主题:Python招聘信息爬取与分析
1 设计方案
1.1 方案概述
近年来,随着大数据分析的火热,人工智能受到了追捧,技术创新可谓是精彩纷呈,而Python语言凭借其健全的分析库和易上手的语言特性使得越来越多的人去学习,同时也有很多人想从事Python相关的工作。那么学习python究竟需要掌握什么知识,如今python就业情况到底何,这就是本次主题式爬虫所研究的问题。
对于提出的问题,本次主题式爬虫的实现思路如下:
1.首先对拉勾网的python相关的招聘信息进行爬取。而拉勾网作为一家服务于互联网行业的垂直招聘网站,其招聘信息的数量及真实性都十分有优势,因此本次的数据来源选择拉勾网。
2.其次将爬取的数据使用python进行读取,清洗。统计薪资,工作地点,学历要求等信息。
3.最后将数据进行可视化。可视化分为两个部分,第一部分是基本统计信息用直方图,折线图等统计图表来展现。第二部分是相关职位工作内容和要求的文本分析生成词云图。
对于上述的主题式爬虫的实现思路,技术难点如下:
1.在数据采集上,不同的网站对于爬虫有着不同的限制,而拉勾网爬虫在实际的数据采集上会出现限制ip访问,输入验证码等情况。因此采集大量数据需要解决反爬虫问题。
2.在数据分析上,采集的信息可能是文本信息,所有需要处理成能够统计的数据。
1.2 数据概述
本次爬虫需要爬取拉勾网的列表页和详情页,列表页爬取职位的名称,薪资,工作地点,详情页链接等信息。而列表页则爬取职位描述信息。列表页如图1-1所示,详情页如图1-2所示。

图1-1 职位列表信息

图1-2 职位详情信息
爬取数据的特征和网页的源数据保持一致,如薪资15k-25k,存储为字符串形式的15k-25k,后续做分析时再进行处理。
2 页面结构特征分析
2.1 页面结构特征
职位列表页面每页展示15条岗位信息。通过点击翻页按钮发现其url会发生变化,因此可以通过构造url来爬取更多信息。单个列表页面的html源码如图2-1所示。通过分析源码可以发现
- 标签包含了该页面所有的职位信息。而其中的
- 标签为单个职位信息所在的节点。

图2-1 列表页部分源码
详情页可以通过列表页所包含的链接进入,详情页我们只需提取职位描述信息。其页面源码图2-2所示。即某个
标签包含整个职位描述信息。
图2-2 详情页部分源码
2.2 页面解析
通过对网页的结构进行分析后,我们可以解析页面,提取所需信息。关于页面解析的方法,我们选择了xpath来解析,无论是谷歌浏览器还是python都支持xpath。
在python中,我们可以引入第三方模块lxml来支持xpath,通过调用xpath.HTML方法将爬取的网页转化成节点树的形式,然后再依次对各个节点进行解析
2.3 网页节点分析
首先程序需要能够遍历所有的职位列表,如图2-3所示,只需找到
- 这个节点。在python中通过for循环则可以遍历所有的职位。
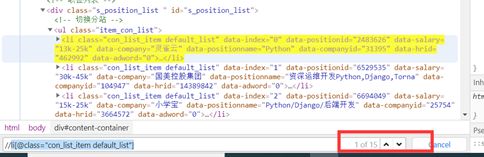
图2-3 节点分析
其次是对于某个职位的相关字段的查找,只需查看相关字段的节点的基本属性,如职位薪资所在的节点为,那么则可以通过标签名+类名直接定位到该节点。其他节点的查找方法类似,如果定位有多个,则加上其父节点来限制

图2-4 薪资所在节点解析
最后是对详情页数据所在的节点进行查找,如图2-5所示,每个
标签都列出了一条信息,最终需要将所有的信息拼接成一条完整的信息。
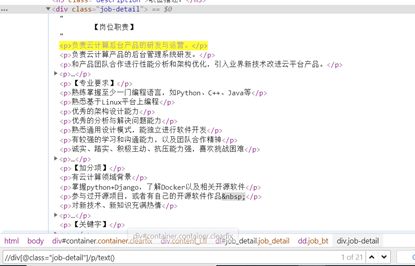
图2-5 详情页节点查找
3 程序设计
3.1 数据抓取与采集
第一步,发送请求获取数据。
使用python的requests模块发送get请求,get请求需要设置请求头和请求体,其中请求头设置如图3-1所示。请求体直接附加到url后

