Sqoop是一种用于在Hadoop和关系数据库或大型机之间传输数据的工具。您可以使用Sqoop从关系数据库管理系统(RDBMS)(如MySQL、Oracle或大型机)导入数据到Hadoop分布式文件系统(HDFS),在Hadoop MapReduce中转换数据,然后将数据导出回RDBMS。
一、安装
测试环境:centos7、JDK8、hadoop2.7.2
step1: 下载安装
到官网选择适合镜像地址下载 sqoop download
说明:sqoop对应hadoop2.x的版本不要求小本版号一致,无须纠结hadoop2.7.2和sqoop-1.4.7.bin__hadoop-2.6.0不兼容
wget http://mirror.bit.edu.cn/apache/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
tar xvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt
ln -s /opt/sqoop-1.4.7.bin__hadoop-2.6.0/ /opt/apps/sqoop
step2: 修改配置
sqoop启动环境配置文件
cp /opt/apps/sqoop/conf/sqoop-env-template.sh /opt/apps/sqoop/conf/sqoop-env.sh
在bin/configure-sqoop去掉未安装的服务如(HCatalog、Accumulo)。否则使用时会报相应未安装服务的错误信息。
vi /opt/apps/sqoop/bin/configure-sqoop
134 ## Moved to be a runtime check in sqoop.
135 #if [ ! -d "${HCAT_HOME}" ]; then
136 # echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail."
137 # echo 'Please set $HCAT_HOME to the root of your HCatalog installation.'
138 #fi
139 #
140 #if [ ! -d "${ACCUMULO_HOME}" ]; then
141 # echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports will fail."
142 # echo 'Please set $ACCUMULO_HOME to the root of your Accumulo installation.'
143 #fi
原文件如下:
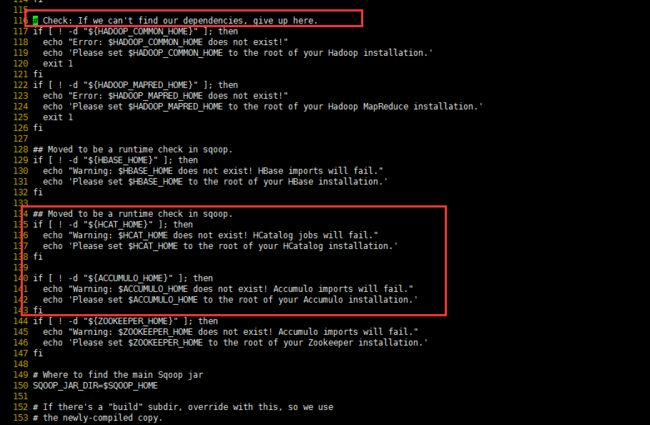 image.png
image.png
setp3: 添加驱动
以mysql驱动为例,驱动下载地址
将驱动包添加到lib/目录下
wget -P /opt/apps/sqoop/lib/ http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.40/mysql-connector-java-5.1.40.jar
step4: 配置环境变量(可选)
若不配置环境变量,需到sqoop安装目录的bin目录下执行sqoop命令
vi /etc/profile
export SQOOP_HOME=/opt/apps/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
source /etc/profile
二、使用介绍
使用help命令查看sqoop命令帮助
# ./bin/sqoop help
18/12/02 09:33:12 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
由上可知命令格式:sqoop COMMAND [ARGS]
2.1 参数介绍
官方文档地址
2.1.1 sqoop import
- 连接数据库参数
| 参数 | 描述 |
|---|---|
| --connect |
指定JDBC连接字符串 |
| --connection-manager |
指定要使用的连接管理器类 |
| --driver |
手动指定要使用的JDBC驱动程序类 |
| --hadoop-mapred-home |
覆盖$HADOOP_MAPRED_HOME变量 |
| --help | 打印使用说明 |
| --password-file | 为包含身份验证密码的文件设置路径 |
| -P | 从控制台读取密码 |
| --password |
设置身份验证密码 |
| --username |
设置身份验证用户名 |
| --verbose | 工作时打印更多信息 |
| --connection-param-file |
