TiKV事务实现浅析
Percolator事务的理论基础
Percolator的来源
Percolator事务来源于Google在设计更新网页索引的系统时提出的论文Large-scale Incremental Processing Using Distributed Transactions and Notifications中,Google用它在支持单行事务的分布式数据库Bigtable的基础上实现跨节点的分布式事务。Percolator是一种优化版的2PC,但是与 常见的2PC不同,它并没有一个单独的coodinator的角色,而是作为一个库将所有逻辑放在客户端实现,只需要下层存储支持单行事务即可。原始的Percolator事务模型中,下层的存储节点可以对于上层事务完全无感知。

为了确定事务的先后顺序,Percolator还要求一个全局的授时中心,用于获取全局有序的递增时间戳(比如TiDB中的pd组件)。
隔离级别
Percolator事务实现了SI隔离级别(TiDB中将它作为RR)。每个事务都从授时中心获取两个时间戳:startTS 和 commitTS,startTS 在事务开始时获取,commitTS在事务结束时获取,事务之间通过这两个时间戳来确定先后。例如有两个事务T1和T2,如果T1的commitTS小于T2的startTS,则认为T1发生在T2之前 ,如果两个事务的时间戳区间[startTS, commitTS]存在交叉,则两个事务是并发的。在SI隔离级别下一个事务只应该看到commitTS小于自己的startTS的事务所写入的数据。
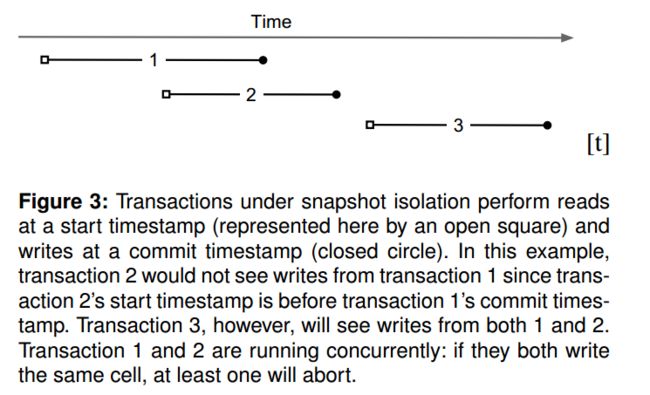
例如上图,最上面的横轴代表时间,下面三条横线分别代表三个事务T1,T2,T3,方框代表startTS,黑点代表commitTS。则T2不能读取到T1写入的数据,而T3能读取到T1和T2写入的数据。
存储模型
Percolator的存储基于Bigtable,其存储模型有列族的概念(CF),同一个列族的数据存储在一起。每个逻辑上的行分为多个列族,每个列族可以分为多个列,而其中每一列的数据以时间戳倒序排序。典型的行如下图所示:
| Key | Data | Lock | Write |
|---|---|---|---|
| Bob | 6: 5:$10 |
6: 5: |
6:data@5 5: |
| Joe | 6: 5:$2 |
6: 5: |
6:data@5 5: |
key为整个行的key,data为该行的数据。而Percolator要求额外的两个CF为:Lock和Write。Lock顾名思义表示该行的锁,而write的版本号表示写入这行数据的事务提交的时候时间戳commitTS。以Bob行为例,Key为Bob用于唯一确定该行,此时Bob没有被加锁Lock为空,在版本号为6的Write CF中有数据data@5,表示对应的数据在Data CF中版本号为5的地方。写入这行数据的事务startTS为5,commitTS为6。这里的Write CF尽管看上去额外占了一行,并不会占据额外的整行空间。
基本步骤
总体来说,TiKV 的读写事务分为两个阶段:1、Prewrite 阶段;2、Commit 阶段。
客户端会缓存本地的写操作,在客户端调用 client.Commit() 时,开始进入分布式事务 prewrite 和 commit 流程。
Prewrite 对应传统 2PC 的第一阶段
首先在所有行的写操作中选出一个作为 primary row,其他的为 secondary rows
PrewritePrimary: 对 primaryRow 写入锁以及数据,锁中记录本次事务的开始时间戳。上锁前会检查:
- 该行是否已经有别的客户端已经上锁 (Locking)
- 是否在本次事务开始时间之后,检查versions ,是否有更新 [startTs, +Inf) 的写操作已经提交 (Conflict)
在这两种种情况下会返回事务冲突。否则,就成功上锁。将行的内容写入 row 中,版本设置为 startTs
- 将 primaryRow 的锁上好了以后,进行 secondaries 的 prewrite 流程:
- 类似 primaryRow 的上锁流程,只不过锁的内容为事务开始时间 startTs 及 primaryRow 的信息
- 检查的事项同 primaryRow 的一致
- 当锁成功写入后,写入 row,时间戳设置为 startTs
以上 Prewrite 流程任何一步发生错误,都会进行回滚:删除 Lock 标记 , 删除版本为 startTs 的数据。
当 Prewrite 阶段完成以后,进入 Commit 阶段,当前时间戳为 commitTs,TSO 会保证 commitTs > startTS
Commit 的流程对应 2PC 的第二阶段
- commit primary: 写入 write CF, 添加一个新版本,时间戳为 commitTs,内容为 startTs, 表明数据的最新版本是 startTs 对应的数据
- 删除 Lock 标记
值得注意的是,如果 primary row 提交失败的话,全事务回滚,回滚逻辑同 prewrite 失败的回滚逻辑。
如果 commit primary 成功,则可以异步的 commit secondaries,流程和 commit primary 一致, 失败了也无所谓。Primary row 提交的成功与否标志着整个事务是否提交成功。
事务中的读操作
- 检查该行是否有 Lock 标记,如果有,表示目前有其他事务正占用此行,如果这个锁已经超时则尝试清除,否则等待超时或者其他事务主动解锁。注意此时不能直接返回老版本的数据。
- 读取至 startTs 时该行最新的数据,找到最近的时间戳小于startTS的write CF,从其中读取版本号t,读取为于 t 版本的数据内容。
由于锁是分两级的,Primary 和 Seconary row,只要 Primary row 的锁去掉,就表示该事务已经成功提交,这样的好处是 Secondary 的 commit 是可以异步进行的,只是在异步提交进行的过程中,如果此时有读请求,可能会需要做一下锁的清理工作。因为即使 Secondary row 提交失败,也可以通过 Secondary row 中的锁,找到 Primary row,根据检查 Primary row 的 meta,确定这个事务到底是被客户端回滚还是已经成功提交。
转账示例
下面以论文中转账的一个例子来展示大体流程,以上面的Bob和Joe为例,假设Bob要转账7元给Joe。
Prewrite
首先需要随机选择一行最为primaryRow ,这里选择Bob。以事务开始时间戳为版本号,写入Lock与数据
| Key | Data | Lock | Write |
|---|---|---|---|
| Bob | 7:$3 6: 5:$10 |
7:I am Primary 6: 5: |
7: 6:data@5 5: |
| Joe | 6: 5:$2 |
6: 5: |
6:data@5 5: |
从上图可以看出转账事务的startTS为7,所以写入了版本号为7的Lock与Bob的新数据,Lock中有表示自己是primaryLock的标志。随后进行secondary rows的上锁,这里只有Joe。
| Key | Data | Lock | Write |
|---|---|---|---|
| Bob | 7:$3 6: 5:$10 |
7:I am Primary 6: 5: |
7: 6:data@5 5: |
| Joe | 7:$9 6: 5:$2 |
7:primary@Bob 6: 5: |
7: 6:data@5 5: |
Joe的Lock中保存了primary的信息,用于找到这次提交的primary row Bob。
如果在prewrite的过程中检测到了冲突,则整个事务需要进行回滚。例如,在此时另一个事务的startTS为8,试图对Bob进行加锁,发现已经被startTS为7的事务加锁,则该事务会检测到冲突,事务回滚。也有可能发现在自己startTS以后,已经有事务提交了新的数据,出现了大于startTS的write,此时事务也需要回滚。
Commit
首先commit primary row,客户端通过Bigtable的单行事务,清除primary行的锁,并且以提交时间戳在write写入提交标志。
| key | data | lock | write |
|---|---|---|---|
| Bob | 8: 7:$3 6: 5:$10 |
8: 7: 6: 5: |
8:data@7 7: 6:data@5 5: |
| Joe | 7:$9 6: 5:$2 |
7:primary@Bob 6: 5: |
7: 6:data@5 5: |
primary row的Write CF的写入是整个事务提交的标志,这个操作的完成就意味着事务已经完成提交了。
write中写入的数据指向Bob真正存放余额的地方。完成这一步就可以向客户端返回事务commit成功了。
接下可以异步释放secondary rows的锁。如果在commit阶段发现primary锁已经不存在(可能因为超时被其他事务清除),则提交失败,事务回滚。
| key | data | lock | write |
|---|---|---|---|
| Bob | 8: 7:$3 6: 5:$10 |
8: 7: 6: 5: |
8:data@7 7: 6:data@5 5: |
| Joe | 8: 7:$9 6: 5:$2 |
8: 7: 6: 5: |
8data@7: 7: 6:data@5 5: |
实际上,即使在执行这一步前,客户端挂了而没能处理这些行的锁也没有问题。当其他事务读取到这样的行的数据的时候,通过锁可以找出primary行,从而判断出事务的状态,如果已经提交,则可以清除锁写入提交标志。
伪代码
论文中用C++风格的伪代码进行了Percolator事务流程的表达,整个事务被封装成了一个class,先来看其中需要用到的成员:
class Transaction {
// Write结构体表示一个写入操作,哪个key下的哪一个列,写入什么值
struct Write { Row row; Column col; string value; };
// writes 则为在这个事务中缓存的所有写入的集合
vector writes ;
// 事务开始的时间戳ST
int start ts ;
// 事务建立的时候获取开始时间戳
Transaction() : start ts (oracle.GetTimestamp())
//下面是各个实现函数,见下文
...
