Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取猫眼电影top100的榜单信息
2.主题式网络爬虫爬取的内容与数据特征分析
①爬取内容:排名,电影名,主演,上映时间,影评分数,电影主页链接,封面图片链接
②数据特征分析:统计各地区电影数量(柱状图)、电影评分占比情况(饼图)、各年份电影的评分分布情况(散点图)、统计各明星参演的电影有几部、统计出演次数的人数(计数直方图)、统计主演合作次数
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
①get_one_page(url)函数:用requests库获取url页面原码
②get_release_time(data)、get_release_area(data)函数:用正则表达式匹配源代码中的上映时间和国家。
③parse_one_page(html)函数:用BeauifulSoup库解析源码,并用find_all方法提取相关数据
④write_to_csv(item)函数:将提取的数据保存成CSV文件,以便后续做数据分析
⑤main(offset):主函数,定义网址,用offset参数遍历网页页码,并调用get_one_page(url)函数获取源码,parse_one_page(html)解析源码提取数据,write_to_csv(item)写入文件保存数据。
技术难点:
①网页爬取需要加入headers,否则网页源码爬取不了
②将数据写入CSV文件时,因为数据是一页一页提取的,所以文件打开模式需要设置为‘a’
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征

一共有10页,每页有10部电影,每一页的网址都不一样

页面的url = "https://maoyan.com/board/4"+上图的@href属性值
2.Htmls页面解析
通过源码可以看到,每部电影的数据都存放在一个

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
节点树:

三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
import requests from bs4 import BeautifulSoup import re from requests.exceptions import RequestException import csv #提取网页源代码 def get_one_page(url): try: #请求头地址 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } # 不加headers爬不了 r = requests.get(url, headers=headers) if r.status_code == 200: html = r.text return html else: return None except RequestException: return None # try-except语句捕获异常 # 提取上映时间函数 def get_release_time(data): pattern = re.compile(r'(.*?)(\(|$)') items = re.search(pattern, data) if items is None: return '未知' return items.group(1) # 返回匹配到的第一个括号(.*?)中结果即时间 #提取国家函数 def get_release_area(data): # $表示匹配一行字符串的结尾,这里就是(.*?);(|$,表示匹配字符串含有(,或者只有(.*?) pattern = re.compile(r'.*\((.*)\)') items = re.search(pattern, data) if items is None: return '未知' return items.group(1) #解析网页源码,提取数据 def parse_one_page(html): soup = BeautifulSoup(html,'lxml') items = range(10) for item in items: yield{ 'index': soup.find_all(class_='board-index')[item].string, 'name': soup.find_all(name = 'p',attrs = {'class' : 'name'})[item].string, #strip函数删除多余的空格 'star': soup.find_all(name = 'p',attrs = {'class':'star'})[item].string.strip()[3:], 'time': get_release_time(soup.find_all(class_ ='releasetime')[item].text.strip()[5:]), 'area': get_release_area(soup.find_all(class_ ='releasetime')[item].string.strip()[5:]), #拼接评分 整数+小数 'score':soup.find_all(name = 'i',attrs = {'class':'integer'})[item].string.strip() + soup.find_all(name = 'i',attrs = {'class':'fraction'})[item].string.strip() } # 数据存储到csv def write_to_csv(item): # 'a'为追加模式(添加) # utf_8_sig格式导出csv不乱码 with open('./catMovieTop100.csv', 'a', encoding='utf_8_sig',newline='') as f: fieldnames = ['index','name', 'star', 'time','area', 'score'] w = csv.DictWriter(f,fieldnames = fieldnames) w.writerow(item) #主函数 def main(offset): #拼接网站 url = 'http://maoyan.com/board/4?offset=' + str(offset) html = get_one_page(url) for item in parse_one_page(html): write_to_csv(item) if __name__ == '__main__': for i in range(10): main(offset = i*10)
保存的csv文件结果图:

2.对数据进行清洗和处理
数据清洗
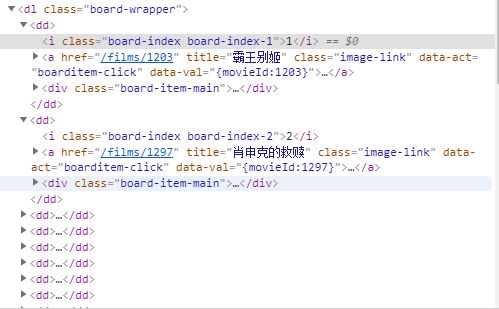
#数据清洗 import pandas as pd import csv #设置表头 columns = ['rank', 'movie_name', 'star', 'releasetime', 'area', 'score'] #将排名设为索引 df = pd.read_csv('./catMovieTop100.csv',header = None,names = columns) df.index = range(1,len(df)+1) #将默认的索引转换成排名索引(从1开始) df = df.drop(['rank'],axis = 1) # 删除作为索引重复的rank列 df
结果图:
3.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
①各地区电影数量排名情况(柱状图)
import matplotlib.pyplot as plt area_count = df.groupby(by = 'area').area.count().sort_values(ascending = False) #统计电影数量 area_count.plot.bar(color = 'blue') #绘图 #中文显示乱码加入下面两行 plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 for x,y in enumerate(list(area_count.values)): plt.text(x,y+0.5,'%s' %round(y,1),ha = 'center',color = "red" ) #显示各地区电影数量 plt.title('各地区电影数量排名',color = "black") #设置标题 plt.xlabel('国家(地区)') #添加x轴标签 plt.ylabel('数量(部)') #添加y轴标签 plt.grid(True) #添加网格 plt.show()
数据可视化:

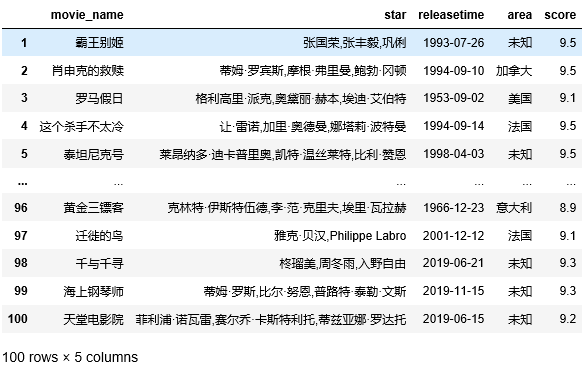
②电影评分占比情况(饼图)
df_score = df['score'].value_counts() #统计评分情况 plt.title("电影评分占比情况") #设置饼图标题 plt.pie(df_score.values,labels = df_score.index,autopct='%1.1f%%') #绘图 #autopct表示圆里面的文本格式,在python里%操作符可用于格式化字符串操作 plt.show()
数据可视化:
③各年份电影的评分分布情况(散点图)
df.releasetime = pd.to_datetime(df.releasetime) #将日期数据转为日期类型 plt.scatter(df['score'],df.releasetime)#绘制散点图
数据可视化:

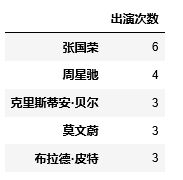
④统计各明星参演的电影有几部,查看前五名
star_map = pd.Series(df['star'].str.cat(sep=',').split(",")) #分割主演名字 pd.DataFrame(pd.Series(star_map).value_counts(),columns=['出演次数']).head() #统计名字出现的次数
结果:
⑤统计出演次数的人数(计数直方图)
star_map = pd.Series(df['star'].str.cat(sep=',').split(",")) #分割主演名字 name_df = pd.DataFrame(pd.Series(star_map).value_counts(),columns=['出演次数']) #统计名字出现的次数 sns.countplot(name_df['出演次数'])
数据可视化:

⑥主演合作次数
df.star.value_counts().head()
结果:

4.数据持久化
df.to_csv("./catMovie.csv")

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
①猫眼top100大部分电影都是在1990年之后上映的
②美国电影在排行榜占据优势,说明美国电影比较受大众欢迎
③上榜电影的评分主要在8.8~9.1分之间
④参演的电影上榜最多张国荣,其次是周星驰
⑤上榜电影的主演中“伊莱贾·伍德,伊恩·麦克莱恩,丽芙·泰勒“合作次数最多,合作了3次
2.对本次程序设计任务完成的情况做一个简单的小结。
在这次python爬虫作业中,不仅在慕课平台上学到了requests,BeautifulSoup,re几个库的基本使用,还在爬取结果报错翻阅博客查找资料的过程中学到lxml库的xpath查找节点树数据的方法,还有就是知道了有些网站需要添加请求头地址才能爬取。通过这个课程的学习,对python有了进一步的了解,以及通过学习爬虫与数据可视化,实践与这次的程序设计的作业中,让我见识到了更多python强大的功能库。