提供连接参数的可选属性文件 |
| --relaxed-isolation | 设置连接事务隔离,以便为映射器读取未提交的数据。 |
a、默认情况下,Sqoop使用映射器中的读提交事务隔离来导入数据。这在所有ETL工作流中可能不是理想的,可能需要减少隔离保证。
--relaxed-isolation选项可用于指示Sqoop使用read uncommitted隔离级别。所有数据库(例如Oracle)不支持读取未提交(read uncommitted)的隔离级别,因此指定选项--relaxed-isolation可能不支持所有数据库。
eg:
sqoop import --connect jdbc:mysql://database.example.com/employees --username aaron --password 12345
#Sqoop将读取密码文件的全部内容,并将其用作密码。这将包括任何尾随的空白字符,例如大多数文本编辑器默认添加的新行字符。您需要确保您的密码文件只包含属于您的密码的字符。
#在命令行上,您可以使用带有开关-n的命令echo来存储密码,而不需要任何尾随的空格字符。例如,要存储密码secret,可以调用echo -n“secret”> .file。
$ sqoop import --connect jdbc:mysql://database.example.com/employees --username venkatesh --password-file ${user.home}/.password
- 更详细的验证参数
| 参数 | 描述 |
|---|---|
| --validate | 启用数据复制的验证,只支持单表复制。 |
| --validator |
指定要使用的validator类。 |
| --validation-threshold |
指定要使用的验证阈值类。 |
| --validation-failurehandler |
指定要使用的验证失败处理程序类。 |
- 导入控制参数
| 参数 | 描述 |
|---|---|
| --append | 将数据附加到HDFS中的现有数据集 |
| --as-avrodatafile | 导入数据到Avro数据文件 |
| --as-sequencefile | 将数据导入sequencefile |
| --as-textfile | 将数据导入为纯文本(默认) |
| --as-parquetfile | 将数据导入拼花地板文件 |
| --boundary-query |
用于创建分割的边界查询 |
| --columns |
要从表导入的列 |
| --delete-target-dir | 如果导入目标目录存在则删除 |
| --direct | 如果数据库存在,则使用direct(直)连接器 |
| --fetch-size |
一次从数据库读取的条目数。 |
| --inline-lob-limit |
设置内联LOB的最大大小 |
| -m,--num-mappers |
使用n个映射任务并行导入 |
| -e,--query |
导入语句的结果。 |
| --split-by |
用于分隔工作单元的表的列。不能与--autoreset-to-one-mapper选项一起使用。 |
| --split-limit |
每个分割大小的上限。这只适用于整型和日期列。对于日期或时间戳字段,它以秒计算。 |
| --autoreset-to-one-mapper | 如果一个表没有主键,也没有提供按列拆分,导入应该使用一个映射器。不能与--split-by |
| --table |
要读的表 |
| --target-dir |
HDFS目的地dir |
| --temporary-rootdir |
用于导入期间创建的临时文件的HDFS目录(覆盖默认的“_sqoop”) |
| --warehouse-dir |
表目标的HDFS父节点 |
| --where |
在导入过程中使用WHERE子句 |
| -z,--compress | 启用压缩 |
| --compression-codec |
使用Hadoop编解码器(默认gzip) |
| --null-string |
为字符串列的空值编写的字符串 |
| --null-non-string |
为非字符串列的null值编写的字符串 |
a、 --null-string和--null-non-string 参数是可选的。如果没有指定,那么将使用字符串“null”。
b、 当通过Oozie启动Sqoop命令时,使用选项--skip-dist-cache将跳过Sqoop将依赖项复制到作业缓存并保存大量I/O的步骤。(控制分布式缓存)
c、默认情况下,导入过程将使用JDBC,一些数据库可以使用特定于数据库的数据移动工具以更高性能的方式执行导入。例如,MySQL提供了mysqldump工具,它可以非常快速地将数据从MySQL导出到其他系统。通过提--direct参数,您指定Sqoop应该尝试直接导入通道。这个通道可能比使用JDBC的性能更高。