图3-1 设置请求头
由于拉勾网对于访问有ip限制,因此在爬取数据的过程中,如果返回的页面不正确则需要重新获取,并且降低访问次数或者使用代理ip,为了提高爬虫效率,程序使用代理ip来爬取数据,具体设置如图3-2所示

图3-2 请求数据代码
第二步,解析数据。
将发送请求后返回的html数据进行解析,使用xpath进行解析。职位列表数据解析如图3-3所示,详情页职位描述如图3-4所示。
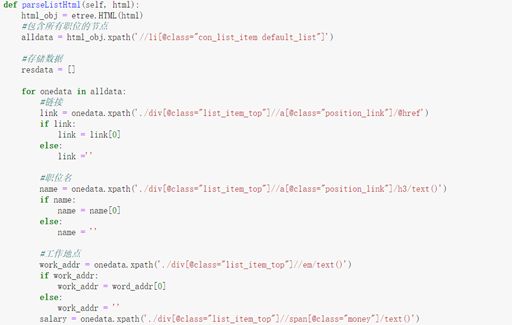

图3-3列表页解析代码

图3-4 详情页解析代码
最后一步,存储数据。
将爬取解析后的数据存入csv文件中

图3-5 存储数据代码
运行结果如下:

图3-5 程序运行过程截图

图3-6 储存数据结果
3.2 数据清洗和处理
使用python的pandas读取数据并对原始数据进行清洗。如字段要求:经验3-5年 / 本科,处理成经验要求和学历要求。代码如图3-7所示:

图3-7 数据处理代码
处理后数据结果如图3-8所示:

图3-8 清洗后数据截图
3.3 文本分析
本次文本分析主要是针对python的工作描述进行分析,得出python岗位所需要的技能有哪些,工作内容主要是什么。本次文本分析流程为:先读取数据,去除空数据;使用jieba进行分词,统计词频;最后使用wordcloud可视化画出词云图。
读取并处理数据代码如下:
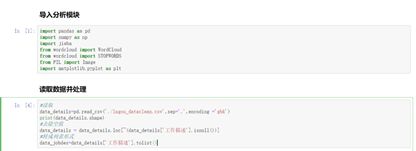
图3-9 读取数据代码
使用jieba进行分词,并且去掉停用词:
图3-10 分词代码
将词语及词频使用wordcloud画出词云图。

图3-11 画出词云图代码
词云图如图所示:

图3-12 词云图结果
3.4 数据分析及可视化
我们爬取的数据有:岗位名称,工作城市,薪资,学历,经验等。那么可以分析哪些城市工资水平最高,职位的平均工资,学历要求,经验要求的分布等。
首先使用pandas读取数据并进行基本处理。将薪资数据转换成数字类型以便于后续的计算。
图3-13 数据处理代码
然后对数据进行统计分析,可以得出各个城市工资的均值等统计数据,可用于后续的可视化。

图3-14 统计分析代码
最后将统计分析得到的数据进行可视化。

图3-15数据可视化代码
最终可视化的结果如下所示,从工资上看,一线城市薪资较高,并且平均薪资随着工作经验的增长而增长。从学历要求来看,一般企业都把门槛设置在本科层面。
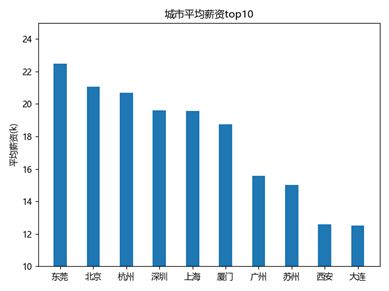
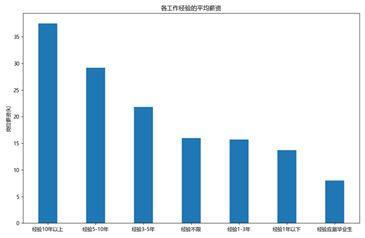

