1. 创建Pair RDD
//Scala中使用第一个单词作为键创建出一个pair RDD
val lines = sc.textFile("/path/README.md")
val pairs = lines.map(x => (x.split(" ")(0), x))
//Java中使用第一个单词作为键创建出一个pair RDD
JavaRDD lines = sc.textFile("/path/README.md")
JavaPairRDD pairs = lines.mapToPair(x -> new Tuple2(x.split(" ")[0], x))
当用Scala 和Python 从一个内存中的数据集创建pair RDD 时,只需要对这个由二元组组成的集合调用SparkContext.parallelize() 方法。而要使用Java 从内存数据集创建pair RDD的话,则需要使用SparkContext.parallelizePairs()。
//Java中使用parallelizePairs创建pair RDD
List> lt = new ArrayList<>();
Tuple2 tp1 = new Tuple2<>("pinda", 2);
Tuple2 tp2 = new Tuple2<>("qank", 6);
Tuple2 tp3 = new Tuple2<>("panda", 5);
lt.add(tp1);
lt.add(tp2);
lt.add(tp3);
JavaPairRDD data = js.parallelizePairs(lt);
2. Pair RDD的转化操作
2.1 基本转化操作
Pair RDD可以使用所有标准RDD上的可用的转化操作。
//Scala筛选掉长度超过20个字符的行
pairs.filter{case (key, value) => value.length < 20}
//Java筛选掉长度超过20个字符的行
Function, Boolean> longWordFilter =
new Function, Boolean>() {
public Boolean call(Tuple2 keyValue) {
return (keyValue._2().length() < 20);
}
};
JavaPairRDD result = pairs.filter(longWordFilter);


2.2 聚合操作
//在Scala 中使用reduceByKey() 和mapValues() 计算每个键对应的平均值
val rdd = sc.parallelize(List(("panda", 0), ("pink", 3), ("priate", 3), ("panda", 1), ("pink", 4)))
val keyMean = rdd.mapValues(x => (x, 1)).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
- 使用reduceByKey() 和mapValues() 计算每个键对应的平均值的数据流
| key | value | =>mapValues=> | key | value | =>reduceByKey=> | key | value |
|---|---|---|---|---|---|---|---|
| panda | 0 | panda | (0, 1) | panda | (1, 2) | ||
| pink | 3 | pink | (3, 1) | pink | (7, 2) | ||
| pirate | 3 | pirate | (3, 1) | pirate | (3, 1) | ||
| panda | 1 | panda | (1, 1) | ||||
| pink | 4 | pink | (4, 1) |
- 使用flatMap() 和 map()来生成以单词为键、以数字1 为值的pair RDD,然后使用reduceByKey() 对所有的单词进行计数。
//用Scala 实现单词计数
val input = sc.textFile("s3://...")
val words = input.flatMap(x => x.split(" "))
val result = words.map(x => (x, 1)).reduceByKey((x, y) => x + y)
//对RDD input使用countByValue() 函数,以更快地实现单词计数
val result = input.flatMap(x => x.split(" ")).countByValue()
//用Java 实现单词计数
JavaRDD input = sc.textFile("s3://...")
JavaRDD words = input.flatMap(line -> line.split(" "));
JavaPairRDD result = words.mapToPair(x -> new Tuple2(x, 1)).
