所以起点和长度相应的变化
base1 += k;
len1 -= k;
// 如果序列2 的首个元素要插入到序列1的后面,那就直接结束了,
// !!! 因为序列2在数组中的位置本来就在序列1后面,也就是整个范围本来就是有序的!!!
if (len1 == 0)
return;
/*
* 跟上面相似,看序列1的最后一个元素(a[base1+len1-1])可以插入到序列2的什么位置(相对第二个序列起点的位置,非在数组中的位置),
* 这个位置后面的元素也是不需要参与归并的。所以len2直接设置到这里,后面的元素直接忽略。
*/
len2 = gallopLeft(a[base1 + len1 - 1], a, base2, len2, len2 - 1, c);
assert len2 >= 0;
if (len2 == 0)
return;
// 合并剩下的两个有序序列,并且这里为了节省空间,临时数组选用 min(len1,len2)的长度
// 优化的很细呢
if (len1 <= len2)
mergeLo(base1, len1, base2, len2);
else
mergeHi(base1, len1, base2, len2);
}
/**
* 使用固定空间合并两个相邻的有序序列,保持数组的稳定性。
* 使用本方法之前保证第一个序列的首个元素大于第二个序列的首个元素;第一个序列的末尾元素
* 大于第二个序列的所有元素
*
* 为了性能,这个方法在len1 <= len2的时候调用;它的姐妹方法mergeHi应该在len1 >= len2
* 的时候调用。len1==len2的时候随便调用哪个都可以
*
* @param base1 index of first element in first run to be merged
* @param len1 length of first run to be merged (must be > 0)
* @param base2 index of first element in second run to be merged
* (must be aBase + aLen)
* @param len2 length of second run to be merged (must be > 0)
*/
private void mergeLo(int base1, int len1, int base2, int len2) {
assert len1 > 0 && len2 > 0 && base1 + len1 == base2;
//将第一个序列放到临时数组中
T[] a = this.a; // For performance
T[] tmp = ensureCapacity(len1);
System.arraycopy(a, base1, tmp, 0, len1);
int cursor1 = 0; // 临时数组指针
int cursor2 = base2; // 序列2的指针,参与归并的另一个序列
int dest = base1; // 保存结果的指针
// 这里先把第二个序列的首个元素,移动到结果序列中的位置,然后处理那些不需要归并的情况
a[dest++] = a[cursor2++];
// 序列2只有一个元素的情况,把它移动到指定位置之后,剩下的临时数组
// 中的所有序列1的元素全部copy到后面
if (--len2 == 0) {
System.arraycopy(tmp, cursor1, a, dest, len1);
return;
}
// 序列1只有一个元素的情况,把它移动到最后一个位置,为了不覆盖,先把序列2中的元素
// 全部移走。这个是因为序列1中的最后一个元素比序列2中的所有元素都大,这是该方法执行的条件
if (len1 == 1) {
System.arraycopy(a, cursor2, a, dest, len2);
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
return;
}
Comparator c = this.c; // 本次排序的比较器
int minGallop = this.minGallop; // " " " " "
// 不了解break标签的同学要补补Java基本功了
outer:
while (true) {
/*
* 这里加了两个值来记录一个序列连续比另外一个大的次数,根据此信息,可以做出一些
* 优化
* */
int count1 = 0; // 序列1 连续 比序列2大多少次
int count2 = 0; // 序列2 连续 比序列1大多少次
/*
* 这里是直接的归并算法的合并的部分,这里会统计count1合count2,
* 如果其中一个大于一个阈值,就会跳出循环
* */
do {
assert len1 > 1 && len2 > 0;
if (c.compare(a[cursor2], tmp[cursor1]) < 0) {
a[dest++] = a[cursor2++];
count2++;
count1 = 0;
// 序列2没有元素了就跳出整次合并
if (--len2 == 0)
break outer;
} else {
a[dest++] = tmp[cursor1++];
count1++;
count2 = 0;
// 如果序列1只剩下最后一个元素了就可以跳出循环
if (--len1 == 1)
break outer;
}
/*
* 这个判断相当于 count1 < minGallop && count2 1 && len2 > 0;
// gallopRight就是之前用过的那个方法
count1 = gallopRight(a[cursor2], tmp, cursor1, len1, 0, c);
if (count1 != 0) {
System.arraycopy(tmp, cursor1, a, dest, count1);
dest += count1;
cursor1 += count1;
len1 -= count1;
if (len1 <= 1) // 结尾处理退化的序列
break outer;
}
a[dest++] = a[cursor2++];
if (--len2 == 0) //结尾处理退化的序列
break outer;
count2 = gallopLeft(tmp[cursor1], a, cursor2, len2, 0, c);
if (count2 != 0) {
System.arraycopy(a, cursor2, a, dest, count2);
dest += count2;
cursor2 += count2;
len2 -= count2;
if (len2 == 0)
break outer;
}
a[dest++] = tmp[cursor1++];
if (--len1 == 1)
break outer;
// 这里对连续性比另外一个大的阈值减少,这样更容易触发这段操作,
// 应该是因为前面的数据表现好,后面的数据类似的可能性更高?