图3-16 可视化结果
3.5 数据持久化
本次分析结果主要是图片的形式,因此只需将图片保存到本地文件中即可。相关代码如图3- 17所示。

图3-17 数据持久化代码
3.6 程序代码
1、爬虫代码
import requests import pandas as pd from lxml import etree import time import random import ssl class LaGou(object): def __init__(self,ip): self.USER_AGENTS = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ] self.headers = { 'user-agent': random.choice(self.USER_AGENTS), } self.iplist = ip def getHtml(self, url): #代理ip用户名及密码 username = '1312998155' password = '1l4kuqz2' # context = ssl.context = ssl._create_unverified_context() if not self.iplist: self.iplist = getIp() ip = self.iplist[0] #构建代理 self.proxy = { "https": "https://%(user)s:%(pwd)s@%(proxy)s/" % {'user': username, 'pwd': password, 'proxy': ip}, } #发送请求 req = requests.get(url, headers=self.headers,proxies=self.proxy) print(len(req.text)) print(url) #当被限制ip时重新请求 if len(req.text)< 3000 or '欢迎进入拉勾验证系统,请进行验证' in req.text: print('aaa') self.iplist.pop(0) html = self.getHtml(url) return html else: return req.text def parseListHtml(self, html): html_obj = etree.HTML(html) alldata = html_obj.xpath('//li[@class="con_list_item default_list"]') resdata = [] # nextpage_url = html_obj.xpath('//div[@class="pager_container"]/a[last()]/@href') # if not nextpage_url: # return # print(nextpage_url) for onedata in alldata: link = onedata.xpath('./div[@class="list_item_top"]//a[@class="position_link"]/@href') if link: link = link[0] else: link ='' name = onedata.xpath('./div[@class="list_item_top"]//a[@class="position_link"]/h3/text()') if name: name = name[0] else: name = '' work_addr = onedata.xpath('./div[@class="list_item_top"]//em/text()') if work_addr: work_addr = work_addr[0] else: work_addr = '' salary = onedata.xpath('./div[@class="list_item_top"]//span[@class="money"]/text()') if salary: salary = salary[0] else: salary = '' requirement = onedata.xpath('./div[@class="list_item_top"]//div[@class="li_b_l"]/text()') if requirement: requirement = requirement[-1].strip() else: requirement = '' if link: html = self.getHtml(link) detail_data = self.parsedetailHtml(html) else: detail_data = '' resdata.append(','.join([name,work_addr,salary,requirement,detail_data])) print(name,work_addr,salary,requirement,detail_data) return resdata def parsedetailHtml(self,html): html_obj = etree.HTML(html) detail_info = html_obj.xpath('//div[@class="job-detail"]/p/text()') detail_info = ''.join(detail_info) detail_info = detail_info.replace(',',',') return detail_info def toCsv(self, data): with open('lagou_new22.csv', 'a+', encoding='utf-8') as f: for astr in data: # print(astr) f.write(astr) f.write('\n') def getIp(): url = 'http://dps.kdlapi.com/api/getdps/?orderid=907657111091795&num=4&pt=1&sep=1' response = requests.get(url) proxy = response.text.split('\r\n') return proxy def start(): # base_url = 'https://www.lagou.com/zhaopin/Python/1/?filterOption=1&sid=d13058b7da4f464aa97f378c85bd01c5' base_url = 'https://www.lagou.com/zhaopin/Python/' i = 3 ip = getIp() print(ip) l = LaGou(ip) while i<=5: url = base_url+str(i)+'/?filterOption='+str(i) print(url) html = l.getHtml(url) data = l.parseListHtml(html) print(data) l.toCsv(data) i += 1 if __name__ == '__main__': start()
2、数据清洗
