本文主要给初学者关于关系数库的一个浮光掠影式的介绍,如果想深入理解,必须对于下文提到的每个内容单独深入学习!
it-information technology的简称,中文是信息机技术,信息其实就是数据。
要处理数据,则至少涉及到几个方面:
1)表达
2)存取
3)计算
4)安全
当然还是其它方面!
其中第二点就是数据库的核心任务。
一个工业级的产品远远不是这个,还有:
1)网络
2)并发
3)性能
4) 编程
5)安全(包括数据加密+和存取权限等)
6)备份/恢复
7)高可靠
8)兼容
等等,每一个都是可以深入研究的!
随着数据库的发展,数据库越来越自治(优化、高可靠等等),对于普通的dba而言,比以前轻松了不少。
对于大部分的程序员来说,必须和数据库做交互,无论是后端还是前端
本文阐述的是传统关系数据库,重点阐述几点:
1)安装
2)备份恢复
3)编程(sql)
这些都是非常基础的,属于程序员必须掌握的基本技能!
一、安装
程序员的最基本要求,不会装那么就没有什么可说!具体略,要强调的是,应该要回安装各个操作系统,此外会安装集群版本!
安装的基本步骤:
1.确认功能范围
2.确认是免费还是付费
3.下载安装包
4.安装
5配置
6.创建有关管理员账号
7.配置网络和安全
二、备份恢复
冷备份可不要求,专业不备份也不要求,但至少要求会逻辑备份和恢复!
oracle,要懂得expdp/impdp,mysql要懂得mysqldump,sqlserver要懂得bcp等。
三、编程
要熟悉sql语句,则必须了解几个基本的内容:
1.关系数据库概念
2.数据存储原理,不同rdbms的存储方式不一样,所以学新的一种,就必须了解特定一种的存储方式
3.sql语言
4.sql-iso标准和不同厂家的实现
1,2,3是必须掌握的,缺少一个,都难于编写合格的sql语句!
此外,许多概念也需要掌握:范式、索引、分区、视图、元数据、锁、缓存、基本的算法(FIFO,LRU等等)、分布式数据库等等。
本文就Mysql8.x和oracle 12c的进行举例!
3.1 关系数据库概念
重点是“关系”,或者可以理解为表格,可以有多个列和行。
不同于kv模式数据库,也不同于基于hdfs的大数据,更不同于现在所谓的区块链数据库!
关系数据库关键要满足acid:
a:原子性,事务要么完成,要么不完成
c:一致性,关联数据应该符合商业逻辑,事务前后必须保持数据的完整性。理解上可以参考能量守恒定律,个人财务收支!
i:隔离性,一个事务不影响另外一个事务,可以简单理解事务互不影响
d:持久性,就是数据据要落地,并存储在特定介质上,不能总是带电状态下才有!
ad容易理解,但ic不那么容易,需要阅读较多文档才能深刻体会!
注意:关系数据库都遵循acid,但不同产品的实现方式可以不一,表现上也有差异!