reduceByKey((x, y) -> x + y);
-
combineByKey() 是最为常用的基于键进行聚合的函数。大多数基于键聚合的函数都是用它实现的。和aggregate() 一样,combineByKey() 可以让用户返回与输入数据的类型不同的返回值。
combineByKey() 有多个参数分别对应聚合操作的各个阶段,因而非常适合用来解释聚合操作各个阶段的功能划分。- combineByKey的定义
def combineByKey[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null )- 解释下3个重要的函数参数:
- createCombiner: V => C ,这个函数把当前的值作为参数,此时我们可以对其做些附加操作(类型转换)并把它返回 (这一步类似于初始化操作)
- mergeValue: (C, V) => C,该函数把元素V合并到之前的元素C(createCombiner)上 (这个操作在每个分区内进行)
- mergeCombiners: (C, C) => C,该函数把2个元素C合并 (这个操作在不同分区间进行)
- 使用combineByKey来求解平均数的例子
//在Scala 中使用combineByKey() 求每个键对应的平均值 val initialScores = Array(("Fred", 88.0), ("Fred", 95.0), ("Fred", 91.0), ("Wilma", 93.0), ("Wilma", 95.0), ("Wilma", 98.0)) val rdd = sc.parallelize(initialScores) type MVType = (Int, Double) //定义一个元组类型(科目计数器,分数) rdd.combineByKey( score => (1, score), (c1: MVType, newScore) => (c1._1 + 1, c1._2 + newScore), (c1: MVType, c2: MVType) => (c1._1 + c2._1, c1._2 + c2._2) ).map { case (name, (num, socre)) => (name, socre / num) }.collect- 参数含义的解释
- score => (1, score),我们把分数作为参数,并返回了附加的元组类型。 以"Fred"为列,当前其分数为88.0 =>(1,88.0) 1表示当前科目的计数器,此时只有一个科目
- (c1: MVType, newScore) => (c1._1 + 1, c1._2 + newScore),注意这里的c1就是createCombiner初始化得到的(1,88.0)。在一个分区内,我们又碰到了"Fred"的一个新的分数91.0。当然我们要把之前的科目分数和当前的分数加起来即c1._2 + newScorez,然后把科目计算器加1即c1._1 + 1
- (c1: MVType, c2: MVType) => (c1._1 + c2._1, c1._2 + c2._2),注意"Fred"可能是个学霸,他选修的科目可能过多而分散在不同的分区中。所有的分区都进行mergeValue后,接下来就是对分区间进行合并了,分区间科目数和科目数相加分数和分数相加就得到了总分和总科目数
- 执行结果
res1: Array[(String, Double)] = Array((Wilma,95.33333333333333), (Fred,91.33333333333333))

//Java 中使用combineByKey() 求每个键对应的平均值
public static class AvgCount implements Serializable {
public AvgCount(int total, int num) { total_ = total; num_ = num; }
public int total_;
public int num_;
public float avg() { returntotal_/(float)num_; }
}
Function createAcc = new Function() {
public AvgCount call(Integer x) {
return new AvgCount(x, 1);
}
};
Function2 addAndCount =
new Function2() {
public AvgCount call(AvgCount a, Integer x) {
a.total_ += x;
a.num_ += 1;
return a;
}
};
Function2 combine =
new Function2() {
public AvgCount call(AvgCount a, AvgCount b) {
a.total_ += b.total_;
a.num_ += b.num_;
return a;
}
};
AvgCount initial = new AvgCount(0,0);
JavaPairRDD avgCounts =
nums.combineByKey(createAcc, addAndCount, combine);
Map countMap = avgCounts.collectAsMap();
for (Entry entry : countMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue().avg());
}
- 数据分组
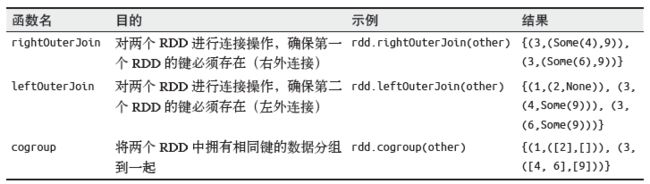
groupByKey() cogroup() - 连接
join() rightOuterJoin() leftOuterJoin() - 数据排序
sortByKey()
3. Pair RDD的行动操作
和转化操作一样,所有基础RDD支持的行动操作也都在pair RDD上可用。

4. 数据分区
4.1 获取RDD的数据分区