d、默认情况下,Sqoop会将一个名为foo的表导入到HDFS中主目录中的一个名为foo的目录中。例如,如果您的用户名是someuser,那么导入工具将写入/user/someuser/foo/(files)。您可以使用--warehouse-dir参数调整导入的父目录。或者显式地指定目标目录--target-dir。--target-dir和--warehouse-dir互不兼容。
e、默认情况下,导入将转到新的目标位置。如果目标目录已经存在于HDFS中,Sqoop将拒绝导入和覆盖该目录的内容。如果使用——append参数,Sqoop将把数据导入临时目录,然后将文件重命名为普通目标目录,其方式不会与该目录中的现有文件名冲突。
f、当sqoop从企业存储导入数据时,表名和列名可能具有不是有效Java标识符或Avro/Parquet标识符的字符。为了解决这个问题,sqoop将这些字符转换为作为模式创建的一部分。任何以(下划线)字符开头的列名都将被转换为两个下划线字符。例如,_AVRO将被转换为__AVRO。在HCatalog导入的情况下,当映射到HCatalog列时,列名将转换为小写。这种情况在未来可能会改变。
g、默认情况下,数据没有压缩。您可以使用-z或-compress参数的deflate (gzip)算法压缩数据,或者使用-compression-codec参数指定任何Hadoop压缩编解码器。这适用于SequenceFile、text和Avro文件。
h、分隔文本是默认的导入格式。您还可以使用--as-textfile参数显式地指定它。该参数将把每个记录的基于字符串的表示形式写入输出文件,在各个列和行之间使用分隔符。这些分隔符可以是逗号、制表符或其他字符。(可以选择分隔符
eg:
选择列数据导入
sqoop import ... --columns "name,employee_id,jobtitle" --where "id > 400" ...
自由格式的查询导入
sqoop import --query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' --split-by a.id --target-dir /user/foo/joinresults
sqoop import --query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' -m 1 --target-dir /user/foo/joinresults
在使用direct模式时,可以指定应该传递给底层工具的其他参数。如果参数--在命令行上给出,那么后续参数将直接发送到底层工具。例如,下面调整mysqldump使用的字符集:
sqoop import --connect jdbc:mysql://server.foo.com/db --table bar --direct -- --default-character-set=latin1
注意:
$CONDITIONS是必须条件存在于--query
a、如果使用双引号(")包装查询,则必须使用\$CONDITIONS而不是仅使用$CONDITIONS来禁止shell将其视为shell变量(即使用斜杆转义)。例如,双引号查询可能类似于:“SELECT * FROM x WHERE a='foo' AND \$CONDITIONS”。
b、在当前版本的Sqoop中使用自由形式查询的功能仅限于简单查询,其中没有不明确的投影,where子句中没有OR条件。使用复杂的查询(例如具有子查询或连接的查询)会导致不明确的投影,从而导致意外的结果。
- 控制类型映射参数
| 参数 | 描述 |
|---|---|
| --map-column-java |
为已配置列覆盖从SQL到Java类型的映射。 |
| --map-column-hive |
为配置的列覆盖从SQL到Hive类型的映射。 |
eg:
sqoop import ... --map-column-java id=String,value=Integer
- 增量导入参数
| 参数 | 描述 |
|---|---|
| --check-column (col) | 指定在决定导入哪些行时要检查的列。(该列不应该是CHAR/NCHAR/VARCHAR/VARNCHAR/ LONGVARCHAR/LONGNVARCHAR类型) |
| --incremental (mode) | 指定Sqoop如何确定哪些行是新的。模式的合法值包括append和lastmodified。 |
| --last-value (value) | 指定上一个导入的检查列的最大值。 |
- 大对象
| 参数 | 描述 |
|---|---|
| 输出行格式化参数: | |
| --enclosed-by |
设置所需的字段包围字符 |