minGallop--;
} while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP); //如果连续性还是很大的话,继续这样处理s
if (minGallop < 0)
minGallop = 0;
//同样,这里如果跳出了那段循环,就证明数据的顺序程度不好,应当增加阈值,避免浪费资源
minGallop += 2;
} //outer 结束
this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field
//这里处理收尾工作
if (len1 == 1) {
assert len2 > 0;
System.arraycopy(a, cursor2, a, dest, len2);
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
} else if (len1 == 0) {
//因为序列1中的最后一个值,比序列2中的所有值都大,所以,不可能序列1空了,序列2还有元素
throw new IllegalArgumentException(
"Comparison method violates its general contract!");
} else {
assert len2 == 0;
assert len1 > 1;
System.arraycopy(tmp, cursor1, a, dest, len1);
}
}
/**
* Like mergeLo, except that this method should be called only if
* len1 >= len2; mergeLo should be called if len1 <= len2. (Either method
* may be called if len1 == len2.)
*
* @param base1 index of first element in first run to be merged
* @param len1 length of first run to be merged (must be > 0)
* @param base2 index of first element in second run to be merged
* (must be aBase + aLen)
* @param len2 length of second run to be merged (must be > 0)
*/
private void mergeHi(int base1, int len1, int base2, int len2) {
assert len1 > 0 && len2 > 0 && base1 + len1 == base2;
// Copy second run into temp array
T[] a = this.a; // For performance
T[] tmp = ensureCapacity(len2);
System.arraycopy(a, base2, tmp, 0, len2);
int cursor1 = base1 + len1 - 1; // Indexes into a
int cursor2 = len2 - 1; // Indexes into tmp array
int dest = base2 + len2 - 1; // Indexes into a
// Move last element of first run and deal with degenerate cases
a[dest--] = a[cursor1--];
if (--len1 == 0) {
System.arraycopy(tmp, 0, a, dest - (len2 - 1), len2);
return;
}
if (len2 == 1) {
dest -= len1;
cursor1 -= len1;
System.arraycopy(a, cursor1 + 1, a, dest + 1, len1);
a[dest] = tmp[cursor2];
return;
}
Comparator c = this.c; // Use local variable for performance
int minGallop = this.minGallop; // " " " " "
outer:
while (true) {
int count1 = 0; // Number of times in a row that first run won
int count2 = 0; // Number of times in a row that second run won
/*
* Do the straightforward thing until (if ever) one run
* appears to win consistently.
*/
do {
assert len1 > 0 && len2 > 1;
if (c.compare(tmp[cursor2], a[cursor1]) < 0) {
a[dest--] = a[cursor1--];
count1++;
count2 = 0;
if (--len1 == 0)
break outer;
} else {
a[dest--] = tmp[cursor2--];
count2++;
count1 = 0;
if (--len2 == 1)
break outer;
}
} while ((count1 | count2) < minGallop);
/*
* One run is winning so consistently that galloping may be a
* huge win. So try that, and continue galloping until (if ever)
* neither run appears to be winning consistently anymore.
