一个用JavaScript编写的,小巧、快速的JavaScript解析器。
当在CommonJS(node.js)或AMD环境中运行时,可直接使用require或import导入。 在浏览器中加载时(Acorn可以在任何启用JS的浏览器中使用,支持IE5以上),无需任何类型的模块管理,将定义单个全局对象acorn,并将所有导出的属性添加到该对象中。
Main parser
parse(input, options) 这个函数用来解析JavaScript代码,返回值将是由ESTree规范指定的抽象语法树对象。input为string类型参数(即js代码),options可以为undefined或者是如下的值:
ecmaVersion 指定要解析的ECMAScript版本。 必须是3,5,6(2015),7(2016)或8(2017)。 这会影响严格模式、保留字集合、和新的语法特征支持。 默认版本为7(ES6)。
注意:只有“stage4”(finalized)ECMAScript功能正在被Acorn实现。sourceType 指定代码应该被解析的模式。可以是
script或module。 这将影响全局的严格模式,和解析import和export的声明。onInsertedSemicolon 如果有回调函数,则只要解析器插入了一个缺少的分号,就会调用该回调函数。 回调函数将被赋予插入分号的点的字符偏移量作为参数,如果
locations被设置,则表示此位置的{line,column}对象。onTrailingComma 像
onInsertedSemicolon,但是为了跟踪逗号插入。allowReserved 如果为
false,则使用保留字会产生错误。 对于ecmaVersion 3,默认为true,对于较高版本,默认为false。 当value为never时,保留字和关键字也不能用作属性名称(如IE低版本浏览器)allowReturnOutsideFunction 默认情况下,顶层的return语句会引发错误。 将其设置为
true以接受此类代码。allowImportExportEverywhere 默认情况下,导入和导出声明只能显示在程序的顶层。 将此选项设置为true可以允许在允许语句的任何地方
allowHashBang 启用此功能(默认情况下关闭),如果代码以
#!开始(如在shellscript中),第一行将被视为注释。locations 当为
true时,每个Node都有一个连接起始和终止子对象的loc对象,每个对象包含{line,column}形式的一个行号和列号。 默认值为false。onToken 如果为此选项传递了一个函数,则每个发现的token将以与从
tokenizer() getToken()返回的tokens相同的格式传递。
如果参数是array,则每个发现的token将被push到array中。
注意不能从回调中调用解析器,从而破坏其内部状态。-
onComment 如果为此选项传递函数,每当遇到注释时,将使用以下参数调用该函数:
- block:如果注释是块注释,则为true,如果是行注释,则为false。
- text:评论的内容。
- start:注释开头的字符偏移量。
- end:注释结尾的字符偏移量。
当locations参数被设置时,注释的开始和结束位置{line,column}将作为
两个附加参数传递。
当此选项是array时,每个注释被push到它作为对象以Esprima格式:
{
"type": "Line" | "Block",
"value": "comment text",
"start": Number,
"end": Number,
// If `locations` option is on:
"loc": {
"start": {line: Number, column: Number}
"end": {line: Number, column: Number}
},
// If `ranges` option is on:
"range": [Number, Number]
}
请注意,您不能从回调函数中调用解析器,从而破坏其内部状态。
ranges 节点的起始和终止字符偏移记录在起始和结束属性中(直接在节点上,而不是保存行/列数据的
loc对象),还要添加一个保持[start,end]数组的半标准化范围属性, 使用相同的数字,将ranges设置为true。program 通过解析第一个文件生成的树, 作为后续解析中的程序选项传递多个文件,可以将多个文件解析为单个AST。 会将已解析的文件以toplevel形式添加到现有解析树的“Program”(program即顶部节点)节点。
sourceFile 当
locations选项为true时,您可以传递此选项以在每个节点的loc对象中添加一个源属性。 请注意,此选项的内容不以任何方式进行检查或处理; 您可以随意使用您选择的任何格式。directSourceFile 像
sourceFile一样,但是一个sourceFile属性将直接添加到节点,而不是loc对象。preserveParens 如果此选项为
true,则括号表达式由(非标准)括号化表达式节点表示,该节点具有包含括号内的表达式的单个表达式属性。
parseExpressionAt(input, offset, options)
将解析字符串中的单个表达式,并返回其AST。 如果表达式之后还有更多的字符串,不会去解析。
getLineInfo(input, offset)
可用于获取给定程序字符串和字符偏移量的{line,column}对象。
tokenizer(input, options)
返回具有getToken方法的对象,该方法可以重复调用以获取下一个token和{start,end,type,value}对象(启用了location选项时添加了loc属性,并且启用了range选项时的range属性)。 当令牌的类型为tokTypes.eof时,您应该停止调用该方法,因为它将永远返回相同的token。
var a = require('./a.js');
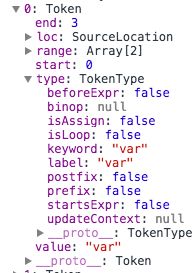
在 type 对应的对象中,label 表示当前标识的一个类型,keyword 就是关键词,像例子中的require,或者 function 之类的。
value 则是当前标识的值,start/end 分别是开始和结束的位置。
更多type解释https://segmentfault.com/a/1190000007473065
在ES6环境中,返回的结果可以用作任何其他符合协议的迭代:
for (let token of acorn.tokenizer(str)) {
// iterate over the tokens
}
// transform code to array of tokens:
var tokens = [...acorn.tokenizer(str)];
tokTypes拥有将name映射到token object的对象,该对象最终在token的type属性中。
using with Escodegen
Escodegen支持从AST生成注释,附加在特定于Esprima-specific的格式。 为了在Acorn中模拟相同的格式,请考虑以下示例:
var comments = [], tokens = [];
var ast = acorn.parse('var x = 42; // answer', {
// collect ranges for each node
ranges: true,
// collect comments in Esprima's format
onComment: comments,
// collect token ranges
onToken: tokens
});
// attach comments using collected information
escodegen.attachComments(ast, comments, tokens);
// generate code
console.log(escodegen.generate(ast, {comment: true}));
// > 'var x = 42; // answer'