} 事务中需要用到的数据结构比较少,只保存了事务开始的时间戳和写入集合。
Perwrite阶段的伪代码:
bool Prewrite(Write w, Write primary) {
// 列族名
Column c = w.col;
// google的Percolator基于bigtable的单行事务,因此这里用bigtable::Txn表示发起单行事务
bigtable::Txn T = bigtable::StartRowTransaction(w.row);
// Abort on writes after our start timestamp . . .
// 在自己事务开启之后是否有新提交的数据
if (T.Read(w.row, c+"write", [start ts, +Inf])) return false;
// . . . or locks at any timestamp.
// 是否已经被其他事务加锁
if (T.Read(w.row, c+"lock", [0, 1])) return false;
T.Write(w.row, c+"data", start ts , w.value);
T.Write(w.row, c+"lock", start ts ,
{primary.row, primary.col}); // The primary’s location.
return T.Commit();
}prewite阶段如上文所说,在进行冲突检测后写入了Lock和数据。这是对某一行进行prewrite的函数,在整个提交阶段被多次调用。伪代码中的commit代表整个percolator事务的提交:
bool Commit() {
Write primary = writes[0];
vector secondaries(writes .begin()+1, writes .end());
// 对所有参与事务的行执行Prewrite
// 先对随机选出的某一个primary行加锁,再对其他行加锁。
if (!Prewrite(primary, primary)) return false;
for (Write w : secondaries)
if (!Prewrite(w, primary)) return false;
// 获取提交时间戳commitTS
int commit ts = oracle .GetTimestamp();
// Commit primary first.
Write p = primary;
bigtable::Txn T = bigtable::StartRowTransaction(p.row);
// 失去了锁,可能被别人终止了,事务回滚
if (!T.Read(p.row, p.col+"lock", [start ts , start ts ]))
return false; // aborted while working
// 向primary行的Write CF写入提交标志,时间戳为commitTS
T.Write(p.row, p.col+"write", commit ts,
start ts ); // Pointer to data written at start ts .
//擦除primary的锁
T.Erase(p.row, p.col+"lock", commit ts);
if (!T.Commit()) return false; // commit point
// Second phase: write out write records for secondary cells.
// 在其他行同样进行写入Write CF 并且擦除锁
for (Write w : secondaries) {
bigtable::Write(w.row, w.col+"write", commit ts, start ts );
bigtable::Erase(w.row, w.col+"lock", commit ts);
}
return true;
} 读取操作的伪代码如下:
bool Get(Row row, Column c, string* value) {
while (true) {
bigtable::Txn T = bigtable::StartRowTransaction(row);
// Check for locks that signal concurrent writes.
if (T.Read(row, c+"lock", [0, start ts ])) {
// There is a pending lock; try to clean it and wait
// 注意,这里如果锁没有超时的情况下不能直接返回最近的可见数据
// 必须等待持锁事务commit或者回滚,直到超时清除它
BackoffAndMaybeCleanupLock(row, c);
continue;
}
// 按照时间戳读取最新的可见的数据
// Find the latest write below our start timestamp.
latest write = T.Read(row, c+"write", [0, start ts ]);
if (!latest write.found()) return false; // no data
int data ts = latest write.start timestamp();
*value = T.Read(row, c+"data", [data ts, data ts]);
return true;
}
}在读取操作的时候需要注意遇到锁的情况,如果检查primary row发现事务已经提交则可以由自己清除secondary row的锁。如果有没有commit的其他事务持有锁,不能够直接返回最新的对自己可见的数据。如上面转账的例子中正处于prewrite阶段,此时另一个startTS为9的事务来进行对Joe的读取操作:
| Key | Data | Lock | Write |
|---|---|---|---|
| Bob | 7:$3 6: 5:$10 |
7:I am Primary 6: 5: |
7: 6:data@5 5: |
| Joe | 7:$9 6: 5:$2 |
7:primary@Bob 6: 5: |
7: 6:data@5 5: |
此时能否直接通过版本号为6的write中的信息,返回版本号为5中的数据呢?不能,因为在Percolator的模型中,事务的先后顺序是通过逻辑时间戳来确定的,从Joe和Bob中我们只能够得到持锁事务的startTS,无法得知commitTS,而SI隔离级别要求我们应该读取到commitTS小于9的事务写入的数据,只有等到持锁事务提交,才能得知它的commitTS是小于9还是大于9。
TiDB事务与MySQL的区别
TiDB 使用乐观事务模型,在执行 Update、Insert、Delete 等语句时,只有在提交过程中,执行 Update,Insert,Delete 等语句时才会检查写写冲突,而不是像 MySQL 一样使用行锁来避免写写冲突。类似的, SELECT .. FOR UPDATE 之类的语句在 TiDB 和 MySQL 中的执行方式并不相同。TiDB的隔离级别的表现也与MySQL不尽相同,虽然TiDB也有对应MySQL的RR和RC隔离级别,但RR级别实质为SI级别,而RC隔离级别的则违反了线性一致。目前TiDB也在实现悲观锁的事务模型,但是官方文档说还处于试验阶段尚不稳定,不建议开启。
行为差异
由于tidb的基于的事务模型与mysql有较大区别,所以在实际使用中尽管协议兼容,但是事务的行为依然有比较大的区别。
写入缓存在客户端
从Peroclator的模型中可以看出所有的修改操作都先缓存在客户端,只有在事务提交的时候才会进行冲突检测。所以许多在mysql中会导致阻塞的操作在tidb中并不会。假设有一张表test96如下:
| test96 | CREATE TABLE `test96` (
`a` int(11) NOT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin并向其中插入数据:
mysql> insert into test96 values(1,1),(2,2),(4,4);
Query OK, 3 rows affected (0.01 sec)处于RR(SI)隔离级别下(tidb的RC隔离级别不完善,不建议使用,后文会提到),开启两个事务t1,t2进行如下操作
| t1 | t2 | |
|---|---|---|
| step1 | begin; | begin; |
| step2 | update test96 set b = 100 where a >= 2; | |
| step3 | update test96 set b = 98 where a = 4; | |
| step4 | commit | |
| step5 | commit |
如果在mysql中,t2在step3的更新操作将会被t1阻塞,而当t1在step4 commit后,t2的后续操作也能成功。然而在tidb中,t1,t2的update操作都会返回成功。并且此时去select的话还可以发现数据已经被自己修改。
对于t1
mysql> select * from test96;
+---+------+
| a | b |
+---+------+
| 1 | 1 |
| 2 | 100 |
| 4 | 100 |
+---+------+
3 rows in set (0.00 sec)
对于t2
mysql> select * from test96;
+---+------+
| a | b |
+---+------+
| 1 | 1 |
| 2 | 2 |
| 4 | 98 |
+---+------+