*/
do {
assert len1 > 0 && len2 > 1;
count1 = len1 - gallopRight(tmp[cursor2], a, base1, len1, len1 - 1, c);
if (count1 != 0) {
dest -= count1;
cursor1 -= count1;
len1 -= count1;
System.arraycopy(a, cursor1 + 1, a, dest + 1, count1);
if (len1 == 0)
break outer;
}
a[dest--] = tmp[cursor2--];
if (--len2 == 1)
break outer;
count2 = len2 - gallopLeft(a[cursor1], tmp, 0, len2, len2 - 1, c);
if (count2 != 0) {
dest -= count2;
cursor2 -= count2;
len2 -= count2;
System.arraycopy(tmp, cursor2 + 1, a, dest + 1, count2);
if (len2 <= 1) // len2 == 1 || len2 == 0
break outer;
}
a[dest--] = a[cursor1--];
if (--len1 == 0)
break outer;
minGallop--;
} while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP);
if (minGallop < 0)
minGallop = 0;
minGallop += 2; // Penalize for leaving gallop mode
} // End of "outer" loop
this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field
if (len2 == 1) {
assert len1 > 0;
dest -= len1;
cursor1 -= len1;
System.arraycopy(a, cursor1 + 1, a, dest + 1, len1);
a[dest] = tmp[cursor2]; // Move first elt of run2 to front of merge
} else if (len2 == 0) {
throw new IllegalArgumentException(
"Comparison method violates its general contract!");
} else {
assert len1 == 0;
assert len2 > 0;
System.arraycopy(tmp, 0, a, dest - (len2 - 1), len2);
}
}
/**
* 保证临时数组的大小能够容纳所有的临时元素,在需要的时候要扩展临时数组的大小。
* 数组的大小程指数增长,来保证线性的复杂度。
*
* 一次申请步长太小,申请的次数必然会增多,浪费时间;一次申请的空间足够大,必然会
* 浪费空间。正常情况下,归并排序的临时空间每次大的合并都会 * 2,
* 最大长度不会超过数组长度的1/2。 这个长度于2 有着紧密的联系。
*
* @param minCapacity 临时数组需要的最小空间
* @return tmp 临时数组
*/
private T[] ensureCapacity(int minCapacity) {
// 如果临时数组长度不够,那需要重新计算临时数组长度;
// 如果长度够,直接返回当前临时数组
if (tmp.length < minCapacity) {
// 这里是计算最小的大于minCapacity的2的幂。方法不常见,这里分析一下。
//
// 假设有无符号整型 k,它的字节码如下:
// 00000000 10000000 00000000 00000000 k
// 00000000 11000000 00000000 00000000 k |= k >> 1;
// 00000000 11110000 00000000 00000000 k |= k >> 2;
// 00000000 11111111 00000000 00000000 k |= k >> 4;
// 00000000 11111111 11111111 00000000 k |= k >> 8;
// 00000000 11111111 11111111 11111111 k |= k >> 16
// 上面的移位事实上只跟最高位有关系,移位的结果是最高位往后的bit全部变成了1
// 最后 k++ 的结果 就是刚好是比 minCapacity 大的2的幂
// 写的真是6
int newSize = minCapacity;
newSize |= newSize >> 1;
newSize |= newSize >> 2;
newSize |= newSize >> 4;
newSize |= newSize >> 8;
newSize |= newSize >> 16;
newSize++;
if (newSize < 0) // Not bloody likely! 估计作者在这里遇到bug了
newSize = minCapacity;
else
newSize = Math.min(newSize, a.length >>> 1);
@SuppressWarnings({"unchecked", "UnnecessaryLocalVariable"})
T[] newArray = (T[]) new Object[newSize];
tmp = newArray;
}
return tmp;
}
/**
* 检查范围fromIndex到toIndex是否在数组内,如果不是抛异常
*
* @param arrayLen 整个数组的长度
* @param fromIndex 该范围的起点
* @param toIndex 该范围的终点
* @throws IllegalArgumentException if fromIndex > toIndex
* @throws ArrayIndexOutOfBoundsException if fromIndex < 0 or toIndex > arrayLen
*/
private static void rangeCheck(int arrayLen, int fromIndex, int toIndex) {
if (fromIndex > toIndex)
throw new IllegalArgumentException("fromIndex(" + fromIndex +
") > toIndex(" + toIndex + ")");
if (fromIndex < 0)
throw new ArrayIndexOutOfBoundsException(fromIndex);
if (toIndex > arrayLen)
throw new ArrayIndexOutOfBoundsException(toIndex);
}
}