李雷和韩梅梅同学是好朋友,他们从周一到周五都在一起学习,在周六的早上你发现教室里有两个人,其中一个是李雷,你猜猜另一个会是谁?我想你会猜韩梅梅,因为两人老是在一起,所以从逻辑上看,猜韩梅梅是非常复合逻辑的。同理,如果我们想要猜“中华”这一词后面跟着哪个词,我们就统计一下在所有文本中,跟着“中华”后面的词是哪个,例如跟在“中华”后面最多的是“人民共和国”,那么一旦我们看到“中华”一词后,我们就很合理的猜测跟着的词是“人民共和国”。
在自然语言处理中对词语的处理也遵循上面描述的统计学原则。假设我们有如下一条英语句子:the cat jump over the dog. 通过句子我们能感觉到单词jump跟它左右的单词有点像前面我们举例中的”中华“与"人民共和国“,因为它与左右两边的词存有某种亲密关系,因为它与左右两边的词组合能够表达出某种意义。我们这节讲述的skip-gram模型,就是给定一个单词后,预测在它左右两边可能会出现什么单词。当然这个预测是有范围的,这个范围用window来表示,如果window是2,那么我们就预测它左右两边的两个词,也就是"the cat"和"over the",如果是1,那么模型就预测左边的"cat"和右边的"over",jump这个词叫中心词,左右两边的词叫上下文。
假设我们用表示,如果window=2,那么左右两边的上下文就可以用,,,来表示,由于上下文四个词与jump连接在一起,于是看到jump,我们有理由估计出现在它左右两边的词就是上下文四个词,这个“估计”可以用条件概率来表示P(,,,|),如果它们的组合在所有文本中出现的越多,这个概率就越大,我们假设每个词的出现是相互独立的,当然事实上词与词之间存在着很强的关联,但为了计算方便,我们暂时假定词与词之间没有关联,于是前面的联合条件概率可以分解成:P(*P(|W_i)*P()*P(),接下来问题在于,这个概率如何计算。
在skip-gram 模型中是这么处理的,它首先构造一个型如下面结构的网络:
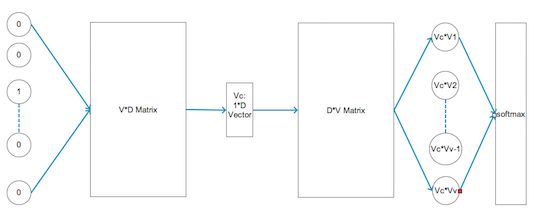
我们逐步分析一下这个神经网络结构,最左边很多个0,其中只有一个是1的部分是网络的输入信号,它就是我们前面提到过的one-hot-vector,假设所有文本用到的词汇量是V,那么one-hot-vector就有V个元素,如果中心词在词汇中的编号是i,那么输入向量所有元素都是0,只有第i个元素是1,接下来的两个大方块表示两个矩阵,第一个矩阵行数是V,列数是D,用M1表示,这个D是由我们来设置的参数,第二个矩阵行数是D,列数是V,用M2表示,这两个矩阵里面的元素就是该模型要训练的参数。
模型首先将开始的one-hot-vector与矩阵M1相乘,注意到one-hot-vector只有一个元素是1,其他都是0,于是两者相乘就相当于M1的第i列“拎出来”,因此位于M1矩阵后面的1*D维向量其实是M1矩阵的第i列。我们用来表示。接着该向量与第二个矩阵,也就是M2中的每一列相乘,两个向量做点乘最后得到一个常量,由于M2有V列,因此作为乘法后,M2后面产生V个值,用,...分别表示M2的每一列,那么分别与他们做点乘后就得到V个值,这V个值经过softmax层后会做一个归一化处理,也就是把这V个值与常数e做指数运算,然后在分别除以他们的和,也就是第i-1个值由原来的*变为:

模型把上面这个值就定义为,这么定义是合理的,因为+...等于1,符合概率模型的定义。网络模型训练的最终目的是使得P(*P(|W_i)*P()*P()它的值最大,这个目的还是比较直观的,因为词,,,已经出现在中心词周围了,因此让这个概率尽可能的大显然是合理的。我们对概率乘机去个对数,这样就能将乘法变成加法,也就是:
我们可以把其中的P()用上面的式子来代替,尽管我们想求最大值,但深度学习在实现时总是喜欢找最小值,因此我们把上面式子加个负号然后求最小值即可,于是公式变换为:
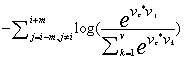
公式中的m表示窗口长度,上面式子可以进一步化简,log里面的除法可以变成减法,于是有:
因为log和e可以相互抵消,于是再做进一步变换就有:
上面公式中有两个参数,一个是,另一个是,于是要想求由他们组成的函数的最小值,那就对两个变量分别求偏导数,我们先对求偏导,于是上面公式的左边部分就只剩下,关键是右边部分的偏导数运算,右边部分的求导要用到间套函数求导的链式法则:f(g(x))'=f'(g(x))*g'(x),于是有:
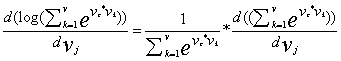
继续对上面式子的有半部分化简:
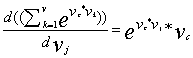
全部结合在一起有:
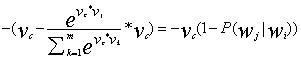
假设学习率为r,于是我们就可以更新参数:
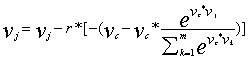
接下来我们对另一个参数,也就是求偏导,对于公式:
我们针对左边部分做
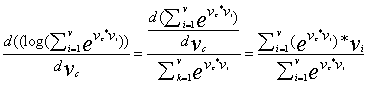
这样我们就得到对变量的更新方式:
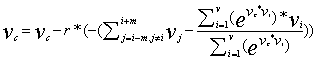
上面式子看起来似乎很吓人,其实它只是形式上看起来复杂,它的运算本质上就是高数里的复合函数链式求导应用而已。有了上面的算法原理后,在实际训练网络时,我们需要从网上加载大量网页,把网页内容分解成一个个单词后,输入给模型进行训练,用于输入到模型的单词量大概在60亿左右,并且目前网络上所有网页总共用到的词汇量在一百万左右,也就是公式中的V约等于一百万,当训练完成后,网络中两个矩阵里的参数就可以确定下来,第一个矩阵维度为VD,每一行向量含有D个元素,第二个矩阵维度为DV,每一列含有D个元素,我们把第一个矩阵的第一行加上第二个矩阵的第一列,得到一个D维向量,这个向量就是编号为1的单词对应的向量。
在实际运用中,上面的算法不可行,原因在于我们的推导中含有一个成分是:
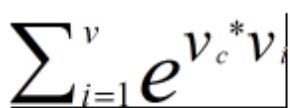
其中的是第一个矩阵出来的向量,对应第二个矩阵中每一列向量,由于V是词汇量,在实际运用时,词汇量总数在一百万,于是模型每次从网页上读入一个单词时,都得进行一百万次乘法运算,如果抓取的网页总共含有40亿个单词,那总运算量就是40亿乘以一百万,也就是4千万亿,这种运算量是不可承受的,因此上面模型需要进行改进。
一种改进的方法叫negative sampling。我们要把上面提到的运算量过大的部分给去掉,我们用一种新的方式来表示概率如下:
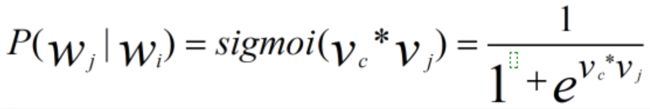
我们知道sigmoid函数运算的结果在0和1之间,这使得该函数特别适合用于模拟概率分布,我们把上面式子代入到前面的概率乘机就有:
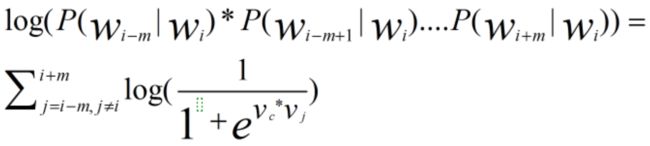
上面的公式就摆脱了原来要做一百万次运算的需求,直接用两个向量做一次乘机就可以了。如果给定句子the cat jump over the dog,中心词我们采用jump,窗口大小采用2,那么上面式子表示当我看到单词jump后,其他四个单:the,cat,over,the出现在它旁边的概率。
接下来我们还得随机抽取若干个不在窗口范围内词,例如句子:I came into the room and saw the cat jump over the dog.有好几个单词I,came,等不在jump的窗口范围内,假设它两的编号分别是p,q,那么我们就需要最小化概率,和。由此我们得到最后的目标函数:

上面目标函数的第二部分对应的是随机抽取的k个不在中心词窗口内的单词。要想最大化上面的目标函数,网络就会把减号前面部分最大化,减号后面部分最小化,于是出现中心词窗口范围内的词概率就越高,不在中心词窗口期内的词对应的概率就会越低。
用上吗的网络模型训练得到的单词向量有一个非常奇妙的现象,假设四个单词man, king,women,quene,对应向量分别为,,,,他们居然形成了这样的关系:-+=,这意味着单词向量居然把单词的语法特性和语义关系给捕捉到了,也就是说通过深度学习,我们把原本根本无法量化的语言成功实现了量化。
更详细的讲解和代码调试演示过程,请点击链接
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号:
