Protocol Buffer
1. 定义
Protocal Buffer(后续简称Protobuf)是由谷歌开源的一套结构化的数据存储方案,类似于XML、Json。
相比于XML和Json,它有自己的特点
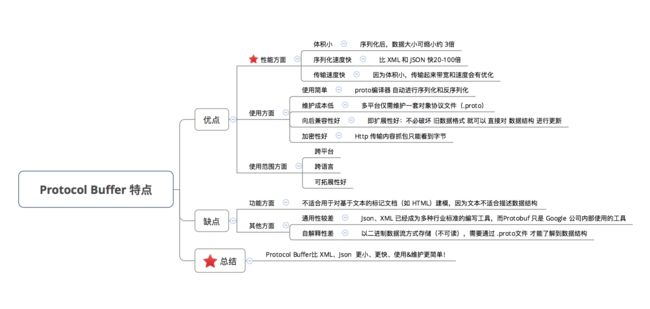
优点上
- 体积更小,序列化和传输的速度更快
- 使用相对简单维护成本低兼容性好
- 跨平台,跨语言
缺点上
- 二进制存储,自释性差
- XML和Json当道,通用性较差
具体可以参考github项目页以及开发者页
基于以上特点,我们可以看到在传输数据量较大的需求场景下,Protobuf比XML、Json 更小、更快、使用和维护更简单!
2. 安装
下载后编译Procobuf的编译器,过程就不做描述
最后依然是通过命令的方式查看安装成功与否
MacBook-Pro:~ wangchen$ protoc --version
libprotoc 3.8.0
这里protoc实际就是Protocolbuf的编译器,作用是将.proto文件编译成对应平台的头文件和源代码文件
3. 使用
使用Protobuf语法编写.proto文件,proto文件用于表征一个需要序列化的数据结构,有了proto文件之后,我们可以使用上面生成的Protobuf编译器将该文件编译成Protobuf支持的各种语言,然后在项目中使用这些数据结构。
以Protobuf自带的example为例,执行protoc命令,主要是指定需要编译的目标语言生成文件路径以及原文件路径
3.1 proto文件
先看下example中自带的proto文件内容
// 指定语法版本为proto2
syntax = "proto2";
// 指定包名,用于处理命名冲突。除此之外输出为java语言时,该字段用于表示默认状态下的java类所处的包名
package tutorial;
// 指定输出为java语言时,java类所处的包名。优先级大于package声明的包名
option java_package = "com.example.tutorial";
// 指定输出为java语言时,java类的类名。不指定时会使用驼峰命名的方式将proto文件名转换成类名
option java_outer_classname = "AddressBookProtos";
// 定义消息类型,所谓消息即为一系列特定属性的集合体,用于真正表示数据结构
message Person {
// 1. 属性可以时简单数据类型,包括(bool,int32,float,double,string)
// 2. proto2中每条属性都必须使用修饰语修饰,包括(required,optional以及repeated)
// 3. =1、=2是用于标记属性的唯一标签,用于二进制编码,标记1-15占用一个字节,16及以上占用更多字节
required string name = 1;
required int32 id = 2;
optional string email = 3;
// 可以定义枚举类型
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
// 可以在消息类型中进行嵌套消息定义
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
// 属性也可以是其他消息类型
repeated PhoneNumber phones = 4;
}
// 一个proto文件中可以定义多个消息对象
message AddressBook {
repeated Person people = 1;
}
3.2 编译proto文件
简单过一遍之后我们可以对该文件做编译了
MacBook-Pro:examples wangchen$ protoc --java_out=. addressbook.proto
生成对应包下的Java文件

3.3 生成类
我们可以简单看下protobuf为我们生成的java文件,它会将每一个message翻译成一个java类。以Person为例,Person消息中对应的属性都被翻译成了java中的成员变量,并提供get和has方法。对于repeated修饰的属性,会额外提供getCount方法,返回长度。
// required string name = 1;
public boolean hasName();
public String getName();
// required int32 id = 2;
public boolean hasId();
public int getId();
// optional string email = 3;
public boolean hasEmail();
public String getEmail();
// repeated .tutorial.Person.PhoneNumber phones = 4;
public List getPhonesList();
public int getPhonesCount();
public PhoneNumber getPhones(int index);
从上面可以看到每一个消息对应的Java类中的成员变量都没有set方法,实际上这些类都是不可变类,只要消息对象生成了,那么它不再可修改,就像Java中的String一样。因此protobuf为每一个消息对应的Java类都配置了一个Builder用于构造该类的对象。还是以Person为例
// required string name = 1;
public boolean hasName();
public java.lang.String getName();
public Builder setName(String value);
public Builder clearName();
// required int32 id = 2;
public boolean hasId();
public int getId();
public Builder setId(int value);
public Builder clearId();
// optional string email = 3;
public boolean hasEmail();
public String getEmail();
public Builder setEmail(String value);
public Builder clearEmail();
// repeated .tutorial.Person.PhoneNumber phones = 4;
public List getPhonesList();
public int getPhonesCount();
public PhoneNumber getPhones(int index);
public Builder setPhones(int index, PhoneNumber value);
public Builder addPhones(PhoneNumber value);
public Builder addAllPhones(Iterable value);
public Builder clearPhones();
具体就不详细描述了
3.4 Android项目中使用
将生成的java文件放到项目中

