客户端负载均衡 Spring Cloud Ribbon
1.综述
对于任何一个高可用高负载的系统来说,负载均衡是一个必不可少的名称。在大型分布式计算体系中,某个服务在单例的情况下,很难应对各种突发情况。因此,负载均衡是为了让系统在性能出现瓶颈或者其中一些出现状态下可以进行分发业务量的解决方案。
Spring Cloud Ribbon 是一个基于Http和TCP的客服端负载均衡工具,它是基于Netflix Ribbon实现的。它不像服务注册中心、配置中心、API网关那样独立部署,但是它几乎存在于每个微服务的基础设施中。
包括前面的提供的声明式服务调用也是基于该Ribbon实现的。理解Ribbon对于我们使用Spring Cloud来讲非常的重要,因为负载均衡是对系统的高可用、网络压力的缓解和处理能力扩容的重要手段之一。在上节的例子中,我们采用了声明式的方式来实现负载均衡。
实际上,内部调用维护了一个RestTemplate对象,该对象会使用Ribbon的自动化配置,同时通过@LoadBalanced开启客户端负载均衡。其实RestTemplate是Spring自己提供的对象,不是新的内容。
ribbon最核心的概念是:一个被命名的client,也即一个具有唯一名字的客户端每一个负载均衡都是整体组件的一部分,它们相互协作调用远程服务。每一个client都会通过类RibbonClientConfiguration创建一个新的子spring ApplicationContext,这个子ApplicationContext上下文的名子就是client的名字(如:@FeignClient("user-server"),每个ribbon客户端包含:
ILoadBalancer, RestClient, ServerListFilter, ServerList,IRule。
ILoadBalancer:是负载均衡的入口类。
ServerList:存储远程服务所有可用节点
ServerListFilter:用于过滤非法的远程节点(如:不可用等)
IRule:负载算法(策略),用于从可用节点选择一个合适的节点。
RestClient:远程调用
拦截&请求:

2.GET请求
第一种getForEntity函数,该方法返回的是ResponseEntity,该对象是字符串对HTTP请求响应的封装。
姓名,年龄两个参数对应的{1},{2}代表两个占位符,如要传递多个参数以此类推。
String.class返回值,如果需要返回对象对象的.class
getBody()是返回的ResponseEntity对象中的体内容。
/**
* Ribbon Get测试
* @return
*/
@RequestMapping(value="RibbonGet",method=RequestMethod.GET)
public String RibbonGet(@RequestParam("name") String name,@RequestParam("age") String age) {
return restTemplate.getForEntity("http://OrderService/GetTest?name={1}&age={2}", String.class,name,age).getBody();
}
注意占位符名称
/**
* Ribbon Get测试
* @return
*/
@RequestMapping(value="RibbonGet",method=RequestMethod.GET)
public String RibbonGet(@RequestParam("name") String name,@RequestParam("age") String age) {
//传递Map集合
Map params=new HashMap<>();
params.put("name", name);
params.put("age", age);
return restTemplate.getForEntity("http://OrderService/GetTest?name={name}&age={age}", String.class,params).getBody();
}
第二种getForObject函数,该方法可以理解为对getForEntity的进一步封装,返回的直接就是身体,如果不需要关注请求响应除身体外,该函数就非常好用。
/**
* Ribbon Get测试
* @return
*/
@RequestMapping(value="RibbonGet",method=RequestMethod.GET)
public String RibbonGet(@RequestParam("name") String name,@RequestParam("age") String age) {
return restTemplate.getForObject("http://OrderService/GetTest?name="+name+"&age="+age, String.class);
}
3.POST请求
第一种postForEntity函数,该方法返回的是ResponseEntity
/**
* Ribbon Post请求
* @param id
* @return
*/
@RequestMapping(value="ribbonPostOrder",method=RequestMethod.POST)
public User PostBeanTest(@RequestParam("id") Integer id) {
User user=new User();
user.setId(id);
ResponseEntity entity = restTemplate.postForEntity("http://OrderService/PostBeanTest", user, User.class);
return entity.getBody();
}
第二种postForObject函数,和postForEntity类似,简化了机身的处理。
/**
* Ribbon Post请求
* @param id
* @return
*/
@RequestMapping(value="ribbonPostOrder",method=RequestMethod.POST)
public User PostBeanTest(@RequestParam("id") Integer id){
