原文链接:http://www.cnblogs.com/sandy-t/p/6930608.html
循环神经网络RNN相比传统的神经网络在处理序列化数据时更有优势,因为RNN能够将加入上(下)文信息进行考虑。一个简单的RNN如下图所示:
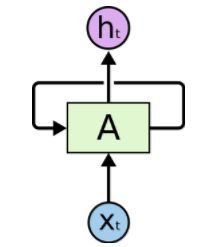
将这个循环展开得到下图:

上一时刻的状态会传递到下一时刻。这种链式特性决定了RNN能够很好的处理序列化的数据,RNN 在语音识别,语言建模,翻译,图片描述等问题上已经取得了很到的结果。
根据输入、输出的不同和是否有延迟等一些情况,RNN在应用中有如下一些形态:

RNN存在的问题
RNN能够把状态传递到下一时刻,好像对一部分信息有记忆能力一样,如下图:
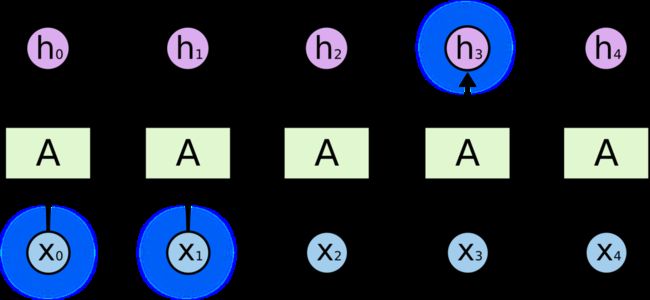
h3h3的值可能会由x1x1,x2x2的值来决定。
但是,对于一些复杂场景

由于距离太远,中间间隔了太多状态,x1x1,x2x2对ht+1ht+1的值几乎起不到任何作用。(梯度消失和梯度爆炸)
LSTM(Long Short Term Memory)
由于RNN不能很好地处理这种问题,于是出现了LSTM(Long Short Term Memory)一种加强版的RNN(LSTM可以改善梯度消失问题)。简单来说就是原始RNN没有长期的记忆能力,于是就给RNN加上了一些记忆控制器,实现对某些信息能够较长期的记忆,而对某些信息只有短期记忆能力。
如上图所示,LSTM中存在Forget Gate,Input Gate,Output Gate来控制信息的流动程度。

RNN:

LSTN:

加号圆圈表示线性相加,乘号圆圈表示用gate来过滤信息。
Understanding LSTM中对LSTM有非常详细的介绍。(对应的中文翻译)
LSTM MNIST手写数字辨识
实际上,图片文字识别这类任务用CNN来做效果更好,但是这里想要强行用LSTM来做一波。
MNIST_data中每一个image的大小是28*28,以行顺序作为序列输入,即第一行的28个像素作为$x_{0}
,第二行为,第二行为x_1,...,第28行的28个像素作为,...,第28行的28个像素作为x_28$输入,一个网络结构总共的输入是28个维度为28的向量,输出值是10维的向量,表示的是0-9个数字的概率值。这是一个many to one的RNN结构。
下面直接上代码:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# 参数设置
BATCH_SIZE = 100 # BATCH的大小,相当于一次处理50个image
TIME_STEP = 28 # 一个LSTM中,输入序列的长度,image有28行
INPUT_SIZE = 28 # x_i 的向量长度,image有28列
LR = 0.01 # 学习率
NUM_UNITS = 100 # 多少个LTSM单元
ITERATIONS=8000 # 迭代次数
N_CLASSES=10 # 输出大小,0-9十个数字的概率
# 定义 placeholders 以便接收x,y
train_x = tf.placeholder(tf.float32, [None, TIME_STEP * INPUT_SIZE]) # 维度是[BATCH_SIZE,TIME_STEP * INPUT_SIZE]
image = tf.reshape(train_x, [-1, TIME_STEP, INPUT_SIZE]) # 输入的是二维数据,将其还原为三维,维度是[BATCH_SIZE, TIME_STEP, INPUT_SIZE]
train_y = tf.placeholder(tf.int32, [None, N_CLASSES])
# 定义RNN(LSTM)结构
rnn_cell = tf.contrib.rnn.BasicLSTMCell(num_units=NUM_UNITS)
outputs,final_state = tf.nn.dynamic_rnn(
cell=rnn_cell, # 选择传入的cell
inputs=image, # 传入的数据
initial_state=None, # 初始状态
dtype=tf.float32, # 数据类型
time_major=False, # False: (batch, time step, input); True: (time step, batch, input),这里根据image结构选择False
)
output = tf.layers.dense(inputs=outputs[:, -1, :], units=N_CLASSES)
这里outputs,final_state = tf.nn.dynamic_rnn(...).
final_state包含两个量,第一个为c保存了每个LSTM任务最后一个cell中每个神经元的状态值,第二个量h保存了每个LSTM任务最后一个cell中每个神经元的输出值,所以c和h的维度都是[BATCH_SIZE,NUM_UNITS]。
outputs的维度是[BATCH_SIZE,TIME_STEP,NUM_UNITS],保存了每个step中cell的输出值h。
由于这里是一个many to one的任务,只需要最后一个step的输出outputs[:, -1, :],output = tf.layers.dense(inputs=outputs[:, -1, :], units=N_CLASSES) 通过一个全连接层将输出限制为N_CLASSES。
loss = tf.losses.softmax_cross_entropy(onehot_labels=train_y, logits=output) # 计算loss
train_op = tf.train.AdamOptimizer(LR).minimize(loss) #选择优化方法
correct_prediction = tf.equal(tf.argmax(train_y, axis=1),tf.argmax(output, axis=1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,'float')) #计算正确率
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 初始化计算图中的变量
for step in range(ITERATIONS): # 开始训练
x, y = mnist.train.next_batch(BATCH_SIZE)
test_x, test_y = mnist.test.next_batch(5000)
_, loss_ = sess.run([train_op, loss], {train_x: x, train_y: y})
if step % 500 == 0: # test(validation)
accuracy_ = sess.run(accuracy, {train_x: test_x, train_y: test_y})
print('train loss: %.4f' % loss_, '| test accuracy: %.2f' % accuracy_)
训练过程输出:
train loss: 2.2990 | test accuracy: 0.13
train loss: 0.1347 | test accuracy: 0.96
train loss: 0.0620 | test accuracy: 0.97
train loss: 0.0788 | test accuracy: 0.98
train loss: 0.0160 | test accuracy: 0.98
train loss: 0.0084 | test accuracy: 0.99
train loss: 0.0436 | test accuracy: 0.99
train loss: 0.0104 | test accuracy: 0.98
train loss: 0.0736 | test accuracy: 0.99
train loss: 0.0154 | test accuracy: 0.98
train loss: 0.0407 | test accuracy: 0.98
train loss: 0.0109 | test accuracy: 0.98
train loss: 0.0722 | test accuracy: 0.98
train loss: 0.1133 | test accuracy: 0.98
train loss: 0.0072 | test accuracy: 0.99
train loss: 0.0352 | test accuracy: 0.98
可以看到,虽然RNN是擅长处理序列类的任务,在MNIST手写数字图片辨识这个任务上,RNN同样可以取得很高的正确率。
参考:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://yjango.gitbooks.io/superorganism/content/lstmgru.html
参考代码
https://yjango.gitbooks.io/superorganism/content/lstmgru.html
参考代码