添加protobuf的java语言依赖
implementation 'com.google.protobuf:protobuf-java:3.8.0'
使用java类开始编码
// 构造PhoneNumber对象列表
AddressBookProtos.Person.PhoneNumber phoneHome = AddressBookProtos.Person.PhoneNumber.newBuilder()
.setNumber("+10086")
.setType(AddressBookProtos.Person.PhoneType.HOME)
.build();
AddressBookProtos.Person.PhoneNumber phoneMobile = AddressBookProtos.Person.PhoneNumber.newBuilder()
.setNumber("+10000")
.setType(AddressBookProtos.Person.PhoneType.MOBILE)
.build();
// 构造Person对象列表
List allPhones = new ArrayList<>();
allPhones.add(phoneHome);
allPhones.add(phoneMobile);
AddressBookProtos.Person person = AddressBookProtos.Person.newBuilder()
.setId(1)
.setName("Mohsen")
.setEmail("[email protected]")
.addAllPhones(allPhones)
.build();
// 构造AddressBook对象
List allPhones = new ArrayList<>();
allPhones.add(phoneHome);
allPhones.add(phoneMobile);
AddressBookProtos.Person person = AddressBookProtos.Person.newBuilder()
.setId(1)
.setName("WangChen")
.setEmail("[email protected]")
.addAllPhones(allPhones)
.build();
// 序列化
byte[] bytes = addressBook.toByteArray();
// 反序列化
try {
AddressBookProtos.AddressBook myAddressBook = AddressBookProtos.AddressBook.parseFrom(bytes);
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
3.5 Gradle插件
每次单独执行protoc编译proto文件会显得太麻烦,通过protobuf-gradle-plugin插件可以在编译我们的app时自动地编译proto文件,这样可以大大降低了我们在Android项目中使用Protobuf的难度。
添加插件依赖
根目录gradle配置文件新增插件依赖,目前插件最新版本为0.8.10
dependencies {
classpath 'com.android.tools.build:gradle:3.4.1'
classpath 'com.google.protobuf:protobuf-gradle-plugin:0.8.10'
// NOTE: Do not place your application dependencies here; they belong
// in the individual module build.gradle files
}
应用插件
项目gradle配置文件引用插件
apply plugin: 'com.google.protobuf'
配置插件
项目gradle配置文件中需要使用protobuf块进行插件的配置,包括设置编译器的版本和路径,代码辅助生成器的插件,Android项目推荐使用的插件是protobuf-lite
protobuf {
protoc {
// You still need protoc like in the non-Android case
artifact = 'com.google.protobuf:protoc:3.8.0'
}
plugins {
javalite {
// The codegen for lite comes as a separate artifact
artifact = 'com.google.protobuf:protoc-gen-javalite:3.0.1'
}
}
generateProtoTasks {
all().each { task ->
task.builtins {
// In most cases you don't need the full Java output
// if you use the lite output.
remove java
}
task.plugins {
javalite { }
}
}
}
}
添加依赖
添加protobuf-lite相关依赖
implementation 'com.google.protobuf:protobuf-lite:3.0.1'
编写proto文件
上述配置完毕之后,就可以在proto文件夹下编写proto文件,每次同步时都会自动生成对应Java类

3.6 大小比对
这里做一个序列化大小的对比,将之前代码中的AddressBook对象序列化后生成的bytes数组长度打印出来可以看到,这个addressBook对象序列化之后大小为58个字节。
同时与我们上述addressBook对象对应的Json字串大概如下
{
"addressbook": [{
"person": {
"id": 1,
"name": "WangChen",
"email": "[email protected]"
}
}, {
"phones": [{
"phone": {
"number": "+10086",
"type": "HOME"
}
}, {
"phone": {
"number": "+10000",
"type": "MOBILE"
}
}]
}]
}
压缩该Json字串之后查看,占用字节数为187,大小是Protobuf的三倍,Protobuf在序列化大小压缩的提升还是非常明显的。
4. 语法
参考官网,略
5. 编码原理
从之前的对比中,我们可以看到Protobuf的序列化后大小只有Json的三分之一左右,主要是因为Protobuf的编码方式导致的。这里我们可以挖掘一下Protobuf的编码原理。
5.1 一条简单的消息
假设我们定义了如下的message
message Test1 {
optional int32 a = 1;
}
然后在项目中定义了一个Test1的对象并且赋值a=150,那么它序列化之后的字节情况是
08 96 01
正如之前说的,虽然Protobuf的序列化体积占用小,但是自释性很差,我们无法理解这三个字节的意思,下面开始分别阐述。
5.2 T-L-V
Protobuf中的数据是以Tag - Length - Value的方式进行存储的,以标识 - 长度 - 字段值 表示单个数据,最终将所有数据拼接成一个字节流,从而实现数据存储的功能。T-L-V结构中,L部分是可选存储,因为有些内容我们不需要知道长度,相对的它本身的数据类型或者编码方式就已经决定了他的长度