3.2数据存储
数据怎么存,是相当复杂的事情,因为这影响了许多方面:
1.性能
2.安全和备份
3.数据表现
例如:oracle12c
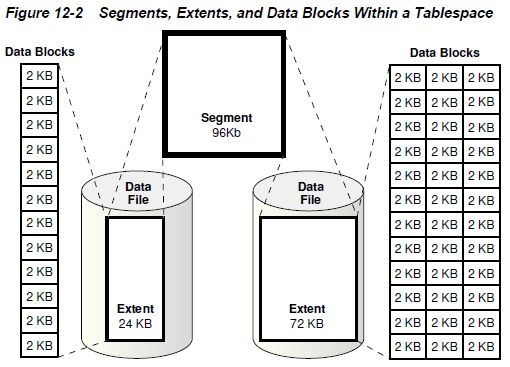
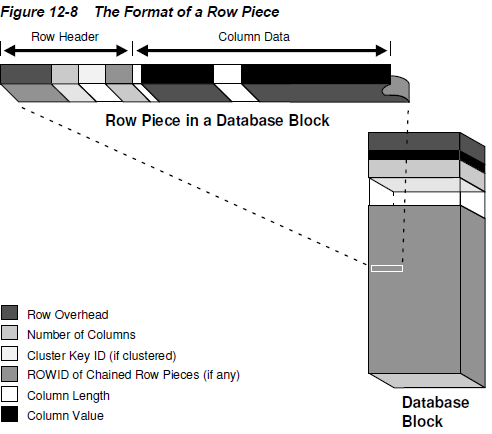
mysql-innodb
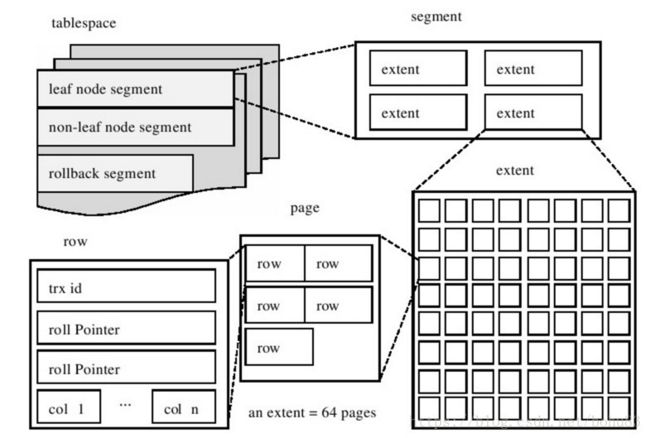
其实存储和性能的关系,可以联想图书馆找书,城市规划等场景,这就是我们常说的“大道相通",或者是理论来自于实践!
书本怎么放才能更快找到,更节省空间,更加安全等等?
城市交通应该怎么规划,才能达到最大的容量,同时又能够有益于大部分人?
数据库物理和逻辑存储的设计对于提高系统性能是相当之关键,是相对比较复杂的。
看看mysql和oracle的create table语句,就可以i体会到存储是重要的,需要学习的内容是很多的。
oracle:https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/CREATE-TABLE.html#GUID-F9CE0CC3-13AE-4744-A43C-EAC7A71AAAB6
mysql: https://dev.mysql.com/doc/refman/8.0/en/create-table.html
把这个命令贴一些出来,估计看了头皮一紧:
mysql:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name (create_definition,...) [table_options] [partition_options] CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name [(create_definition,...)] [table_options] [partition_options] [IGNORE | REPLACE] [AS] query_expression CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name { LIKE old_tbl_name | (LIKE old_tbl_name) } create_definition: col_name column_definition | {INDEX|KEY} [index_name] [index_type] (key_part,...) [index_option] ... | {FULLTEXT|SPATIAL} [INDEX|KEY] [index_name] (key_part,...) [index_option] ... | [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (key_part,...) [index_option] ... | [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY] [index_name] [index_type] (key_part,...) [index_option] ... | [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (col_name,...) reference_definition | check_constraint_definition column_definition: data_type [NOT NULL | NULL] [DEFAULT {literal | (expr)} ] [AUTO_INCREMENT] [UNIQUE [KEY]] [[PRIMARY] KEY] [COMMENT 'string'] [COLLATE collation_name] [COLUMN_FORMAT {FIXED|DYNAMIC|DEFAULT}] [STORAGE {DISK|MEMORY}] [reference_definition] [check_constraint_definition] | data_type [COLLATE collation_name] [GENERATED ALWAYS] AS (expr) [VIRTUAL | STORED] [NOT NULL | NULL] [UNIQUE [KEY]] [[PRIMARY] KEY] [COMMENT 'string'] [reference_definition] [check_constraint_definition] data_type: (see Chapter 11, Data Types) key_part: {col_name [(length)] | (expr)} [ASC | DESC] index_type: USING {BTREE | HASH} index_option: KEY_BLOCK_SIZE [=] value | index_type | WITH PARSER parser_name | COMMENT 'string' | {VISIBLE | INVISIBLE} check_constraint_definition: [CONSTRAINT [symbol]] CHECK (expr) [[NOT] ENFORCED] reference_definition: REFERENCES tbl_name (key_part,...) [MATCH