1,json中四个重要的方法
- Json结构清晰,可读性高,复杂度低,非常容易匹配。
1. json.loads()
把Json格式字符串解码转换成Python对象
从json到python的类型转化对照如下:
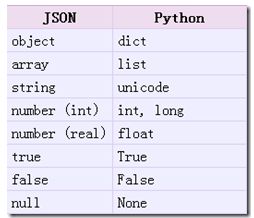
这里写图片描述
2. json.dumps()
实现python类型转化为json字符串,返回一个str对象 。
从python原始类型向json类型的转化对照如下:
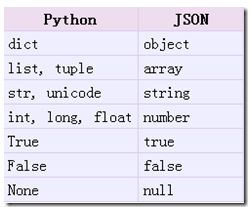
这里写图片描述
3. json.dump()
将Python内置类型序列化为json对象后写入文件
4. json.load()
读取文件中json形式的字符串元素 转化成python类型
5,注意事项:
json.loads() 是把 Json格式字符串解码转换成Python对象,如果在json.loads的时候出错,要注意被解码的Json字符的编码,如果传入的字符串的编码不是UTF-8的话,需要指定字符编码的参数encoding
如:
dataDict = json.loads(jsonStrGBK);
jsonStrGBK是JSON字符串,假设其编码本身是非UTF-8的话而是GBK 的,那么上述代码会导致出错,改为对应的:
dataDict = json.loads(jsonStrGBK, encoding="GBK");
- 任何平台的任何编码 都能和 Unicode 互相转换
- decode的作用是将其他编码的字符串转换成 Unicode 编码
- encode的作用是将 Unicode 编码转换成其他编码的字符串
- 一句话:UTF-8是对Unicode字符集进行编码的一种编码方式
2,JsonPath
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具。
- JsonPath与XPath语法对比:

这里写图片描述
3,爬取某招聘网站职位信息案例
import requests
import json
import jsonpath
class LagouSpider:
def __init__(self):
self.headers = {
# 模拟真实的浏览器,把请求头全部都加上
# "Accept" : "application/json, text/javascript, */*; q=0.01",
# "Accept-Encoding" : "gzip, deflate, br",
# "Accept-Language" : "zh-CN,zh;q=0.8",
# "Connection" : "keep-alive",
# "Content-Length" : "43",
# "Content-Type" : "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "user_trace_token=20170626172300-2aa5eb9c81db4093b6491f60c504f9a1; LGUID=20170626172300-0c74fdbf-5a51-11e7-89d3-525400f775ce; index_location_city=%E5%8C%97%E4%BA%AC; JSESSIONID=ABAAABAACDBABJB0A65566C403D46573532367CBEEF2AB5; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; _gid=GA1.2.327690172.1500516674; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1498468981,1500406505,1500516674; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1500518676; _ga=GA1.2.764300251.1498468981; LGSID=20170720104259-2462b23d-6cf5-11e7-ae7e-525400f775ce; LGRID=20170720104435-5db33ef4-6cf5-11e7-ae8d-525400f775ce; TG-TRACK-CODE=search_code; SEARCH_ID=36027e19a74f4ceaab54f35baae12a30",
"Host": "www.lagou.com",
"Origin": "https://www.lagou.com",
# 反爬第二步,标记浏览器的来源,从查看网页源码可知
"Referer": "https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput=",
# 反爬第一步
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"X-Anit-Forge-Code": "0",
"X-Anit-Forge-Token": "None",
"X-Requested-With": "XMLHttpRequest"
}
# url地址固定部分
self.baseURL = "https://www.lagou.com/jobs/positionAjax.json?"
self.positionName = input("请输入需要查询的职位名:")
self.cityName = input("请输入需要查询的城市名:")
self.endPage = int(input("请输入需要爬取的页数:"))
# post的页码数据
self.page = 1
# 添加代理
# self.proxy = {"http" : "123.23.232.11:8080"}
def startWrok(self):
# 存储loadPage()返回的所有职位信息
item_list = []
while self.page <= self.endPage:
# 获取每一页的职位信息列表
position_list = self.loadPage()
# 合并所有页的职位信息
item_list += position_list
# 每获取一页,页码自增1
self.page += 1
# 禁用ascii处理中文,返回json格式的字符串,返回Unicode
content = json.dumps(item_list, ensure_ascii=False)
# 将数据写入到磁盘文件里
with open("lagou_info.json", "w") as f:
f.write(content)
def loadPage(self):
# url的查询字符串,post请求采参数
params = {"city": self.cityName, "needAddtionalResult": "false"}
# post的表单数据
formdata = {"first": "true", "pn": self.page, "kd": self.positionName}
try:
print("[LOG]: 正在抓取 %d 页..." % self.page)
response_result = requests.post(self.baseURL, params=params, data=formdata, headers=self.headers)
# 代理使用: proxies = self.proxy)
except Exception as e:
print("[LOG]: 抓取失败...")
print(e)
# time.sleep(2)
# html = response.content
# jsonobj = json.loads(html)
# 按json格式获取requests响应,Python数据类型
jsonobj = response_result.json()
"""
# urllib2 的用法
params = urllib.urlencode(params)
data = urllib.urlencode(formdata)
url = self.baseURL + params
request = urllib2.Request(url, data = data, headers = self.headers)
response = urllib2.urlopen(request)
jsonobj = json.loads(response.read())
"""
try:
# 通过jsonpath获取json里的result部分
result_list = jsonpath.jsonpath(jsonobj, "$..result")[0]
# 存储当前页的职位信息
position_list = []
# 处理每一条职位信息
for result in result_list:
# 获取每条职位信息的部分数据
item = {}
item['城市'] = result['city'] if result['city'] else "NULL"
item['公司名'] = result['companyFullName'] if result['companyFullName'] else "NULL"
item['发布时间'] = result['createTime'] if result['createTime'] else "NULL"
item['区域'] = result['district'] if result['district'] else "NULL"
item['职位'] = result['positionName'] if result['positionName'] else "NULL"
item['薪水'] = result['salary'] if result['salary'] else "NULL"
position_list.append(item)
return position_list
except Exception as e:
print("[ERR]: 获取数据失败...")
print(e)
return []
if __name__ == "__main__":
spider = LagouSpider()
spider.startWrok()
4,把json格式的文件转为csv格式的文件
# 处理json文本
import json
# 处理csv
import csv
# 创建csv文件对象
csvFile = open("lagou_info.csv", "w")
# 创建csv文件的读写对象,可以用来对csv进行读写操作
csv_writer = csv.writer(csvFile)
# 创建json文件对象
jsonFile = open("lagou_info.json", "r")
# 读取本地磁盘json文件,返回原本的数据类型:列表
content_list = json.load(jsonFile)
# 获取表头部分
sheet = content_list[0].keys()
# 将所有的数据放到一个大列表里
data = [content.values() for content in content_list]
# writerow 表示写入一行数据,参数是一个列表
csv_writer.writerow(sheet)
# writerows 表示写入多行数据,参数是一个列表(包含所有数据)
csv_writer.writerows(data)
csvFile.close()
jsonFile.close()