前言
这个假期我开始系统地学习python,列一下我所知的python学习网站:
- 廖雪峰的官方网站
- 菜鸟教程
- 慕课网
还有一些欢迎补充。其中菜鸟教程的和廖雪峰的内容差不多,不过廖雪峰的内容更全面一些,由浅入深,是我学习python基础知识的主要渠道,在此非常感谢廖老师!慕课网的内容则是以视频的为主,适合不喜欢看文字或者看文字看不懂的同学。
简单爬虫架构
具体实现:简单爬虫架构的实现
上个假期我用python写了个简单的爬虫Python爬虫实战:登录教务系统查成绩
而在前两天我又在慕课网看了一个介绍简单爬虫架构的视频,相比我原来写的简单爬虫,这个显然更易于维护,而且更接近真实项目,很好地运用了面向对象的编程思维。
简单介绍一下爬虫架构
爬虫架构

首先一个爬虫由一个爬虫调度端、一个URL管理器、一个网页下载器、一个网页解析器组成,并最终得到价值数据。
爬虫工作过程
爬虫从爬虫调度端开始。
爬虫调度端负责协调URL管理器、网页下载器与网页解析器。
首先它从URL管理器中询问是否有待爬URL,若有则将待爬URL传给网页下载器,网页下载器将下载的html文件传给网页解析器,网页解析器将按需求解析出价值数据以及网页中新的URL,输出价值数据并将新的URL传给URL管理器。这就是一个完整的爬虫过程。
URL管理器负责管理URL,将已爬的和未爬的URL分别储存起来,能够输出未爬的URL。
网页下载器负责下载URL对应的html页面。
网页解析器根据需求解析出想要的数据。(不同需求的爬虫需设计不同的解析器,而URL管理器和网页下载器则可以基本不用更改)
具体的实现在这:简单爬虫架构的实现
面向对象思维
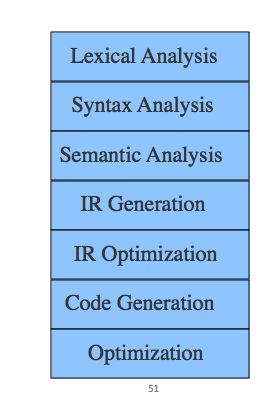
写到这里,我就突然理解了我们学校让我们学习编译原理的目的了。此前我一直认为学校的目的只是让我们了解一下编译技术,毕竟每周一节课,总共也才2.5个学分,要想深入学习,能够写出编译器显然不现实。现在想想其实这门课更多的是在向我们展示一个成熟完善的大项目,让我们能够对大规模的工程有更好的认识,以及能够深入理解这种面向对象的编程方式,体会到面向对象带来的便利。
在我接触到这个简单的爬虫架构以后,我发现这其实和编译器的设计原理是一样的。
编译器其实是由词法分析器、语法分析器到代码生成器构成的,当然中间还经过了语义分析、中间代码生成等过程。其中每部分负责各自的工作,因此我们可以分开设计,将一个大项目分散成小项目,将复杂的任务简单化。而这样的思维,便是面向对象的编程思维了。