import numpy as np import pandas as pd data_lagou=pd.read_csv('./lagou_new.csv',sep=',',encoding ='gbk') #处理工作城市 【深圳·科技园】-> 深圳 city = data_lagou['城市'].values for i in range(len(city)): city[i] = city[i].split('·')[0].strip() print(city) data_lagou['城市'] = city #处理要求,得到经验要求和学历要求 experience = [] education = [] requirement = data_lagou['要求'].values for i in range(len(requirement)): req = requirement[i].split('/') if len(req) == 2: experience.append(req[0].strip()) education.append(req[1].strip()) else: experience.append('null') education.append('null') print(experience,education) data_lagou['经验'] = experience data_lagou['学历'] = education tocsv_data = data_lagou[['岗位','城市','薪资','经验','学历','工作描述']] tocsv_data.to_csv('lagou_dataclean.csv',index=False)
3、文本分析代码
#!/usr/bin/env python # coding: utf-8 # ### 导入分析模块 # In[1]: import pandas as pd import numpy as np import jieba from wordcloud import WordCloud from wordcloud import STOPWORDS from PIL import Image import matplotlib.pyplot as plt # ### 读取数据并处理 # In[5]: #读取 data_details=pd.read_csv('./lagou_dataclean.csv',sep=',',encoding ='gbk') print(data_details.shape) #去除空值 data_details = data_details.loc[~(data_details['工作描述'].isnull())] #转成列表形式 data_jobdes=data_details['工作描述'].tolist() # In[6]: words=[] for content in data_jobdes: #分词 seg=jieba.lcut(content) #去除停用词 for word in seg: if word=='\n'or len(word)<=1: continue elif word in STOPWORDS: continue else: words.append(word.lower()) # In[7]: #统计词频 word_clean = pd.DataFrame({'word_clean':words}) words_count=word_clean.groupby(by=['word_clean'])['word_clean'].count().to_frame() words_count.rename(columns={'word_clean':'counts'},inplace=True) word_count_sort=words_count.reset_index().sort_values(by=['counts'],ascending=False) word_freq_dict={} for i in word_count_sort.values: word_freq_dict[i[0]]=i[1] # In[8]: plt.rcParams['figure.figsize']=(15,30) #设置画布大小 #绘制词云的基本参数 my_cloud=WordCloud( font_path='C:/Windows/Fonts/simkai.ttf', #字体格式 width=200, height=400, background_color='white', scale=32 ) cloud_pic=my_cloud.fit_words(word_freq_dict) #显示词云 plt.imshow(cloud_pic,interpolation='bilinear') #设置图像清晰度 plt.axis('off') plt.savefig(r'./cat_wordcloud.jpg') plt.show()
4、数据分析及可视化代码
#!/usr/bin/env python # coding: utf-8 # In[1]: import numpy as np import pandas as pd import re from matplotlib import pyplot as plt # ### 数据读取与处理 # In[2]: data_lagou=pd.read_csv('./lagou_dataclean.csv',sep=',',encoding ='gbk') data_lagou.head() # In[3]: salary_mean = [] #将范围设置为均值 for i in range(data_lagou.shape[0]): s = re.findall('\d+',data_lagou['薪资'][i]) if len(s) == 2: salary_mean.append((float(s[0])+float(s[1]))/2) else: salary_mean.append(0) # In[4]: #处理异常值 data_lagou['平均薪资'] = salary_mean data_lagou = data_lagou[data_lagou['平均薪资'] !=0] # ### 数据统计及可视化 # In[5]: #按城市统计薪资,并取出top10 high_salary = data_lagou.groupby(by=['城市'])['平均薪资'].mean().sort_values(ascending=False)[0:10] #按工作经验统计平均薪资 experience = data_lagou.groupby(by=['经验'])['平均薪资'].mean().sort_values(ascending=False) print(experience) #统计学历要求统计岗位数量 edu = data_lagou.groupby(by=['学历'])['学历'].count().sort_values(ascending=False) # In[12]: #显示中文 #可视化学历 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.title('各最低学历要求岗位数量占比') plt.pie(edu,labels=edu.index.tolist(),autopct='%1.1f%%') plt.savefig('./各最低学历要求岗位数量占比.jpg',dpi=300) plt.show() #可视化各工作经验要求薪资 plt.figure(figsize=(10, 6.5)) plt.bar(x=experience.index.tolist(),height=experience,width=0.4) plt.title('各工作经验的平均薪资') plt.ylabel('岗位薪资(k)') plt.savefig('./各工作经验的平均薪资.jpg',dpi=300) plt.show() #可视化城市薪资top5 #画柱状图 plt.bar(x=high_salary.index.tolist(),height=high_salary,width=0.4) plt.title('城市平均薪资top10') plt.ylabel('平均薪资(k)') plt.ylim([10,25]) plt.savefig('./城市平均薪资top10.jpg',dpi=300) plt.show()
4 结论
通过对python岗位的分析可以得出以下结论:
在文本分析上,从词云图可以发现:经验,开发,能力,学习等词出现的频率较高,可以得出我们在在找python相关的工作时要突出展现自身的能力,经验,开发水平等。而这方面薄弱的同学应该去提示相关能力。