User user=new User();
user.setId(id);
return restTemplate.postForObject("http://OrderService/PostBeanTest", user, User.class);
}
4.PUT请求
把函数为无效类型,所以没有返回内容。
/**
* Ribbon Put请求
* @param id
* @return
*/
@RequestMapping(value="ribbonPutOrder",method=RequestMethod.POST)
public String ribbonPutOrder(@RequestParam("id") Integer id,@RequestParam("name") String name){
User user=new User();
user.setId(id);
user.setName(name);
restTemplate.put("http://OrderService/PutTest",user);
return "PUT成功!";
}
5.DELETE请求
deleet函数为无效类型,所以没有返回内容。
/**
* Ribbon Delete请求
* @param id
* @return
*/
@RequestMapping(value="ribbonDeleteOrder",method=RequestMethod.POST)
public String ribbonDeleteOrder(@RequestParam("id") Integer id) {
restTemplate.delete("http://OrderService/DeleteTest/?id={1}",id);
return "删除成功";
}
6.配置
自动化配置
由于Ribbon中定义的每一个接口都有多种不同的策略实现,同时这些之间又有一定的依赖关系。
com.netflix.client.config.IClientConfig:Ribbon的客户端配置,默认采用com.netflix.client.config.DefaultClientConfigImpl实现。com.netflix.loadbalancer.IRule:Ribbon的负载均衡策略,默认采用com.netflix.loadbalancer.ZoneAvoidanceRule实现,该策略能够在多区域环境下选出最佳区域的实例进行访问。com.netflix.loadbalancer.IPing:Ribbon的实例检查策略,默认采用com.netflix.loadbalancer.NoOpPing实现,该检查策略是一个特殊的实现,实际上它并不会检查实例是否可用,而是始终返回true,默认认为所有服务实例都是可用的。com.netflix.loadbalancer.ServerList:服务实例清单的维护机制,默认采用com.netflix.loadbalancer.ConfigurationBasedServerList实现。com.netflix.loadbalancer.ServerListFilter:服务实例清单过滤机制,默认采org.springframework.cloud.netflix.ribbon.ZonePreferenceServerListFilter,该策略能够优先过滤出与请求方处于同区域的服务实例。com.netflix.loadbalancer.ILoadBalancer:负载均衡器,默认采用com.netflix.loadbalancer.ZoneAwareLoadBalancer实现,它具备了区域感知的能力。
上面的配置是在项目中没有引入spring Cloud Eureka,如果引入了Eureka和Ribbon依赖时,自动化配置会有一些不同。
通过自动化配置的实现,可以轻松的实现客户端的负载均衡。同时,针对一些个性化需求,我们可以方便的替换上面的这些默认实现,只需要在springboot应用中创建对应的实现实例就能覆盖这些默认的配置实现。
@Configuration
public class MyRibbonConfiguration {
@Bean
public IRule ribbonRule(){
return new RandomRule();
}
}
这样就会使用P使用了RandomRule实例替代了默认的com.netflix.loadbalancer.ZoneAvoidanceRule。
也可以使用@RibbonClient注解实现更细粒度的客户端配置
Camden版本对RabbitClient配置的优化
上面的方式主要是通过独立创建一个Configuration类来定义IPing,IRule等接口的具体实现Bean,然后通过RabbonClient时指定要使用的具体Configuration类来覆盖自动化配置的默认实现。在spring Cloud Ribbon Camden版本中对RibbonClient定义个性化配置的方法做出进一步优化。可以直接使用
user-service.ribbon.NFLoadBalancerPingClassName=com.netfix.loadbalancer.PingUrl
user-service是服务名,NFLoadBalancerPingClassName参数是用来指定IPing接口实现类。在Camden版本中,Spring Cloud Ribbon新增了一个org.springframework.cloud.netflix.ribbon.PropertiesFactory类动态的为RibbonClient创建这些接口实现。
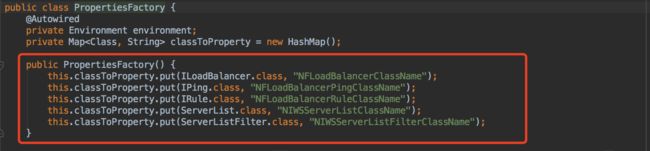
在Camden版本中我们可以通过配置的方式,更加方便的为RibbonClient指定ILoadBalancer,IPing,IRule,ServerList,ServerListFilter的定制化实现。
参数配置
对于Ribbon的参数通常有二种方式:全局配置以及指定客户端配置
- 全局配置的方式很简单
只需要使用ribbon.格式进行配置即可。其中,= Ribbon客户端配置的参数名,Ribbon的超时时间
ribbon.ConnectTimeout=250
全局配置可以作为默认值进行设置,当指定客户端配置了相应的key的值时,将覆盖全局配置的内容