FULL | MATCH PARTIAL | MATCH SIMPLE] [ON DELETE reference_option] [ON UPDATE reference_option] reference_option: RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT table_options: table_option [[,] table_option] ... table_option: AUTO_INCREMENT [=] value | AVG_ROW_LENGTH [=] value | [DEFAULT] CHARACTER SET [=] charset_name | CHECKSUM [=] {0 | 1} | [DEFAULT] COLLATE [=] collation_name | COMMENT [=] 'string' | COMPRESSION [=] {'ZLIB'|'LZ4'|'NONE'} | CONNECTION [=] 'connect_string' | {DATA|INDEX} DIRECTORY [=] 'absolute path to directory' | DELAY_KEY_WRITE [=] {0 | 1} | ENCRYPTION [=] {'Y' | 'N'} | ENGINE [=] engine_name | INSERT_METHOD [=] { NO | FIRST | LAST } | KEY_BLOCK_SIZE [=] value | MAX_ROWS [=] value | MIN_ROWS [=] value | PACK_KEYS [=] {0 | 1 | DEFAULT} | PASSWORD [=] 'string' | ROW_FORMAT [=] {DEFAULT|DYNAMIC|FIXED|COMPRESSED|REDUNDANT|COMPACT} | STATS_AUTO_RECALC [=] {DEFAULT|0|1} | STATS_PERSISTENT [=] {DEFAULT|0|1} | STATS_SAMPLE_PAGES [=] value | TABLESPACE tablespace_name [STORAGE {DISK|MEMORY}] | UNION [=] (tbl_name[,tbl_name]...) partition_options: PARTITION BY { [LINEAR] HASH(expr) | [LINEAR] KEY [ALGORITHM={1|2}] (column_list) | RANGE{(expr) | COLUMNS(column_list)} | LIST{(expr) | COLUMNS(column_list)} } [PARTITIONS num] [SUBPARTITION BY { [LINEAR] HASH(expr) | [LINEAR] KEY [ALGORITHM={1|2}] (column_list) } [SUBPARTITIONS num] ] [(partition_definition [, partition_definition] ...)] partition_definition: PARTITION partition_name [VALUES {LESS THAN {(expr | value_list) | MAXVALUE} | IN (value_list)}] [[STORAGE] ENGINE [=] engine_name] [COMMENT [=] 'string' ] [DATA DIRECTORY [=] 'data_dir'] [INDEX DIRECTORY [=] 'index_dir'] [MAX_ROWS [=] max_number_of_rows] [MIN_ROWS [=] min_number_of_rows] [TABLESPACE [=] tablespace_name] [(subpartition_definition [, subpartition_definition] ...)] subpartition_definition: SUBPARTITION logical_name [[STORAGE] ENGINE [=] engine_name] [COMMENT [=] 'string' ] [DATA DIRECTORY [=] 'data_dir'] [INDEX DIRECTORY [=] 'index_dir'] [MAX_ROWS [=] max_number_of_rows] [MIN_ROWS [=] min_number_of_rows] [TABLESPACE [=] tablespace_name] query_expression: SELECT ... (Some valid select or union statement)
顺便说下:如果英文不过关,那么学好计算机还是有一定难度的!毕竟许多资料是英文的!
3.3 sql语句
标准sql语句,尤其是ddl,dml语句谈不上复杂,准确说,应该是相对很简单的。
如果有什么稍微难一些的就是 集合运算,譬如 inner join ,left join,full join,但也很容易理解!
总结
要写好sql语句,需要长时间训练,从数据库基础开始,到熟练写出每个sql语句!
学习之后,写不出每个sql语句,属于资质问题;写不出好的sql语句,可能是学习不够,也可能是资质问题!