| --escaped-by |
设置转义字符 |
| --fields-terminated-by |
设置字段分隔符字符\b (backspace) \n (newline) \r (carriage return) \t (tab) " (double-quote) \' (single-quote) \ (backslash) \0 (NUL) |
| --lines-terminated-by |
设置行尾字符 |
| --mysql-delimiters | 使用MySQL的默认分隔符set: fields:, lines: \n escape -by: \ option -enclosed-by: ' |
| --optionally-enclosed-by |
设置一个字段包围字符 |
| 输入解析参数: | |
| --input-enclosed-by |
设置所需的字段外壳 |
| --input-escaped-by |
设置输入转义字符 |
| --input-fields-terminated-by |
设置输入字段分隔符 |
| --input-lines-terminated-by |
设置输入行结束符 |
| --input-optionally-enclosed-by |
设置一个字段包围字符 |
a、Sqoop以特定的方式处理大型对象(BLOB和CLOB列)。如果这个数据确实很大,那么这些列不应该像大多数列那样在内存中完全物化以便操作。相反,它们的数据以流方式处理。大型对象可以与其他数据一起内联存储,在这种情况下,它们在每次访问时都在内存中完全物化,或者它们可以存储在连接到主数据存储的辅助存储文件中。默认情况下,小于16mb的大型对象与其他数据一起存储。在较大的尺寸下,它们存储在导入目标目录的_lobs子目录中的文件中。这些文件存储在一个单独的格式优化大型记录存储,可容纳2 ^ 63字节的记录。lob溢出到单独文件中的大小由
--inline-lob-limit参数控制,该参数接受一个参数,该参数指定要保持内联的最大lob大小(以字节为单位)。如果将内联LOB限制设置为0,则所有大型对象都将放置在外部存储中。
b、即使Hive支持转义字符,它也不能处理换行字符的转义。此外,它不支持在封闭的字符串中包含字段分隔符的封闭字符的概念。因此,建议您在使用Hive时选择无歧义字段和记录终止分隔符,而不需要转义和包围字符;这是由于Hive的输入解析能力的限制
c、当Sqoop将数据导入到HDFS时,它会生成一个Java类,该类可以重新解释在执行分隔格式导入时创建的文本文件。分隔符是用参数选择的,例如--fields-terminated-by;它控制如何将数据写到磁盘,以及生成的parse()方法如何重新解释这些数据。parse()方法使用的分隔符可以独立于输出参数进行选择,方法是使用--input-field -terminated-by,等等。例如,这对于生成可以解析用一组分隔符创建的记录并发出t的类非常有用
eg:
sqoop import --optionally-enclosed-by '\"' (the rest as above)...
- 将数据导入Hive参数
| 参数 | 描述 |
|---|---|
| --hive-home |
重写覆盖$HIVE_HOME变量 |
| --hive-import | 将表导入Hive(如果没有设置任何分隔符,则使用Hive的默认分隔符)。 |
| --hive-overwrite | 覆盖Hive表中的现有数据。 |
| --create-hive-table | 如果设置,那么如果目标hive表存在,作业将失败。默认情况下,此属性为false。 |
| --hive-table |
设置导入到Hive时要使用的表名。 |
| --hive-drop-import-delims | 将\n、\r和\01从字符串字段导入到Hive时去除。 |
| --hive-delims-replacement | 将\n、\r和\01从字符串字段导入到Hive时用用户定义的字符串替换。 |
| --hive-partition-key | 要分区的hive字段的名称被切分 |
| --hive-partition-value |
字符串值,作为在此作业中导入到hive的分区键。 |
| --map-column-hive | 为配置的列覆盖从SQL类型到Hive类型的默认映射。如果在这个参数中指定逗号,则使用URL编码的键和值,例如,使用DECIMAL(1%2C%201)而不是DECIMAL(1,1)。 |
Sqoop导入工具的主要功能是将数据上传到HDFS中的文件中。如果您有一个与HDFS集群关联的Hive元数据存储,Sqoop还可以通过生成和执行CREATE TABLE语句将数据导入到Hive中,以定义数据在Hive中的布局。将数据导入Hive非常简单,只需--hive-import选项添加到Sqoop命令行即可。