3 rows in set (0.01 sec)这是因为事务在读取的过程中发现数据被本事务修改过,所以直接从本地缓存中读取。
在step4,t1的commit可以成功
mysql> commit;
Query OK, 0 rows affected (0.00 sec)而step5,t2 commit的时候会报错
mysql> commit;
ERROR 1105 (HY000): [try again later]: [write conflict] txnStartTS 408979633880694785 is stale如上文对percolator的描述,在提交的时候,事务进行了冲突检测,发现事务冲突,因此t2被回滚。
自动重试
执行失败的事务可以让 TiDB 自动重试提交,但这可能会导致事务异常。当开启自动重试的时候前文中的例子t1, t2的提交都会成功,这实际上与SI隔离级别的要求不符。有两个参数与这个功能相关
tidb_disable_txn_auto_retry
作用域:SESSION | GLOBAL
默认值:1
这个变量用来设置是否禁用显式事务自动重试,设置为 1 时,不会自动重试,如果遇到事务冲突需要在应用层重试。
这个变量不会影响自动提交的隐式事务和 TiDB 内部执行的事务,它们依旧会根据 tidb_retry_limit 的值来决定最大重试次数。
tidb_retry_limit
作用域:SESSION | GLOBAL
默认值:10
这个变量用来设置最多可重试次数,即在一个事务执行中遇到可重试的错误(例如事务冲突、事务提交过慢或表结构变更)时,这个事务可以被重新执行,这个变量值表明最多可重试的次数。
通过设置 tidb_disable_txn_auto_retry可以控制该项功能,同时要注意 tidb_retry_limit 的值不能为 0,否则,也会禁用自动重试。
大事务
同时,由于受客户端能缓存的数据量的限制,tidb对大事务的支持有限,在官方手册中声明了事务大小的限制:
- 单个事务包含的 SQL 语句不超过 5000 条(默认)
- 每个键值对不超过 6MB
- 键值对的总数不超过 300,000
- 键值对的总大小不超过 100MB
tidb中有个tidb_batch_insert参数可以自动将大事务分隔为一系列小事务执行
tidb_batch_insert
作用域: SESSION
默认值: 0
这个变量用来设置是否自动切分插入数据。仅在 autocommit 开启时有效。 当插入大量数据时,可以将其设置为 1,这样插入数据会被自动切分为多个 batch,每个 batch 使用一个单独的事务进行插入。 该用法破坏了事务的原子性,因此,不建议在生产环境中使用。小事务延时
由于 TiDB 中的每个事务都需要跟 PD leader 进行两次 round trip以获取时间戳,TiDB 中的小事务相比于 MySQL 中的小事务延迟更高。以如下的 query 为例,用显式事务代替 auto_commit,可优化该 query 的性能。
# 使用 auto_commit 的原始版本
UPDATE my_table SET a='new_value' WHERE id = 1;
UPDATE my_table SET a='newer_value' WHERE id = 2;
UPDATE my_table SET a='newest_value' WHERE id = 3;
# 优化后的版本
START TRANSACTION;
UPDATE my_table SET a='new_value' WHERE id = 1;
UPDATE my_table SET a='newer_value' WHERE id = 2;
UPDATE my_table SET a='newest_value' WHERE id = 3;
COMMIT;把合理数量的更新打包到一个事务里有利于减小延时,但不宜过大,不能超过限制或者造成较多的冲突。
Load data
语法基本一致但是分隔符只支持‘//‘
LOAD DATA LOCAL INFILE 'file_name' INTO TABLE table_name
{FIELDS | COLUMNS} TERMINATED BY 'string' ENCLOSED BY 'char' ESCAPED BY 'char'
LINES STARTING BY 'string' TERMINATED BY 'string'
IGNORE n LINES
(col_name ...);而且,由于不支持大事务实际上数量大时,是把Load data分隔为了多个事务,默认将每 2 万行记录作为一个事务进行持久化存储。如果一次 LOAD DATA 操作插入的数据超过 2 万行,那么会分为多个事务进行提交。如果某个事务出错,这个事务会提交失败,但它前面的事务仍然会提交成功,在这种情况下,一次 LOAD DATA 操作会有部分数据插入成功,部分数据插入失败。官方不建议在生产中使用Load data。
隔离级别
tidb实现了SI隔离级别,为了与MySQL保持一致,也称其RR隔离级别。但其表现有区别。
丢失更新
mysql的RR隔离级别会存在丢失更新的情况,依然以表test96为例
| test96 | CREATE TABLE `test96` (
`a` int(11) NOT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_binmysql> insert into test96 values(1,1),(2,2),(4,4);
Query OK, 3 rows affected (0.01 sec)执行两个事务t1与t2,每个事务对a=2这一行数据的b列加1,我们希望b列记录执行的事务的数量。
| t1 | t2 | |
|---|---|---|
| step1 | begin; | begin; |
| step2 | select b from test96 where a = 2; | select b from test96 where a = 2; |
| step3 | update test96 set b = 3 where a = 2;(计数器+1) | |
| step4 | update test96 set b = 3 where a= 2 (在mysql中这一步将会阻塞,但是tidb中会立即返回成功) | |
| step5 | commit | (对于mysql,t1提交后t2此时可以继续执行) |
| step6 | commit (mysql提交成功,tidb会让t2回滚报错) |
在mysql中由于t2提交的时候其实t1已经提交写入,t2用于计算的前提条件其实已经不成立了,t2的更新覆盖了t1的更新,执行了两个事务之后,b只加了1。而在tidb中,首先,由于写入是缓存在本地,所以step4并不会造成阻塞,而在commit的时候,percolator的prewrite阶段会检查到b被更新过,t2提交失败,回滚报错。(就上面这种数值计算的特殊情况而言,如果在MySQL中用update test96 set b = b+1最后我们会得到正确的结果,这里只是为了方便举例才用了读取-计算-写入的模式。)
幻读
tidb的SI级别可以避免经典意义上的幻读,在前文Percolator的读取步骤中可以看出,只要数据的commitTS大于本事务的startTS,就不会被读取到,在著名论文A critique of ANSI SQL isolation levels中对于经典幻读的定义为
Transaction T1 reads a set of data items satisfying some . Transaction T2 then creates data items that satisfy T1’s and commits. If T1 then repeats its read with the same , it gets a set of data items
different from the first read. 可见tidb不会出现经典意义上的幻读
那么对于MySQL而言会吗?一眼看去MySQL使用了MVCC机制,即使别人插入了一条满足自己select筛选条件的数据,在RR隔离级别下由于ReadView不会更新的原因应该也不可能读取到,然而并不是所有情况下都是如此,依然以上面的表test96为例
| t1 | t2 | |
|---|---|---|
| step1 | begin; | begin; |
| step2 | select b from test96 where a > 1; | |
| step3 | insert into test96 values(3, 3); | |
| step4 | commit; | |
| step5 | select b from test96 where a > 1; | |
| step6 | update test96 set b = 0 where a > 1; | |
| step7 | select b from test96 where a > 1; |
对于step2与step5的select语句,mysql和tidb的行为一致,结果为
mysql> select * from test96 where a>1;
+---+------+
| a | b |
+---+------+
| 2 | 2 |
| 4 | 4 |
+---+------+
2 rows in set (0.01 sec)而在step6的update之后,在step7再次进行select,tidb的结果行数依然看到的是a=2与a=4两行
mysql> select * from test96 where a>1;
+---+------+
| a | b |
+---+------+
| 2 | 0 |
| 4 | 0 |