在工资,学历等字段的统计分析,可以得出python岗位,工作时间越长,平均薪资越高。而高薪岗位主要集中在东莞,北京,上海等较发达的城市。从学历方面来看,大部分企业将学历门槛设置为本科。
通过这次主题式的爬虫设计及分析,从结果来看基本符合预期,也符合实际情况。从爬取数据来看,数据比较完整,后续可以提高数据量,从而使结果更具有说服力。对于个人而言也熟悉了许多python相关知识,对于数据爬取和分析的流程也更加明确了。
附录
 View Code
View Code1 爬虫代码 import requests import pandas as pd from lxml import etree import time import random import ssl class LaGou(object): def __init__(self,ip): self.USER_AGENTS = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ] self.headers = { 'user-agent': random.choice(self.USER_AGENTS), } self.iplist = ip def getHtml(self, url): #代理ip用户名及密码 username = '1312998155' password = '1l4kuqz2' # context = ssl.context = ssl._create_unverified_context() if not self.iplist: self.iplist = getIp() ip = self.iplist[0] #构建代理 self.proxy = { "https": "https://%(user)s:%(pwd)s@%(proxy)s/" % {'user': username, 'pwd': password, 'proxy': ip}, } #发送请求 req = requests.get(url, headers=self.headers,proxies=self.proxy) print(len(req.text)) print(url) #当被限制ip时重新请求 if len(req.text)< 3000 or '欢迎进入拉勾验证系统,请进行验证' in req.text: print('aaa') self.iplist.pop(0) html = self.getHtml(url) return html else: return req.text def parseListHtml(self, html): html_obj = etree.HTML(html) alldata = html_obj.xpath('//li[@class="con_list_item default_list"]') resdata = [] # nextpage_url = html_obj.xpath('//div[@class="pager_container"]/a[last()]/@href') # if not nextpage_url: # return # print(nextpage_url) for onedata in alldata: link = onedata.xpath('./div[@class="list_item_top"]//a[@class="position_link"]/@href') if link: link = link[0] else: link ='' name = onedata.xpath('./div[@class="list_item_top"]//a[@class="position_link"]/h3/text()') if name: name = name[0] else: name = '' work_addr = onedata.xpath('./div[@class="list_item_top"]//em/text()') if work_addr: work_addr = work_addr[0] else: work_addr = '' salary = onedata.xpath('./div[@class="list_item_top"]//span[@class="money"]/text()') if salary: salary = salary[0] else: salary = '' requirement = onedata.xpath('./div[@class="list_item_top"]//div[@class="li_b_l"]/text()') if requirement: requirement = requirement[-1].strip() else: requirement = '' if link: html = self.getHtml(link) detail_data = self.parsedetailHtml(html) else: detail_data = '' resdata.append(','.join([name,work_addr,salary,requirement,detail_data])) print(name,work_addr,salary,requirement,detail_data) return resdata def parsedetailHtml(self,html): html_obj = etree.HTML(html) detail_info = html_obj.xpath('//div[@class="job-detail"]/p/text()') detail_info = ''.join(detail_info) detail_info = detail_info.replace(',',',') return detail_info def toCsv(self, data): with open('lagou_new22.csv', 'a+', encoding='utf-8') as f: for astr in data: # print(astr) f.write(astr) f.write('\n') def getIp(): url = 'http://dps.kdlapi.com/api/getdps/?orderid=907657111091795&num=4&pt=1&sep=1' response = requests.get(url) proxy = response.text.split('\r\n') return proxy def start(): # base_url = 'https://www.lagou.com/zhaopin/Python/1/?filterOption=1&sid=d13058b7da4f464aa97f378c85bd01c5' base_url = 'https://www.lagou.com/zhaopin/Python/' i = 3 ip = getIp() print(ip) l = LaGou(ip) while i<=5: url = base_url+str(i)+'/?filterOption='+str(i) print(url) html = l.getHtml(url) data = l.parseListHtml(html) print(data) l.toCsv(data) i += 1 if __name__ == '__main__': start() 2 数据清洗代码 import numpy as np import pandas as pd data_lagou=pd.read_csv('./lagou_new.csv',sep=',',encoding ='gbk') #处理工作城市 【深圳·科技园】-> 深圳 city = data_lagou['城市'].values for i in range(len(city)): city[i] = city[i].split('·')[0].strip() print(city) data_lagou['城市'] = city #处理要求,得到经验要求和学历要求 experience = [] education = [] requirement = data_lagou['要求'].values for i in range(len(requirement)): req = requirement[i].split('/') if len(req) == 2: experience.append(req[0].strip()) education.append(req[1].strip()) else: experience.append('null') education.append('null') print(experience,education) data_lagou['经验'] = experience data_lagou['学历'] = education tocsv_data = data_lagou[['岗位','城市','薪资','经验','学历','工作描述']] tocsv_data.to_csv('lagou_dataclean.csv',index=False) 3 文本分析代码 #!/usr/bin/env python # coding: utf-8 # ### 导入分析模块 # In[1]: import pandas as pd import numpy as np import jieba from wordcloud import WordCloud from wordcloud import STOPWORDS from PIL import Image import matplotlib.pyplot as plt # ### 读取数据并处理 # In[5]: #读取 data_details=pd.read_csv('./lagou_dataclean.csv',sep=',',encoding ='gbk') print(data_details.shape) #去除空值 data_details = data_details.loc[~(data_details['工作描述'].isnull())] #转成列表形式 data_jobdes=data_details['工作描述'].tolist() # In[6]: words=[] for content in data_jobdes: #分词 seg=jieba.lcut(content) #去除停用词 for word in seg: if word=='\n'or len(word)<=1: continue elif word in STOPWORDS: continue else: words.append(word.lower()) # In[7]: #统计词频 word_clean = pd.DataFrame({'word_clean':words}) words_count=word_clean.groupby(by=['word_clean'])['word_clean'].count().to_frame() words_count.rename(columns={'word_clean':'counts'},inplace=True) word_count_sort=words_count.reset_index().sort_values(by=['counts'],ascending=False) word_freq_dict={} for i in word_count_sort.values: word_freq_dict[i[0]]=i[1] # In[8]: plt.rcParams['figure.figsize']=(15,30) #设置画布大小 #绘制词云的基本参数 my_cloud=WordCloud( font_path='C:/Windows/Fonts/simkai.ttf', #字体格式 width=200, height=400, background_color='white', scale=32 ) cloud_pic=my_cloud.fit_words(word_freq_dict) #显示词云 plt.imshow(cloud_pic,interpolation='bilinear') #设置图像清晰度 plt.axis('off') plt.savefig(r'./cat_wordcloud.jpg') plt.show() 4 数据分析及可视化代码 #!/usr/bin/env python # coding: utf-8 # In[1]: import numpy as np import pandas as pd import re from matplotlib import pyplot as plt # ### 数据读取与处理 # In[2]: data_lagou=pd.read_csv('./lagou_dataclean.csv',sep=',',encoding ='gbk') data_lagou.head() # In[3]: salary_mean = [] #将范围设置为均值 for i in range(data_lagou.shape[0]): s = re.findall('\d+',data_lagou['薪资'][i]) if len(s) == 2: salary_mean.append((float(s[0])+float(s[1]))/2) else: salary_mean.append(0) # In[4]: #处理异常值 data_lagou['平均薪资'] = salary_mean data_lagou = data_lagou[data_lagou['平均薪资'] !=0] # ### 数据统计及可视化 # In[5]: #按城市统计薪资,并取出top10 high_salary = data_lagou.groupby(by=['城市'])['平均薪资'].mean().sort_values(ascending=False)[0:10] #按工作经验统计平均薪资 experience = data_lagou.groupby(by=['经验'])['平均薪资'].mean().sort_values(ascending=False) print(experience) #统计学历要求统计岗位数量 edu = data_lagou.groupby(by=['学历'])['学历'].count().sort_values(ascending=False) # In[12]: #显示中文 #可视化学历 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.title('各最低学历要求岗位数量占比') plt.pie(edu,labels=edu.index.tolist(),autopct='%1.1f%%') plt.savefig('./各最低学历要求岗位数量占比.jpg',dpi=300) plt.show() #可视化各工作经验要求薪资 plt.figure(figsize=(10, 6.5)) plt.bar(x=experience.index.tolist(),height=experience,width=0.4) plt.title('各工作经验的平均薪资') plt.ylabel('岗位薪资(k)') plt.savefig('./各工作经验的平均薪资.jpg',dpi=300) plt.show() #可视化城市薪资top5 #画柱状图 plt.bar(x=high_salary.index.tolist(),height=high_salary,width=0.4) plt.title('城市平均薪资top10') plt.ylabel('平均薪资(k)') plt.ylim([10,25]) plt.savefig('./城市平均薪资top10.jpg',dpi=300) plt.show()
- 这个节点。在python中通过for循环则可以遍历所有的职位。