- 指定客户端的配置方式
.ribbon. = .表示服务名,比如没有服务治理框架的时候(如Eureka),我们需要指定实例清单,可以指定服务名来做详细的配置,
user-service.ribbon.listOfServers=localhost:8080,localhost:8081,localhost:8082
对于Ribbon参数的key以及value类型的定义,可以通过查看com.netflix.client.config.CommonClientConfigKey类。
与Eureka结合
当在spring Cloud的应用同时引入Spring cloud Ribbon和Spring Cloud Eureka依赖时,会触发Eureka中实现的对Ribbon的自动化配置。这时的serverList的维护机制实现将被com.netflix.niws.loadbalancer.DiscoveryEnabledNIWSServerList的实例所覆盖,该实现会讲服务清单列表交给Eureka的服务治理机制来进行维护。IPing的实现将被
com.netflix.niws.loadbalancer.NIWSDiscoveryPing的实例所覆盖,该实例也将实例接口的任务交给了服务治理框架来进行维护。默认情况下,用于获取实例请求的ServerList接口实现将采用Spring Cloud Eureka中封装的
org.springframework.cloud.netflix.ribbon.eureka.DomainExtractingServerList,其目的是为了让实例维护策略更加通用,所以将使用物理元数据来进行负载均衡,而不是使用原生的AWS AMI元数据。
在与Spring cloud Eureka结合使用的时候,不需要再去指定类似的user-service.ribbon.listOfServers的参数来指定具体的服务实例清单,因为Eureka将会为我们维护所有服务的实例清单,而对于Ribbon的参数配置,我们依然可以采用之前的两种配置方式来实现。
此外,由于spring Cloud Ribbon默认实现了区域亲和策略,所以,可以通过Eureka实例的元数据配置来实现区域化的实例配置方案。比如可以将不同机房的实例配置成不同的区域值,作为跨区域的容器机制实现。而实现也非常简单,只需要服务实例的元数据中增加zone参数来指定自己所在的区域,比如:
eureka.instance.metadataMap.zone=shanghai
在Spring Cloud Ribbon与Spring Cloud Eureka结合的工程中,我们可以通过参数禁用Eureka对Ribbon服务实例的维护实现。这时又需要自己去维护服务实例列表了。
ribbon.eureka.enabled=false.
7. 重试机制
由于Spring Cloud Eureka实现的服务治理机制强调了cap原理的ap机制(即可用性和可靠性),与zookeeper这类强调cp(一致性,可靠性)服务质量框架最大的区别就是,Eureka为了实现更高的服务可用性,牺牲了一定的一致性,在极端情况下宁愿接受故障实例也不要丢弃"健康"实例。
比如说,当服务注册中心的网络发生故障断开时候,由于所有的服务实例无法维护续约心跳,在强调ap的服务治理中将会把所有服务实例剔除掉,而Eureka则会因为超过85%的实例丢失心跳而触发保护机制,注册中心将会保留此时的所有节点,以实现服务间依然可以进行互相调用的场景,即使其中有部分故障节点,但这样做可以继续保障大多数服务的正常消费。
在Camden版本,整合了spring retry来增强RestTemplate的重试能力,对于我们开发者来说,只需要简单配置,即可完成重试策略。
spring.cloud.loadbalancer.retry.enabled=true
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=10000
user-service.ribbon.ConnectTimeout=250
user-service.ribbon.ReadTimeout=1000
user-service.ribbon.OkToRetryOnAllOperations=true
user-service.ribbon.MaxAutoRetriesNextServer=2
user-service.ribbon.maxAutoRetries=1
spring.cloud.loadbalancer.retry.enabled:该参数用来开启重试机制,它默认是关闭的。
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds:断路器的超时时间需要大于Ribbon的超时时间,不然不会触发重试。
user-service.ribbon.ConnectTimeout:请求连接超时时间。
user-service.ribbon.ReadTimeout:请求处理的超时时间
user-service.ribbon.OkToRetryOnAllOperations:对所有操作请求都进行重试。
user-service.ribbon.MaxAutoRetriesNextServer:切换实例的重试次数。
user-service.ribbon.maxAutoRetries:对当前实例的重试次数。
根据以上配置,当访问到故障请求的时候,它会再尝试访问一次当前实例(次数由maxAutoRetries配置),如果不行,就换一个实例进行访问,如果还是不行,再换一个实例访问(更换次数由MaxAutoRetriesNextServer配置),如果还不行,返回失败。

8.Ribbon 提供的主要负载均衡策略:
1:简单轮询负载均衡(RoundRobin)
以轮询的方式依次将请求调度不同的服务器,即每次调度执行i = (i + 1) mod n,并选出第i台服务器。
2:随机负载均衡 (Random)
随机选择状态为UP的Server
3:加权响应时间负载均衡 (WeightedResponseTime)
根据响应时间分配一个weight,响应时间越长,weight越小,被选中的可能性越低。
4:区域感知轮询负载均衡(ZoneAvoidanceRule)
复合判断server所在区域的性能和server的可用性选择server
less is more.