+---+------+
2 rows in set (0.00 sec)而对于MySQL,却能见到出乎意料的结果
mysql> select * from test96 where a>1;
+---+------+
| a | b |
+---+------+
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
+---+------+
3 rows in set (0.00 sec)mysql中,t1的读取操作虽然通过MVCC读取不到t2的值,但是由于更新操作总是使用最新版本,a=3的这行数据也满足条件,所以这行数据也被更新了。问题在于隐藏列trx_id的值也被更新了(或者说根本就是一个新的版本),因此进行读取的时候这行数据会读取到t1写入的版本,所以我们可以读取到一条意外出现的记录。事实上,我们在mysql中进行step6的update操作的时候,可以看到虽然只能读取到2行,但update影响行数为3行。
mysql> select * from test96 where a>1;
+---+------+
| a | b |
+---+------+
| 2 | 2 |
| 4 | 4 |
+---+------+
2 rows in set (0.00 sec)
mysql> update test96 set b = 0 where a>1;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0而在tidb中只更新了自己读取到的2行
mysql> select * from test96 where a>1;
+---+------+
| a | b |
+---+------+
| 2 | 2 |
| 4 | 4 |
+---+------+
2 rows in set (0.00 sec)
mysql> update test96 set b=0 where a > 1;
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0而在t1提交后,从tidb再次select可以查到a=3这条数据
mysql> select * from test96 where a>1;
+---+------+
| a | b |
+---+------+
| 2 | 0 |
| 3 | 3 |
| 4 | 0 |
+---+------+
3 rows in set (0.01 sec)所以MySQL依然存在经典意义上幻读
写偏序
ANSI定义的RR隔离级别下不会发生写偏序,tidb与mysql的RR隔离级别下都可能存在写偏序。依然以上面test96表为例,假设我们的约束要求b > 1的记录数量不能为0。
| t1 | t2 | |
|---|---|---|
| step1 | begin; | begin; |
| step2 | select count(*) from test96 where b > 1; | select count(*) from test96 where b > 1; |
| step3 | if count > 1 {update test96 set b = 0 where a = 2;} | |
| step4 | if count > 1 {update test96 set b = 0 where a = 4;} | |
| step5 | commit | |
| step6 | commit |
由于t1与t2没有写同一份数据,两者在tidb和mysql中都会直接提交成功。但是最终test96中 b > 1的记录数变成了0,这违背了我们的约束。
For update
tidb与mysql都支持for update 语法,但是行为表现有一定区别。对于mysql而言,for update是在读取的时候对记录实时的加锁,阻塞其他试图修改或者带for update的语句。而对于tidb而言,for update本质上只是在本地缓存一个写入,只是写入的只有一个锁,没有数据, 相当于对符合条件的记录进行了一次没有数据的写入。同时,tidb目前尚不支持谓词锁或类似mysql的gap锁,所以即使在RR隔离级别下使用for update, 也不能防止其他事务的insert操作。先来看一个test96表上的例子
| t1 | t2 | |
|---|---|---|
| step1 | begin; | begin; |
| step2 | select count(*) from test96 where a > 1 for update; | |
| step3 | update test96 set b = 0 where a = 4 | |
| step4 | commit | |
| step5 | commit |
在mysql中t2在step3的update操作会被阻塞,直到t1提交,之后t2的执行会成功。然而在tidb中,t2的update操作会返回成功,而在t2提交的时候会报错发生冲突,t2回滚。
mysql> update test96 set b = 0 where a = 4;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
ERROR 1105 (HY000): [try again later]: [write conflict] txnStartTS=409004592597827585, conflictTS=409004587970985985, key={tableID=530, handle=4} primary={tableID=530, handle=4}同时由于tidb没有谓词锁或gap锁,不能锁定范围,如果把t2 step3的操作修改如下 ,t1与t2都将提交成功。
| t1 | t2 | |
|---|---|---|
| step1 | begin; | begin; |
| step2 | select count(*) from test96 where a > 1 for update; | |
| step3 | insert into test96 values(3,3); | |
| step4 | commit | |
| step5 | commit |
Tikv中的事务实现
论文percolator原型中,所有的事务相关操作都在客户端执行,服务端不需要进行任何特殊处理。但是在tikv中,服务端对于不同的阶段做了不同的处理,以优化性能。
Tikv客户端实现
Tikv本身作为一个分布式的kv存储供计算层的tidb访问,同时也提供了单独client客户端以直接使用tikv。独立客户端的逻辑与tidb中对tikv的访问逻辑基本相同,许多代码都是复用的,tidb多了一些生成binlog和保存统计信息等额外操作。下面以golang版本的client为例,介绍tikv客户端的实现。
客户端使用
客户端的使用上非常简洁,下面两个官方示例中的函数对tikv进行了set和get操作
// key1 val1 key2 val2 ...
func puts(args ...[]byte) error {
tx, err := client.Begin()
if err != nil {
return err
}
for i := 0; i < len(args); i += 2 {
key, val := args[i], args[i+1]
err := tx.Set(key, val)
if err != nil {
return err
}
}
return tx.Commit(context.Background())
}func get(k []byte) (KV, error) {
tx, err := client.Begin()
if err != nil {
return KV{}, err
}
v, err := tx.Get(k)
if err != nil {
return KV{}, err
}
return KV{K: k, V: v}, nil
}从上面可以看出,事务api的使用比较简洁,只需要Begin开启一个事务,进行Get,Set等操作,然后Commit即可。
写入
Transaction
Transaction是所有事务操作的入口,Transaction的结构体如下
// Transaction is a key-value transaction.
type Transaction struct {
// 用于访问tikv
tikvStore *store.TiKVStore
snapshot *store.TiKVSnapshot
// 本地缓存数据
us kv.UnionStore
// 即percolator事务模型中的开始时间戳startTS,创建事务的时候从TSO获取
startTS uint64
startTime time.Time // Monotonic timestamp for recording txn time consuming.
// 注意,这个commitTS并不是percolator中的commitTS,实际上在client中并没有发现有使用这个变量
// percolator真正的commitTS在TxnCommitter中。在tidb中有类似的变量,用于保存提交时间戳供统计。
// 也许是从tidb中复用代码的时候搬过来忘了删除?
commitTS uint64
valid bool
lockKeys [][]byte
setCnt int64
}Transaction的方法提供了Get,Set,Del等多种数据操作,所有的修改都将保存在本地缓存us中,在Commit的时候按照percolator的事务模型进行提交。下面是Commit的简化代码。
// Commit commits the transaction operations to KV store.