从上图可知,T - L - V 存储方式的优点是
- 不需要分隔符就能分隔开字段,减少了分隔符的使用
- 各字段存储得非常紧凑,存储空间利用率非常高
- 若字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不需要编码,相应字段也是在解码的时候才会被设置为默认值
5.3 Tag
Protobuf中的Tag用于表示标识号以及数据类型,即
Tag = 标识号(field number) + 数据类型(wire type)
计算关系是
Tag = (field number << 3) | wire type
标识号
标识号我们在之前的proto语法中已经看到了
optional int32 a = 1;
a = 1就是用来描述a属性的标识号是1
数据类型
数据类型用于表征内容的一个编码方式,Protobuf中一共有5中数据类型
enum WireType {
WIRETYPE_VARINT = 0,
WIRETYPE_FIXED64 = 1,
WIRETYPE_LENGTH_DELIMITED = 2,
WIRETYPE_START_GROUP = 3,
WIRETYPE_END_GROUP = 4,
WIRETYPE_FIXED32 = 5
};
它和编码方式以及存储方式的关系如下
| Type | Meaning | Store | Used For |
|---|---|---|---|
| 0 | Varint(ZigZag) | T - V | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | T - V | fixed64, sfixed64, double |
| 2 | Length-delimited | T - L - V | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | - | groups (deprecated) |
| 4 | End group | - | groups (deprecated) |
| 5 | 32-bit | T - V | fixed32, sfixed32, float |
举个例子
上述消息
message Test1 {
optional int32 a = 1;
}
中,属性a对应的Tag即为 (0000 0001 << 3) | 0 = 0000 1000 = 8
反过来
Tag = 12(0001 0010)表征的实际数据类型是2,标识号是2
5.4 Varints
为了了解Protobuf的编码,我们还要知道Varints编码。对于数据类型是0的内容,Protobuf都使用Varints进行编码。Varints是一种变长的对整数的编码方式,数值越小的数字,使用越少的字节数表示,通过这种方式进行数据压缩。
Varints编码的数值每个字节的最高位有着特殊的含义
- 如果是1,表示后续的字节也是该数值的一部分
- 如果是0,表示这是最后一个字节,且剩余的7位都用来表示该数字
所以,当使用Varints解码时,只要读取到某一字节的最高位是0,就表示这是该段内容已经解析完毕。这种方式直接带来的影响就是,对于小于128的int,只需要用1个字节来表示,虽然大数字可能会需要5个字节来表示,但绝大多数情况下,消息都不会有很大的数字出现,因此Varints可以做到有效的数据压缩。
举个例子
我们要对296进行Varints编码,过程如下

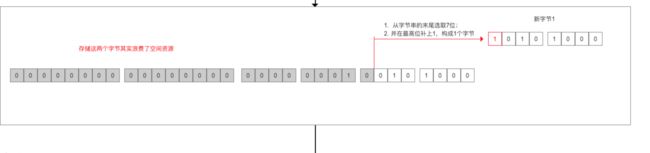


因此150就会被编码成
96 01
至此,我们知道了最开头的
08 96 01
所表达的内容含义就是对应的内容了,即08为a属性的tag,96 01 表示a属性的值
5.5 ZigZag
Varints编码有一个先天的不足之处,就是负数一般会表示成很大的证书,此时使用Varints进行编码会导致字节的增加,因此
Protobuf 定义了 sint32 / sint64 类型表示负数,通过先采用Zigzag编码(将有符号数转换成 无符号数),再采用Varints编码,从而用于减少编码后的字节数
ZigZag编码计算方式是
// sint32
(n << 1) ^ (n >> 31)
// sint64
(n << 1) ^ (n >> 63)
ZigZag解码的计算方式是
(n >>> 1) ^ -(n & 1);
5.6 packed
repeated修饰的字段有两种表达方式
message Test
{
repeated int32 Car = 4 ;
// 表达方式1:不带packed=true
repeated int32 Car = 4 [packed=true];
// 表达方式2:带packed=true
// proto 2.1 开始可使用
// 区别在于:是否连续存储repeated类型数据
}
对于同一个repeated字段、多个字段值来说,他们的Tag都是相同的,即数据类型和标识号都相同,存储形式如
T - V - T - V - T - V ...
这种方式会导致Tag的冗余,即相同的Tag存储多次。
此时可以采用带packed=true的repeated字段存储方式,即将相同的Tag只存储一次,此时的存储形式如
T - L - V - V - V ...
5.7 总结
从上面的几点编码原理上我们可以总结如下的一些使用建议
- 多用optional或repeated修饰符(proto3已经移除了required修饰符)
- 字段标识号(Field_Number)尽量只使用1-15
- 若需要使用的字段值出现负数,请使用sint32 / sint64,不要使用int32 / int64
- 对于repeated字段,尽量增加packed=true修饰(proto3中的repeated的基础数据类型默认packed)
同时我们也得到Protobuf的特点的解释
- 编解码计算简单,因此序列化和反序列化效率高
- 采用独特编解码方式和数据存储方式,压缩效率更高、传输速度也更快