如果Hive表已经存在,您可以指定--hive-overwrite选项,以指示必须替换Hive中现有的表。将数据导入HDFS或省略此步骤后,Sqoop将生成一个Hive脚本,其中包含一个使用Hive类型定义列的CREATE TABLE操作,以及一个LOAD DATA INPATH语句,用于将数据文件移动到Hive 的 warehouse目录中。脚本将通过调用Sqoop运行的机器上安装的hive副本来执行。如果您有多个Hive安装,或者Hive不在$PATH中,请使用--hive-home选项来标识Hive安装目录。Sqoop将从这里使用$HIVE_HOME/bin/hive。
注意:
a、导入hive不兼容--as-avrodatafile 和 --as-sequencefile参数。
即使Hive支持转义字符,它也不能处理换行字符的转义。此外,它不支持在封闭的字符串中包含字段分隔符的封闭字符的概念。因此,建议您在使用Hive时选择无歧义字段和记录终止分隔符,而不需要转义和包围字符;这是由于Hive的输入解析能力的限制。如果在将数据导入Hive时确实使用了-escape -by、- encloed -by或-option - encloed -by, Sqoop将打印一条警告消息。
如果数据库的行包含包含Hive默认行分隔符(\n和\r字符)或列分隔符(\01字符)的字符串字段,那么Hive在使用sqoop导入的数据时会遇到问题。可以使用-hive-drop-import-delims选项在导入时删除这些字符,以提供与hive兼容的文本数据。或者,您可以使用--hive-delims-replacement选项,在导入时将这些字符替换为用户定义的字符串,以提供与hive兼容的文本数据。只有在使用Hive的默认分隔符时才应该使用这些选项,如果指定了不同的分隔符,则不应该使用这些选项。
Sqoop将字段和记录分隔符传递到Hive。如果你不设置任何分隔符和使用--hive-import,字段分隔符将被设置为^A和记录分隔符将被设置为\ n与hive的默认分隔符是一致的。
Sqoop将默认导入NULL值作为字符串NULL。然而,Hive使用字符串\N来表示NULL值,因此处理NULL(比如is NULL)的谓词将不能正确工作。如果您希望正确地保留NULL值,那么在导入作业中应该附加参数--null-string和--null-non-string,或者在导出作业中附加参数--input-null-string和--input-null-non-string。由于sqoop在生成的代码中使用了这些参数,您需要正确地将值\N转义到\\N:
sqoop import ... --null-string '\\N' --null-non-string '\\N'
默认情况下,Hive中使用的表名与源表的表名相同。您可以使用--hive-table选项控制输出表名。
Hive可以将数据放入分区,以获得更高效的查询性能。通过指定—分分区键和—分分区值参数,可以告诉Sqoop作业将Hive的数据导入到特定分区。分区值必须是字符串。有关分区的详细信息,请参阅Hive文档。
您可以使用--compress和--compression-codec选项将压缩表导入Hive。压缩导入到Hive中的表的一个缺点是,许多编解码器不能通过并行映射任务进行处理。然而,lzop编解码器支持拆分。使用此编解码器导入表时,Sqoop将自动索引文件,以便使用正确的InputFormat拆分和配置新的Hive表。这个特性目前要求用lzop编解码器压缩表的所有分区。
- 将数据导入Hbase参数
| 参数 | 描述 |
|---|---|
| --column-family |
为导入设置目标列族 |
| --hbase-create-table | 如果指定,则创建丢失的HBase表 |
| --hbase-row-key |
指定将哪个输入列用作行键。如果输入表包含复合键,那么 |
| --hbase-table |
指定要用作目标的HBase表,而不是HDFS |
| --hbase-bulkload | 支持批量加载 |
通过指定--hbase-table,可以指示Sqoop导入HBase中的表,而不是HDFS中的目录。Sqoop将数据导入到指定的表中,作为-hbase-table的参数。输入表的每一行将被转换为输出表的一行的HBase Put操作。每一行的键是从输入的一列中获取的。默认情况下,Sqoop将使用按分列作为行键列。如果没有指定,它将尝试标识源表的主键列(如果有的话)。您可以使--hbase-row-key手动指定行键列。每个输出列将放置在相同的列族中,必须使用--column-family指定。
注意:
导入hbase不支持--direct参数
如果输入表具有复合键,那么--hbase-row-key必须以逗号分隔的复合键属性列表的形式出现。在这种情况下,HBase行的行键将通过使用下划线作为分隔符组合组合键属性的值生成。注意:只有在指定了参--hbase-row-key时,具有组合键的表的Sqoop导入才能工作。