func (txn *Transaction) Commit(ctx context.Context) error {
···
if len(mutations) == 0 {
return nil
}
···
// committer是percolator事务具体提交的执行者,mutations为所有的修改集合
committer, err := store.NewTxnCommitter(txn.tikvStore, txn.startTS, txn.startTime, mutations)
if err != nil || committer == nil {
return err
}
// latch是一个特性,开启的话同一个客户端发起的请求如果有冲突可以先在本地解决,需要先获取本地latch
// 用于解决冲突过于严重的情况
// latches disabled
if txn.tikvStore.GetTxnLatches() == nil {
// 未开启latch则直接开始2pc提交
err = committer.Execute(ctx)
log.Debug("[kv]", txn.startTS, " txnLatches disabled, 2pc directly:", err)
return err
}
// latches enabled
// for transactions which need to acquire latches
start = time.Now()
lock := txn.tikvStore.GetTxnLatches().Lock(txn.startTS, committer.GetKeys())
localLatchTime := time.Since(start)
if localLatchTime > 0 {
metrics.LocalLatchWaitTimeHistogram.Observe(localLatchTime.Seconds())
}
defer txn.tikvStore.GetTxnLatches().UnLock(lock)
if lock.IsStale() {
err = errors.Errorf("startTS %d is stale", txn.startTS)
return errors.WithMessage(err, store.TxnRetryableMark)
}
// 开启了latch则先获取本地latch后再开始2PC
err = committer.Execute(ctx)
if err == nil {
lock.SetCommitTS(committer.GetCommitTS())
}
log.Debug("[kv]", txn.startTS, " txnLatches enabled while txn retryable:", err)
return err
}在提交过程中,Transaction收集好所有的修改,将startTS和修改的数据传递给TxnCommitter,由TxnCommitter执行具体的提交过程。
TxnCommitter
TxnCommitter负责事务的提交过程,下面是其简化结构体
// TxnCommitter executes a two-phase commit protocol.
type TxnCommitter struct {
// tikv访问接口
store *TiKVStore
conf *config.Config
// 开始时间戳
startTS uint64
// 所有修改数据的key
keys [][]byte
// 所有修改操作
mutations map[string]*pb.Mutation
// 锁的最长生命周期,持锁时间太长可能会被其他事务清除,本事务回滚。
lockTTL uint64
// 事务的提交时间戳
commitTS uint64
mu struct {
sync.RWMutex
committed bool
// 这个标志位表示是否收到了无法确定事务的状态的错误,例如因网络原因未收到c事务的commit指令的回应
undeterminedErr error // undeterminedErr saves the rpc error we encounter when commit primary key.
}
cleanWg sync.WaitGroup
}Txn的Execute函数是实际的提交执行流程,由外部调用(Transaction的Commit),下面是简化流程
// Execute executes the two-phase commit protocol.
func (c *TxnCommitter) Execute(ctx context.Context) error {
// 如果事务没有设置提交标志并且没有发生无法确定事务状态的错误(也就是说可以确定事务回滚了)
// 则清除可能已经prewrite的数据
defer func() {
// Always clean up all written keys if the txn does not commit.
c.mu.RLock()
committed := c.mu.committed
undetermined := c.mu.undeterminedErr != nil
c.mu.RUnlock()
// 如果可以确定事务未能提交,则尝试异步的进行清理
if !committed && !undetermined {
c.cleanWg.Add(1)
go func() {
err := c.cleanupKeys(retry.NewBackoffer(context.Background(), retry.CleanupMaxBackoff), c.keys)
if err != nil {
log.Infof("con:%d 2PC cleanup err: %v, tid: %d", c.ConnID, err, c.startTS)
} else {
log.Infof("con:%d 2PC clean up done, tid: %d", c.ConnID, c.startTS)
}
c.cleanWg.Done()
}()
}
}()
// Backoffer是用于控制重试的结构体
prewriteBo := retry.NewBackoffer(ctx, retry.PrewriteMaxBackoff)
start := time.Now()
// 执行percolator的第一阶段,prewrite
err := c.prewriteKeys(prewriteBo, c.keys)
if err != nil {
log.Debugf("con:%d 2PC failed on prewrite: %v, tid: %d", c.ConnID, err, c.startTS)
return err
}
// 获取提交时间戳
commitTS, err := c.store.GetTimestampWithRetry(retry.NewBackoffer(ctx, retry.TsoMaxBackoff))
if err != nil {
log.Warnf("con:%d 2PC get commitTS failed: %v, tid: %d", c.ConnID, err, c.startTS)
return err
// check commitTS
if commitTS <= c.startTS {
err = errors.Errorf("con:%d Invalid transaction tso with start_ts=%v while commit_ts=%v",
c.ConnID, c.startTS, commitTS)
log.Error(err)
return err
}
c.commitTS = commitTS
// 事务消耗的时间不能超过设定的最大时间
if c.store.GetOracle().IsExpired(c.startTS, c.maxTxnTimeUse) {
err = errors.Errorf("con:%d txn takes too much time, start: %d, commit: %d", c.ConnID, c.startTS, c.commitTS)
return errors.WithMessage(err, TxnRetryableMark)
}
start = time.Now()
commitBo := retry.NewBackoffer(ctx, retry.CommitMaxBackoff)
// percolator第二阶段,commit
err = c.commitKeys(commitBo, c.keys)
if err != nil {
···
return nil
}Eexcute的主要逻辑就是对应的percolator的两个步骤,中间做了一些合法性检查,在函数的最后如果事务不能正常提交,则需要尝试清除已经提交的数据。在上面的函数中可以看到prewriteKeys和commitKeys两个函数,这两个函数未内部两个阶段的对应。
func (c *TxnCommitter) prewriteKeys(bo *retry.Backoffer, keys [][]byte) error {
return c.doActionOnKeys(bo, actionPrewrite, keys)
}
func (c *TxnCommitter) commitKeys(bo *retry.Backoffer, keys [][]byte) error {
return c.doActionOnKeys(bo, actionCommit, keys)
}由于两个阶段的操作都有较多共性,可以通过batch的方式来提高性能,所以这里采用了同一个函数doActionOnKeys来进行处理。
func (c *TxnCommitter) doActionOnKeys(bo *retry.Backoffer, action commitAction, keys [][]byte) error {
if len(keys) == 0 {
return nil
}
groups, firstRegion, err := c.store.GetRegionCache().GroupKeysByRegion(bo, keys)
if err != nil {
return err
}
var batches []batchKeys
···
// Make sure the group that contains primary key goes first.
// 按照key的region分布和大小打包分组,每个分组的key可以保证在一个region
commitBatchSize := c.conf.Txn.CommitBatchSize
batches = appendBatchBySize(batches, firstRegion, groups[firstRegion], sizeFunc, commitBatchSize)
delete(groups, firstRegion)
for id, g := range groups {
batches = appendBatchBySize(batches, id, g, sizeFunc, commitBatchSize)
}
firstIsPrimary := bytes.Equal(keys[0], c.primary())
// 在commit阶段的时候的时候,primaryRow需要先处理,因为primaryRow的提交被视为整个事务提交与否的标志。
if firstIsPrimary && (action == actionCommit || action == actionCleanup) {
// primary should be committed/cleanup first
err = c.doActionOnBatches(bo, action, batches[:1])
if err != nil {
return err
}
batches = batches[1:]
}
if action == actionCommit {
// Commit secondary batches in background goroutine to reduce latency.
// The backoffer instance is created outside of the goroutine to avoid
// potencial data race in unit test since `CommitMaxBackoff` will be updated
// by test suites.
secondaryBo := retry.NewBackoffer(context.Background(), retry.CommitMaxBackoff)
// 这里可以看出secondaryRows是异步提交的,只要primaryRow提交成功就会给客户端返回成功
go func() {
e := c.doActionOnBatches(secondaryBo, action, batches)
if e != nil {
log.Debugf("con:%d 2PC async doActionOnBatches %s err: %v", c.ConnID, action, e)
}
}()
} else {
err = c.doActionOnBatches(bo, action, batches)
}
return err
}doActionOnKeys将需要修改的key进行打包,交给doActionOnBatches进行处理,如果是commit阶段,则需要保证primaryRow先进行处理。在上面还可以看出这里可以看出secondaryRows是异步提交的,只要primaryRow提交成功就会给客户端返回成功。这造成了一个问题,在RC隔离级别下,tikv在查询数据的时候并没有检查lock的信息,而是直接找一个最近的本地已经提交版本返回给客户端,所以如果某个事务已经提交但secondaryRows还未释放,此时另一个事务是无法读取到这个事务写入的数据的,这与正常的RC级别的表现不符。
func (c *TxnCommitter) doActionOnBatches(bo *retry.Backoffer, action commitAction, batches []batchKeys) error {
if len(batches) == 0 {
return nil
}
var singleBatchActionFunc func(bo *retry.Backoffer, batch batchKeys) error
// singleBatchActionFunc是对单个batch的处理函数,主要进行grpc数据包的封装发送和错误处理。
switch action {
case actionPrewrite:
singleBatchActionFunc = c.prewriteSingleBatch
case actionCommit:
singleBatchActionFunc = c.commitSingleBatch
case actionCleanup:
singleBatchActionFunc = c.cleanupSingleBatch
}
if len(batches) == 1 {
e := singleBatchActionFunc(bo, batches[0])
if e != nil {
log.Debugf("con:%d 2PC doActionOnBatches %s failed: %v, tid: %d", c.ConnID, action, e, c.startTS)
}
return e
}
// For prewrite, stop sending other requests after receiving first error.
// prewrite阶段一旦出错就取消所有后续动作
backoffer := bo
var cancel context.CancelFunc
if action == actionPrewrite {
backoffer, cancel = bo.Fork()
defer cancel()
}
// Concurrently do the work for each batch.
ch := make(chan error, len(batches))
for _, batch1 := range batches {
batch := batch1
go func() {
if action == actionCommit {
// Because the secondary batches of the commit actions are implemented to be
// committed asynchronously in background goroutines, we should not
// fork a child context and call cancel() while the foreground goroutine exits.
// Otherwise the background goroutines will be canceled exceptionally.
// Here we makes a new clone of the original backoffer for this goroutine
// exclusively to avoid the data race when using the same backoffer
// in concurrent goroutines.
// commit阶段只要primaryRow提交成功即可
singleBatchBackoffer := backoffer.Clone()
ch <- singleBatchActionFunc(singleBatchBackoffer, batch)
} else {
singleBatchBackoffer, singleBatchCancel := backoffer.Fork()
defer singleBatchCancel()
ch <- singleBatchActionFunc(singleBatchBackoffer, batch)
}
}()
}
var err error
for i := 0; i < len(batches); i++ {
if e := <-ch; e != nil {
log.Debugf("con:%d 2PC doActionOnBatches %s failed: %v, tid: %d", c.ConnID, action, e, c.startTS)
// Cancel other requests and return the first error.
if cancel != nil {
log.Debugf("con:%d 2PC doActionOnBatches %s to cancel other actions, tid: %d", c.ConnID, action, c.startTS)
cancel()
}
if err == nil {
err = e
}
}
}
return err
}doActionOnBatches对每个batch进行处理,发送rpc请求给tikv服务端。其中,对于prewrite和commit的处理有所不同,prewrite如果其中某一个batch的写入有错,需要全部撤销;而commit阶段的时候如果是secondaryRows,则不会取消,因为此时事务被认为已经提交了。
各个xxxxSingleBatch函数是对每个batch的具体处理,根据具体阶段的不同分别进行不同的处理。
prewriteSingleBatch
func (c *TxnCommitter) prewriteSingleBatch(bo *retry.Backoffer, batch batchKeys) error {
mutations := make([]*pb.Mutation, len(batch.keys))
for i, k := range batch.keys {
mutations[i] = c.mutations[string(k)]
}
// 组装rpc请求
req := &rpc.Request{
Type: rpc.CmdPrewrite,
Prewrite: &pb.PrewriteRequest{
Mutations: mutations,
PrimaryLock: c.primary(),
StartVersion: c.startTS,
LockTtl: c.lockTTL,
},
Context: pb.Context{
Priority: c.Priority,
SyncLog: c.SyncLog,
},
}
for {
// 发送请求并进行各种错误处理
resp, err := c.store.SendReq(bo, req, batch.region, c.conf.RPC.ReadTimeoutShort)
if err != nil {
return err
}
regionErr, err := resp.GetRegionError()
if err != nil {
return err
}
// TikcStore缓存的region信息有误,连接pd重试提交
if regionErr != nil {
err = bo.Backoff(retry.BoRegionMiss, errors.New(regionErr.String()))
if err != nil {
return err
}
return c.prewriteKeys(bo, batch.keys)
}
prewriteResp := resp.Prewrite
if prewriteResp == nil {
return errors.WithStack(rpc.ErrBodyMissing)
}
// prewrite成功
keyErrs := prewriteResp.GetErrors()
if len(keyErrs) == 0 {
return nil
}
var locks []*Lock
for _, keyErr := range keyErrs {
// Check already exists error
if alreadyExist := keyErr.GetAlreadyExist(); alreadyExist != nil {
return errors.WithStack(ErrKeyAlreadyExist(alreadyExist.GetKey()))
}
// Extract lock from key error
// 如果被加锁,需要识别出加锁的key,然后尝试解锁或者等待释放。
lock, err1 := extractLockFromKeyErr(keyErr, c.conf.Txn.DefaultLockTTL)
if err1 != nil {
return err1
}
log.Debugf("con:%d 2PC prewrite encounters lock: %v", c.ConnID, lock)
locks = append(locks, lock)
}
start := time.Now()
ok, err := c.store.GetLockResolver().ResolveLocks(bo, locks)
if err != nil {
return err
}
atomic.AddInt64(&c.detail.ResolveLockTime, int64(time.Since(start)))
if !ok {
err = bo.Backoff(retry.BoTxnLock, errors.Errorf("2PC prewrite lockedKeys: %d", len(locks)))
if err != nil {
return err
}
}
}
}commitSingleBatch:
func (c *TxnCommitter) commitSingleBatch(bo *retry.Backoffer, batch batchKeys) error {
// 组装rpc请求并且发送
req := &rpc.Request{
Type: rpc.CmdCommit,
Commit: &pb.CommitRequest{
StartVersion: c.startTS,
Keys: batch.keys,
CommitVersion: c.commitTS,
},
Context: pb.Context{
Priority: c.Priority,
SyncLog: c.SyncLog,
},
}
req.Context.Priority = c.Priority
sender := rpc.NewRegionRequestSender(c.store.GetRegionCache(), c.store.GetRPCClient())
resp, err := sender.SendReq(bo, req, batch.region, c.conf.RPC.ReadTimeoutShort)
// If we fail to receive response for the request that commits primary key, it will be undetermined whether this
// transaction has been successfully committed.
// Under this circumstance, we can not declare the commit is complete (may lead to data lost), nor can we throw
// an error (may lead to the duplicated key error when upper level restarts the transaction). Currently the best
// solution is to populate this error and let upper layer drop the connection to the corresponding mysql client.
isPrimary := bytes.Equal(batch.keys[0], c.primary())
// 这就是Execute函数中判断的UndeterminedErr的值的设置,如果收到的RPC回复错误,则事务状态是未定的,有可能提交了,也可能处于未提交状态。
if isPrimary && sender.RPCError() != nil {
c.setUndeterminedErr(sender.RPCError())
}
if err != nil {
return err
}
regionErr, err := resp.GetRegionError()
if err != nil {
return err
}
if regionErr != nil {
err = bo.Backoff(retry.BoRegionMiss, errors.New(regionErr.String()))
if err != nil {
return err
}
// re-split keys and commit again.
// region错误则进行重试
return c.commitKeys(bo, batch.keys)
}
commitResp := resp.Commit
if commitResp == nil {
return errors.WithStack(rpc.ErrBodyMissing)
}
// Here we can make sure tikv has processed the commit primary key request. So
// we can clean undetermined error.
if isPrimary {
// primary key提交成功则可以认为事务已经提交
c.setUndeterminedErr(nil)
}
if keyErr := commitResp.GetError(); keyErr != nil {
c.mu.RLock()
defer c.mu.RUnlock()
err = errors.Errorf("con:%d 2PC commit failed: %v", c.ConnID, keyErr.String())
if c.mu.committed {
// No secondary key could be rolled back after it's primary key is committed.