你可以使用RDD 的partitioner 属性(Java 中使用partitioner() 方法)来获取RDD 的分区方式。它会返回一个scala.Option 对象,这是Scala 中用来存放可能存在的对象的容器类。你可以对这个Option 对象调用isDefined() 来检查其中是否有值,调用get() 来获取其中的值
scala> import org.apache.spark.HashPartitioner
import org.apache.spark.HashPartitioner
//创建一个由(Int, Int) 对组成的RDD
scala> val pairs = sc.parallelize(List((1, 1), (2, 2), (3, 3)))
pairs: spark.RDD[(Int, Int)] = ParallelCollectionRDD[0] at parallelize at :12
//初始时没有分区方式信息(一个值为None 的Option 对象)。
scala> pairs.partitioner
res0: Option[spark.Partitioner] = None
//对第一个RDD 进行哈希分区,创建出了第二个RDD
scala> val partitioned = pairs.partitionBy(new spark.HashPartitioner(2)).persist()
partitioned: spark.RDD[(Int, Int)] = ShuffledRDD[1] at partitionBy at :14
//对RDD 完成哈希分区操作
scala> partitioned.partitioner
res1: Option[spark.Partitioner] = Some(spark.HashPartitioner@5147788d)
4.2 从分区中获益的操作
Spark 的许多操作都引入了将数据根据键跨节点进行混洗的过程。所有这些操作都会从数据分区中获益。能够从数据分区中获益的操作有cogroup()、groupWith()、join()、leftOuterJoin()、rightOuterJoin()、groupByKey()、reduceByKey()、combineByKey() 以及lookup()。
4.3 影响分区方式的操作
会为生成的结果RDD设好分区方式的操作:cogroup()、groupWith()、join()、lef tOuterJoin()、rightOuterJoin()、groupByKey()、reduceByKey()、combineByKey()、partitionBy()、sort()、mapValues()(如果父RDD 有分区方式的话)、flatMapValues()(如果父RDD 有分区方式的话),以及filter()(如果父RDD 有分区方式的话)。其他所有的操作生成的结果都不会存在特定的分区方式。
最后,对于二元操作,输出数据的分区方式取决于父RDD 的分区方式。默认情况下,结果会采用哈希分区,分区的数量和操作的并行度一样。不过,如果其中的一个父RDD 已经设置过分区方式,那么结果就会采用那种分区方式;如果两个父RDD 都设置过分区方式,结果RDD 会采用第一个父RDD 的分区方式。
4.4 自定义分区
要实现自定义的分区器,你需要继承org.apache.spark.Partitioner 类并实现下面三个方法。
- numPartitions: Int:返回创建出来的分区数。
- getPartition(key: Any): Int:返回给定键的分区编号(0 到 numPartitions-1)。
- equals():Java 判断相等性的标准方法。这个方法的实现非常重要,Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样Spark 才可以判断两个RDD 的分区方式是否相同。
4.4.1 数据分区示例
举个例子,假设我们要在一个网页的集合上运行前一节中的PageRank 算法。在这里,每个页面的ID(RDD 中的键)是页面的URL。当我们使用简单的哈希函数进行分区时,拥有相似的URL 的页面(比如http://www.cnn.com/WORLD 和http://www.cnn.com/US)可能会被分到完全不同的节点上。然而,我们知道在同一个域名下的网页更有可能相互链接。由于PageRank 需要在每次迭代中从每个页面向它所有相邻的页面发送一条消息,因此把这些页面分组到同一个分区中会更好。可以使用自定义的分区器来实现仅根据域名而不是整个URL 来分区。
//使用Scala自定义分区
class DomainNamePartitioner(numParts: Int) extends Partitioner {
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int = {
val domain = new Java.net.URL(key.toString).getHost()
val code = (domain.hashCode % numPartitions)
if(code < 0) {
code + numPartitions // 使其非负
}else{
code
}
}
// 用来让Spark区分分区函数对象的Java equals方法
override def equals(other: Any): Boolean = other match {
case dnp: DomainNamePartitioner =>
dnp.numPartitions == numPartitions
case _ =>
false
}
}
注意,在equals() 方法中,使用Scala 的模式匹配操作符(match)来检查other 是否是DomainNamePartitioner,并在成立时自动进行类型转换;这和Java 中的instanceof() 是一样的。
使用自定义的Partitioner 是很容易的:只要把它传给partitionBy() 方法即可。Spark 中有许多依赖于数据混洗的方法,比如join() 和groupByKey(),它们也可以接收一个可选的Partitioner 对象来控制输出数据的分区方式。