如果目标表和列族不存在,Sqoop作业将退出,并出现错误。您应该在运行导入之前创建目标表和列系列。如果指定--hbase-create-table, Sqoop将使用HBase配置中的默认参数,在目标表和列系列不存在的情况下创建它们。
Sqoop当前将所有值序列化为HBase,方法是将每个字段转换为其字符串表示形式(就像以文本模式导入HDFS一样),然后将该字符串的UTF-8字节插入目标单元格。Sqoop将跳过除行键列之外的所有列中包含空值的所有行。
为了减少hbase上的负载,Sqoop可以进行批量加载,而不是直接写操作。若要使用批量加载,请启--hbase-bulkload。
导入数据到Accumulo
略,详情>>其他导入属性配置
| 参数 | 描述 |
|---|---|
| sqoop.bigdecimal.format.string | 控件将BigDecimal列存储为字符串时如何格式化。true(默认值)将使用toPlainString来存储它们,而不使用指数组件(0.0000001);而false的值将使用toString,该字符串可能包含指数(1E-7) |
| sqoop.hbase.add.row.key | 当设置为false(默认)时,Sqoop不会将用作行键的列添加到HBase中的行数据中。当设置为true时,用作行键的列将被添加到HBase中的行数据中。 |
sqoop import -D property.name=property.value ...
或者修改conf/sqoop-site.xml
property.name
property.value
完整示例1:mysql导入hbase
import
--connect
jdbc:mysql://host:3306/database
--username
'user'
--password
'pwd'
--query
'SELECT concat_ws("_",meter_id,DATE_FORMAT(create_time,"%Y%m%d%H%i%s")) AS row_key,meter_id,active_quan,create_time,flag FROM elec_meter_data_2018 WHERE create_time>="2018-09-01 00:00:00" AND create_time<"2018-10-01 00:00:00" AND $CONDITIONS'
--hbase-table
elec_meter_data
--hbase-create-table
--hbase-row-key
row_key
-m
3
--column-family
cf1
--split-by
create_time
2.1.2 sqoop-export
- 连接数据库参数
| 参数 | 描述 |
|---|---|
| --connect |
指定JDBC连接字符串 |
| --connection-manager |
指定要使用的连接管理器类 |
| --driver |
手动指定要使用的JDBC驱动程序类 |
| --hadoop-mapred-home |
覆盖$HADOOP_MAPRED_HOME变量 |
| --help | 打印使用说明 |
| --password-file | 为包含身份验证密码的文件设置路径 |
| -P | 从控制台读取密码 |
| --password |
设置身份验证密码 |
| --username |
设置身份验证用户名 |
| --verbose | 工作时打印更多信息 |
| --connection-param-file |
提供连接参数的可选属性文件 |
| --relaxed-isolation | 设置连接事务隔离,以便为映射器读取未提交的数据。 |
- 更详细的验证参数
| 参数 | 描述 |
|---|---|
| --validate | 启用数据复制的验证,只支持单表复制。 |
| --validator |
指定要使用的validator类。 |
| --validation-threshold |
指定要使用的验证阈值类。 |
| --validation-failurehandler |
指定要使用的验证失败处理程序类。 |
- 导出控制参数
| 参数 | 描述 |
|---|---|
| --columns |
要导出到表的列 |
| --direct | 使用直接导出快捷路径 |
| --export-dir |
导出的HDFS源路径 |
| -m,--num-mappers |
使用n个映射任务并行导出 |
| --table |
导出写入的表 |
| --call |
要调用的存储过程 |
| --update-key |
用于更新的固定列。如果有多个列,则使用逗号分隔的列列表。 |
| --update-mode |