// There must be a serious bug somewhere.
log.Errorf("2PC failed commit key after primary key committed: %v, tid: %d", err, c.startTS)
return err
}
// The transaction maybe rolled back by concurrent transactions.
log.Debugf("2PC failed commit primary key: %v, retry later, tid: %d", err, c.startTS)
return errors.WithMessage(err, TxnRetryableMark)
}
c.mu.Lock()
defer c.mu.Unlock()
// Group that contains primary key is always the first.
// We mark transaction's status committed when we receive the first success response.
// commited设为true,由于secondary的提交一定在primary之后,所以这里secondary的提交也可以设置为true
c.mu.committed = true
return nil
}读取
TiKVSnapshot
TiKVSnapshot顾名思义代表一个事务的快照,Transaction的snapshot成员就是该类型。在进行Get操作时,事务首先从本地缓存查询是否存在该key,如果不存在就调用TiKVSnapshot的get方法获取
func (s *TiKVSnapshot) get(bo *retry.Backoffer, k key.Key) ([]byte, error) {
sender := rpc.NewRegionRequestSender(s.store.GetRegionCache(), s.store.GetRPCClient())
req := &rpc.Request{
Type: rpc.CmdGet,
Get: &pb.GetRequest{
Key: k,
Version: s.ts,
},
Context: pb.Context{
Priority: s.Priority,
NotFillCache: s.NotFillCache,
},
}
for {
loc, err := s.store.regionCache.LocateKey(bo, k)
if err != nil {
return nil, err
}
resp, err := sender.SendReq(bo, req, loc.Region, s.conf.RPC.ReadTimeoutShort)
if err != nil {
return nil, err
}
regionErr, err := resp.GetRegionError()
if err != nil {
return nil, err
}
// 如果本地缓存的region的信息错误,则重新获取新的region信息
if regionErr != nil {
err = bo.Backoff(retry.BoRegionMiss, errors.New(regionErr.String()))
if err != nil {
return nil, err
}
continue
}
cmdGetResp := resp.Get
if cmdGetResp == nil {
return nil, errors.WithStack(rpc.ErrBodyMissing)
}
val := cmdGetResp.GetValue()
if keyErr := cmdGetResp.GetError(); keyErr != nil {
lock, err := extractLockFromKeyErr(keyErr, s.conf.Txn.DefaultLockTTL)
if err != nil {
return nil, err
}
// 如果有锁存在则尝试解锁
ok, err := s.store.lockResolver.ResolveLocks(bo, []*Lock{lock})
if err != nil {
return nil, err
}
if !ok {
err = bo.Backoff(retry.BoTxnLockFast, errors.New(keyErr.String()))
if err != nil {
return nil, err
}
}
continue
}
return val, nil
}
}Tikv服务端实现
在论文的原始Percolator事务模型中,存储层不需要对分布式事务有任何感知,只需要支持单行事务,但是出于性能考虑Tikv在存储层做了很多的优化,以减轻开销。
写入
当客户端,经过执行框架的一系列调度,最终会来到写入操作的入口process_write_impl
fn process_write_impl(
cmd: Command,
snapshot: S,
statistics: &mut Statistics,
) -> Result<(Context, ProcessResult, Vec, usize)> {
let (pr, modifies, rows, ctx) = match cmd {
// prewrite入口
Command::Prewrite {
ctx,
mutations,
primary,
start_ts,
options,
..
} => {
// 新建一个本地事务,通过这个事务来进行操作
let mut txn = MvccTxn::new(snapshot, start_ts, !ctx.get_not_fill_cache())?;
let mut locks = vec![];
let rows = mutations.len();
for m in mutations {
// 对每行进行prewrite
match txn.prewrite(m, &primary, &options) {
Ok(_) => {}
// 如果已经有其他事务将该行加锁,应该将加锁的锁信息保存后返回
e @ Err(MvccError::KeyIsLocked { .. }) => {
locks.push(e.map_err(Error::from).map_err(StorageError::from));
}
// 有错误则直接返回错误
Err(e) => return Err(Error::from(e)),
}
}
statistics.add(&txn.take_statistics());
// 返回加锁信息
if locks.is_empty() {
let pr = ProcessResult::MultiRes { results: vec![] };
// 获取所有修改操作
let modifies = txn.into_modifies();
(pr, modifies, rows, ctx)
} else {
// Skip write stage if some keys are locked.
let pr = ProcessResult::MultiRes { results: locks };
(pr, vec![], 0, ctx)
}
}
Command::Commit {
ctx,
keys,
lock_ts,
commit_ts,
..
} => {
if commit_ts <= lock_ts {
return Err(Error::InvalidTxnTso {
start_ts: lock_ts,
commit_ts,
});
}
// commit同样需要新建一个本地事务进行操作
let mut txn = MvccTxn::new(snapshot, lock_ts, !ctx.get_not_fill_cache())?;
let rows = keys.len();
for k in keys {
// 对每一个key调用commit
txn.commit(k, commit_ts)?;
}
statistics.add(&txn.take_statistics());
(ProcessResult::Res, txn.into_modifies(), rows, ctx)
}
Command::Cleanup {
ctx, key, start_ts, ..
} => {
// 新建本地事务清除废弃的锁,比如primary已经提交的secondary锁
let mut txn = MvccTxn::new(snapshot, start_ts, !ctx.get_not_fill_cache())?;
// 使用本地事务的rollback接口
txn.rollback(key)?;
statistics.add(&txn.take_statistics());
(ProcessResult::Res, txn.into_modifies(), 1, ctx)
}
Command::Rollback {
ctx,
keys,
start_ts,
..
} => {
let mut txn = MvccTxn::new(snapshot, start_ts, !ctx.get_not_fill_cache())?;
let rows = keys.len();
// 调用Rollback清除所有相关的锁
for k in keys {
txn.rollback(k)?;
}
statistics.add(&txn.take_statistics());
(ProcessResult::Res, txn.into_modifies(), rows, ctx)
}
Command::ResolveLock {
ctx,
txn_status,
mut scan_key,
key_locks,
} => {
let mut scan_key = scan_key.take();
let mut modifies: Vec = vec![];
let mut write_size = 0;
let rows = key_locks.len();
for (current_key, current_lock) in key_locks {
// 对每一个lock新建事务释放它
let mut txn =
MvccTxn::new(snapshot.clone(), current_lock.ts, !ctx.get_not_fill_cache())?;
let status = txn_status.get(¤t_lock.ts);
let commit_ts = match status {
Some(ts) => *ts,
None => panic!("txn status {} not found.", current_lock.ts),
};
if commit_ts > 0 {
if current_lock.ts >= commit_ts {
return Err(Error::InvalidTxnTso {
start_ts: current_lock.ts,
commit_ts,
});
}
txn.commit(current_key.clone(), commit_ts)?;
} else {
txn.rollback(current_key.clone())?;
}
write_size += txn.write_size();
statistics.add(&txn.take_statistics());
modifies.append(&mut txn.into_modifies());
if write_size >= MAX_TXN_WRITE_SIZE {
scan_key = Some(current_key);
break;
}
}
let pr = if scan_key.is_none() {
ProcessResult::Res
} else {
ProcessResult::NextCommand {
cmd: Command::ResolveLock {
ctx: ctx.clone(),
txn_status,
scan_key: scan_key.take(),
key_locks: vec![],
},
}
};
(pr, modifies, rows, ctx)
}
Command::Pause { ctx, duration, .. } => {
thread::sleep(Duration::from_millis(duration));
(ProcessResult::Res, vec![], 0, ctx)
}
_ => panic!("unsupported write command"),
};
Ok((ctx, pr, modifies, rows))
} 这个入口函数比较长,但很明确的分为了数个分支,其中每个分支对于数据的修改都新建了一个本地事务MvccTxn来进行,例如对于prewrite和commit而言,就是对于每一个修改再调用MvccTxn来执行。下面是进行prewrite的代码
pub fn prewrite(
&mut self,
mutation: Mutation,
primary: &[u8],
options: &Options,
) -> Result<()> {
let lock_type = LockType::from_mutation(&mutation);
let (key, value, should_not_exist) = match mutation {
Mutation::Put((key, value)) => (key, Some(value), false),
Mutation::Delete(key) => (key, None, false),
Mutation::Lock(key) => (key, None, false),
Mutation::Insert((key, value)) => (key, Some(value), true),
};
{
if !options.skip_constraint_check {
if let Some((commit, write)) = self.reader.seek_write(&key, u64::max_value())? {
// Abort on writes after our start timestamp ...
