Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取豆瓣音乐专区的流行音乐
2.主题式网络爬虫爬取的内容与数据特征分析
这次爬虫主要是爬取豆瓣音乐专区流行音乐的歌手名称与受喜爱的人数。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:获取豆瓣音乐目标的HTML页面,爬取数据,使用pandas进行数据存储、读取,最后打印出来数据
技术难点:爬取数据,遍历标签属性。存储数据表格信息时
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征


2.Htmls页面解析
用鼠标右键点击查看“查看元素”选项或者按“F12”

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找:get函数,find。
遍历:for循环嵌套
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
import requests from bs4 import BeautifulSoup import pandas as pd import numpy as np #爬取豆瓣音乐目标的HTML页面 def getHTMLText(url): try: kv = {'user-agent':'Mozilla/5.0'} #获取目标页面 r = requests.get(url,headers = kv) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败" #爬取数据 def getData(nameList,numList,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #遍历所有属性为photoin的div标签 for div in soup.find_all("div",{"class":"photoin"}): #获取歌手名称 for divll in div.find_all("div",{"class":"ll"}): nameList.append(divll.a.string) #获取喜欢人数 for divpl in div.find_all("div",{"class":"pl"}): numList.append(divpl.string) #nameList.append(divll.get_text().strip()) #使用pandas进行数据存储、读取 def pdSaveRead(nameList,numList): try: #创建文件夹 os.mkdir("D:\豆瓣音乐") except: #如果文件夹存在则什么也不做 "" #创建numpy数组 r = np.array([nameList,numList]) #columns(列)名 columns_title = ['歌手名称','喜欢人数'] #创建DataFrame数据帧 df = pd.DataFrame(r.T,columns = columns_title) #将数据存在Excel表中 df.to_excel('D:\豆瓣音乐\流行歌手信息.xls',columns = columns_title) #读取表中岗位信息 dfr = pd.read_excel('D:\豆瓣音乐\流行歌手信息.xls') print(dfr.head()) #用来存储歌手名称 nameList = [] #用来存储喜欢人数 numList = [] url_part = 'https://music.douban.com/artists/genre_page/6/' page = 5 for i in range(1,page+1): #拼接成一个完整的url链接 url = url_part + str(i) #获取页面HTML代码 html = getHTMLText(url) #获取目标信息 getData(nameList,numList,html) #存储打印信息 pdSaveRead(nameList,numList)

1.数据爬取与采集

2.对数据进行清洗和处理


3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
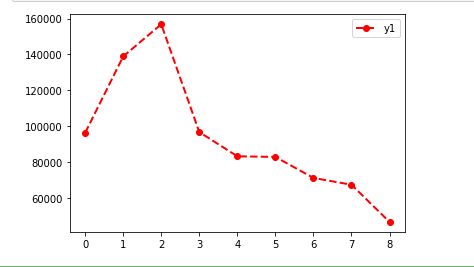
import matplotlib.pyplot as plt import numpy as np # 创建figure对象 plt.figure() # 绘制普通图像 x = [0,1,2,3,4,5,6,7,8] y1 = [96262,138861,156798,96659,83164,82825,71105,67312,46586] # 绘制y1,线条说明为'y1',线条宽度为2,颜色为红色,线型为虚线,数据标记为圆圈 plt.plot(x, y1, label='y1',linewidth = 2, linestyle='--', marker='o', color='r') # 显示图例 plt.legend() # 显示图像 plt.show()
5.数据持久化

6.附完整程序代码
import requests from bs4 import BeautifulSoup import pandas as pd import numpy as np #爬取豆瓣音乐目标的HTML页面 def getHTMLText(url): try: kv = {'user-agent':'Mozilla/5.0'} #获取目标页面 r = requests.get(url,headers = kv) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败" #爬取数据 def getData(nameList,numList,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #遍历所有属性为photoin的div标签 for div in soup.find_all("div",{"class":"photoin"}): #获取歌手名称 for divll in div.find_all("div",{"class":"ll"}): nameList.append(divll.a.string) #获取喜欢人数 for divpl in div.find_all("div",{"class":"pl"}): numList.append(divpl.string) #nameList.append(divll.get_text().strip()) #使用pandas进行数据存储、读取 def pdSaveRead(nameList,numList): try: #创建文件夹 os.mkdir("D:\豆瓣音乐") except: #如果文件夹存在则什么也不做 "" #创建numpy数组 r = np.array([nameList,numList]) #columns(列)名 columns_title = ['歌手名称','喜欢人数'] #创建DataFrame数据帧 df = pd.DataFrame(r.T,columns = columns_title) #将数据存在Excel表中 df.to_excel('D:\豆瓣音乐\流行歌手信息.xls',columns = columns_title) #读取表中岗位信息 dfr = pd.read_excel('D:\豆瓣音乐\流行歌手信息.xls') print(dfr.head()) #用来存储歌手名称 nameList = [] #用来存储喜欢人数 numList = [] url_part = 'https://music.douban.com/artists/genre_page/6/' page = 5 for i in range(1,page+1): #拼接成一个完整的url链接 url = url_part + str(i) #获取页面HTML代码 html = getHTMLText(url) #获取目标信息 getData(nameList,numList,html) #存储打印信息 pdSaveRead(nameList,numList)
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
对于豆瓣音乐的流行音乐来讲,并不是歌手越著名,歌曲的喜欢人数越多,甚至一些知名歌手的歌曲喜欢度比较低。这说明歌曲喜欢度和浏览量与歌手的名气关系不大。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
做一个任务之前,需要做许多的准备工作,要提前明确自己的目标,构建一个大致的框架,这样到写代码的步骤时才会有条不紊的进行。收集数据时也需要具备明确的目标,微数据分析打好基础。有些数据是隐藏起来的,不能爬取,在确定目标的时候需要注意。这次爬虫,期间遇到了一些小问题,最后在同学的帮助下得以解决。也对Python这门语言更加的有兴趣。对自己以后进一步学习编程有了很大帮助。