指定在数据库中发现具有不匹配键的新行时如何执行更新。模式的合法值包括updateonly(默认值)和allowinsert |
| --input-null-string |
字符串列被解释为null的字符串 |
| --input-null-non-string |
对于非字符串列,要解释为null的字符串 |
| --staging-table |
数据插入目标表之前将在其中分段的表。 |
| --clear-staging-table | 指示可以删除暂存表中出现的任何数据。 |
| --batch | 使用批处理模式执行底层语句。 |
a、默认情况下,选择表中的所有列进行导出。可以使用
--columns参数选择列的子集并控制它们的顺序。这应该包括一个以逗号分隔的要导出的列列表。例如:--columns “col1、col2、col3”。注意--columns参数中不包含的列需要定义默认值或允许空值。否则,您的数据库将拒绝导入的数据,从而导致Sqoop作业失败。
b、直接导出并不总是支持将数据推入目标表之前的分段数据。当使用·--update-key·选项(用于更新现有数据)调用导出时,以及当使用存储过程插入数据时,它也不可用。 It is best to check the Section 25, “Notes for specific connectors” section to validate.
- 更新和插入(Inserts vs. Updates)
默认情况下,sqoop-export向表添加新行;将每个输入记录转换为一条INSERT语句,该语句将一行添加到目标数据库表中。如果您的表有约束(例如,主键列的值必须是惟一的),并且已经包含数据,则必须小心避免插入违反这些约束的记录。如果插入语句失败,导出过程将失败。如果指定
--update-key参数,Sqoop将修改数据库中的现有数据集。每个输入记录都被视为修改现有行的UPDATE语句。语句修改的行由--update-key指定的列名确定。
- 输入解析参数
| 参数 | 描述 |
|---|---|
| --input-enclosed-by |
设置所需的字段外壳 |
| --input-escaped-by |
设置输入转义字符 |
| --input-fields-terminated-by |
设置输入字段分隔符 |
| --input-lines-terminated-by |
设置输入行结束符 |
| --input-optionally-enclosed-by |
设置一个字段包围字符 |
- 输出行格式化参数
| 参数 | 描述 |
|---|---|
| --enclosed-by |
设置所需的字段包围字符 |
| --escaped-by |
设置转义字符 |
| --fields-terminated-by |
设置字段分隔符字符\b (backspace) \n (newline) \r (carriage return) \t (tab) " (double-quote) ' (single-quote) \ (backslash) \0 (NUL) |
| --lines-terminated-by |
设置行尾字符 |
| --mysql-delimiters | 使用MySQL的默认分隔符set: fields:, lines: \n escape -by: \ option -enclosed-by: ' |
| --optionally-enclosed-by |
设置一个字段包围字符 |
- 代码生成参数
| 参数 | 描述 |
|---|---|
| --bindir |
编译对象的输出目录 |
| --class-name |
设置生成的类名。这个覆盖--package-name。当与--jar-file组合时,设置输入类。 |
| --jar-file |
禁用代码生成;使用指定的jar |
| --outdir |
生成代码的输出目录 |
| --package-name |
将自动生成的类放到这个包中 |
| --map-column-java |
为已配置列覆盖从SQL类型到Java类型的默认映射。 |
示例1: 导出hive到mysql
export
--connect
jdbc:mysql://xxx:3306/xxx
--username
xxx
--password
xxx
--table
hive_tbname
--direct
--export-dir
/output/t_class --driver com.mysql.jdbc.Driver
--input-fields-terminated-by
'\t'
--lines-terminated-by
'\n'
2.1.3 sqoop-job
作业记住用于指定作业的参数,因此可以通过调用作业的句柄重新执行这些参数。
如果将保存的作业配置为执行增量导入,则有关最近导入的行的状态将在保存的作业中更新,以允许作业仅持续导入最新的行。
待续