// If exists a commit version whose commit timestamp is larger than or equal to
// current start timestamp, we should abort current prewrite, even if the commit
// type is Rollback.
// 判断冲突,是否有时间戳大于自己开始时间戳的已提交数据
// 如果有则写入失败
if commit >= self.start_ts {
MVCC_CONFLICT_COUNTER.prewrite_write_conflict.inc();
return Err(Error::WriteConflict {
start_ts: self.start_ts,
conflict_start_ts: write.start_ts,
conflict_commit_ts: commit,
key: key.to_raw()?,
primary: primary.to_vec(),
});
}
// 对于插入操作需要先判断key是否已经存在
if should_not_exist {
if write.write_type == WriteType::Put
|| (write.write_type != WriteType::Delete
&& self.key_exist(&key, write.start_ts - 1)?)
{
return Err(Error::AlreadyExist { key: key.to_raw()? });
}
}
}
}
// ... or locks at any timestamp.
if let Some(lock) = self.reader.load_lock(&key)? {
// 已经被别人加锁,需要返回错误,事务提交失败
if lock.ts != self.start_ts {
return Err(Error::KeyIsLocked {
key: key.to_raw()?,
primary: lock.primary,
ts: lock.ts,
ttl: lock.ttl,
});
}
// No need to overwrite the lock and data.
// If we use single delete, we can't put a key multiple times.
MVCC_DUPLICATE_CMD_COUNTER_VEC.prewrite.inc();
return Ok(());
}
}
if value.is_none() || is_short_value(value.as_ref().unwrap()) {
self.lock_key(key, lock_type, primary.to_vec(), options.lock_ttl, value);
} else {
// value is long
let ts = self.start_ts;
// 写入数据和锁
self.put_value(key.clone(), ts, value.unwrap());
self.lock_key(key, lock_type, primary.to_vec(), options.lock_ttl, None);
}
Ok(())
}这里对于时间戳以及加锁的检查可以完整对应到percolator事务原型中prewrite的检查逻辑,只是在原本模型中是由客户端进行检查,而tikv的实现中是client把对应的key打包好发送给所在的tikv,由tikv来具体执行检查。如果在检查中发现冲突则直接返回错误由客户端决定接下来的行动,如果不存在冲突的,则写入data CF和lock CF。在prewrite完成之后,调用本地事务的commit进行提交。
pub fn commit(&mut self, key: Key, commit_ts: u64) -> Result<()> {
let (lock_type, short_value) = match self.reader.load_lock(&key)? {
// 只有这行存在锁,并且这个锁是自己所加的才能进行提交(通过所得时间戳判断)
Some(ref mut lock) if lock.ts == self.start_ts => {
(lock.lock_type, lock.short_value.take())
}
_ => {
// 本事务不再持有锁,需要返回错误
return match self.reader.get_txn_commit_info(&key, self.start_ts)? {
Some((_, WriteType::Rollback)) | None => {
MVCC_CONFLICT_COUNTER.commit_lock_not_found.inc();
// None: related Rollback has been collapsed.
// Rollback: rollback by concurrent transaction.
info!(
"txn conflict (lock not found)";
"key" => %key,
"start_ts" => self.start_ts,
"commit_ts" => commit_ts,
);
Err(Error::TxnLockNotFound {
start_ts: self.start_ts,
commit_ts,
key: key.as_encoded().to_owned(),
})
}
// Committed by concurrent transaction.
Some((_, WriteType::Put))
| Some((_, WriteType::Delete))
| Some((_, WriteType::Lock)) => {
MVCC_DUPLICATE_CMD_COUNTER_VEC.commit.inc();
Ok(())
}
};
}
};
let write = Write::new(
WriteType::from_lock_type(lock_type),
self.start_ts,
short_value,
);
// 在write列写入提交信息并且清除持有的锁
self.put_write(key.clone(), commit_ts, write.to_bytes());
self.unlock_key(key);
Ok(())
}在提交的时候先进行检查,如果不再持有锁(可能因为超时被其他事务清除)则返回错误。如果依然持有,则写入write列并且清除锁。
读取
当客户端进行读取的时候,如percolator的原型所示,通过startTS和其他事务的commitTS的大小对比来判断是否对数据可见,其基本逻辑在MvccReader::get:
pub fn get(&mut self, key: &Key, mut ts: u64) -> Result> {
// Check for locks that signal concurrent writes.
// 在这里可以看到如果是SI隔离级别才需要检查是否被加锁
// 如果是RC隔离级别则直接返回找到的最近的一份已提交的数据
match self.isolation_level {
IsolationLevel::SI => ts = self.check_lock(key, ts)?,
IsolationLevel::RC => {}
}
if let Some(mut write) = self.get_write(key, ts)? {
if write.short_value.is_some() {
if self.key_only {
return Ok(Some(vec![]));
}
return Ok(write.short_value.take());
}
match self.load_data(key, write.start_ts)? {
None => {
return Err(default_not_found_error(key.to_raw()?, write, "get"));
}
Some(v) => return Ok(Some(v)),
}
}
Ok(None)
} 可以看出在SI隔离下会进行lock的检查,如果发现被其他事务锁定,则返回错误由客户端判断是否进行清除或者等待。检查锁的逻辑如下
fn check_lock(&mut self, key: &Key, ts: u64) -> Result {
// 如果存在锁则进行具体的检查逻辑
if let Some(lock) = self.load_lock(key)? {
return self.check_lock_impl(key, ts, lock);
}
Ok(ts)
}
fn check_lock_impl(&self, key: &Key, ts: u64, lock: Lock) -> Result {
// 如果lock是时间戳大于自己的时间戳,则表示加锁的事务开始于当前事务之后,不应该看到这个事务的数据。
if lock.ts > ts || lock.lock_type == LockType::Lock {
// ignore lock when lock.ts > ts or lock's type is Lock
return Ok(ts);
}
if ts == std::u64::MAX && key.to_raw()? == lock.primary {
// when ts==u64::MAX(which means to get latest committed version for
// primary key),and current key is the primary key, returns the latest
// commit version's value
return Ok(lock.ts - 1);
}
// There is a pending lock. Client should wait or clean it.
// 如果有开始于自己之前的事务所加的锁,则需要客户端的事务模块判断是等待锁还是清除锁
Err(Error::KeyIsLocked {
key: key.to_raw()?,
primary: lock.primary,
ts: lock.ts,
ttl: lock.ttl,
})
} 这里的逻辑也可以对应到论文中percolator的读取检查锁的逻辑,如果已经加锁则返回Error::KeyIsLocked错误。
上面的RC级别会有一个问题,由于Percolator是异步释secondary key的锁,因此可能某个事务已经提交了,但它的secondary key的锁还没释放。如果此时有另一个读事务去读取这行数据,那么在RC级别下读事务按理是应该能读取到前一个事务写入的数据的,但是由于secondary key的锁没有释放无法确定上一个事务已经提交,它直接寻找了更早的已经提交的版本而未能读取到。甚至有可能出现在同一个client中,一个事务已经提交但是随后的事务却无法看到它写入的数据的情况。显然,这样违反了线性一致。向pingCAP官方的开发人员咨询后确认了这一问题,官方说他们以后将会改变RC隔离级别的逻辑。