东方财富网提供了上市公司的公告大全,将其抓取出来,进行整理后,提供给基金经理做投资决策。本文介绍了该项目的python爬虫实现过程。
- 需求分析
- 业务分析
- 页面数据分析
- 程序结构设计
- 编码实现
- 基础工具函数
- 逻辑实现
需求分析
1.1 业务分析
分析公告汇总页面,发现沪深A股公告、中小板公告、创业板公告,页面表现比较一致,而三板公告实现方式有所变化,先抓取沪深A股公告、中小板公告和创业板公告
1.2 页面数据分析
翻页页面,发现地址栏链接不变,数据是采用ajax动态加载。
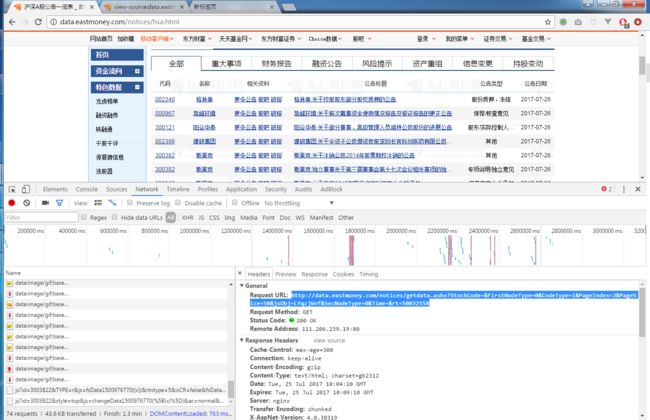
Paste_Image.png
在chrome的Network中找到数据请求地址:
http://data.eastmoney.com/notices/getdata.ashx?StockCode=&FirstNodeType=0&CodeType=1&PageIndex=2&PageSize=50&jsObj=LYqzjWvf&SecNodeType=0&Time=&rt=50032558
http://data.eastmoney.com/notices/getdata.ashx?StockCode=&FirstNodeType=0&CodeType=1&PageIndex=3&PageSize=50&jsObj=maFEjDLX&SecNodeType=0&Time=&rt=50032562
同时在网页源代码中也发现:
dataurl: "/notices/getdata.ashx?StockCode=&FirstNodeType=0&CodeType=3&PageIndex={page}&PageSize={pageSize}&jsObj={jsname}{param}",
对比大概可以肯定如下参数:
CodeType 公告板块分类
PageIndex 页面序号
PageSize 页面大小
不太确定的是
jsObj和rt这2个参数。
继续分析网络请求,发现有一个load_table_data.js的请求,看起来比较可疑。在load_table_data.js中搜索jsObj未发现,但是搜索&rt发现下面代码:
update: function () {
var _t = this;
if (_t.options.beforeupdate(_t))
return;
var jsname = _t.getCode(8),
_url = _t.parperUrl();
_t.options.code = jsname;
_url = _url.replace("{jsname}", jsname);
_url += (_url.indexOf('?') > -1) ? "&rt=" : "?rt=";
_url += parseInt(parseInt(new Date().getTime()) / 30000);
_t.loadThead();
_t.scorllTop();
_t.showLoading();
_t.tools.loadJs(_url, _t.options.charset,
function () {
if (typeof (_t.options.load_div) != "undefined") {
if (_t.options && _t.options.nodetemp) {
_t.options.nodetemp.style.position = "";
}
_t.options.load_div.style.display = "none"
}
if (!(eval("typeof " + jsname) == "undefined") || eval("typeof " + jsname == null)) {
var loaddata = eval(jsname);
if (jsname != _t.options.code) {
return
}
_t.options.data = loaddata;
_t.display()
} else {
// alert("数据加载失败,请刷新页面重新尝试!")
if (console && console.log) {
console.log("tools.loadJs挂了稍后再改");
}
}
})
},
大概就是这里了,在257行,加上断点调试一下(如果对前端不太熟悉,调试方式是在chrome开发者工具的【Sources】标签里,找到load_table_data.js ,鼠标点击257行)
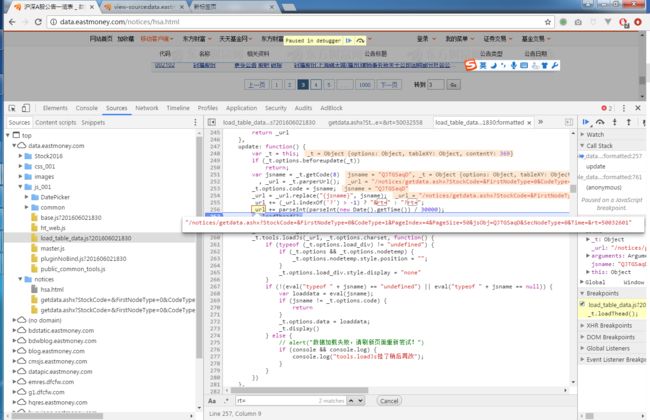
Paste_Image.png
这样就确认了链接里的jsObj和rt的实现方法。
jsObj生成函数如下:
getCode: function (num) {
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
var codes = str.split('');
num = num || 6;
var code = "";
for (var i = 0; i < num; i++) {
code += codes[Math.floor(Math.random() * 52)]
}
return code
},
var jsname = _t.getCode(8),
rt生成代码如下
parseInt(parseInt(new Date().getTime()) / 30000)
1.3 程序结构设计
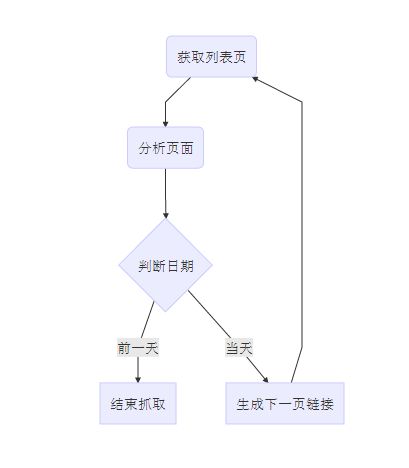
Paste_Image.png
(直接使用有道云笔记md画的图,有点渣)
编码实现
基础工具函数
- 下载函数、参数解析
参看上市公司重要公告集锦抓取 - jsObj 模拟函数
# load_table_data.js getCode
def getCode(num=6):
s = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
codes = list(s)
code = ""
for x in xrange(0, num):
idx = int(math.floor(random() * 52))
code += codes[idx]
return code
- rt 模拟函数
# _url += parseInt(parseInt(new Date().getTime()) / 30000);
def getRightTime():
r = int(time.time() / 30)
return r
- 邮件附件上传
参看上市公司重要公告集锦抓取,关于附件上传部分如下:
mail_msg = read_html(now)
# 邮件正文内容
# msg.attach(MIMEText(now+" 日,二级市场公告信息。详情请见附件excel", 'plain', 'utf-8'))
msg.attach(MIMEText(mail_msg, 'html', 'utf-8'))
# 构造附件2,传送当前目录下的 xls 文件
att2 = MIMEText(open(fileName, 'rb').read(), 'base64', 'utf-8')
att2["Content-Type"] = 'application/octet-stream'
# 解决中文附件下载时文件名乱码问题
att2.add_header('Content-Disposition', 'attachment', filename='=?utf-8?b?' +
base64.b64encode(fileName.encode('UTF-8')) + '?=')
msg.attach(att2)
- 日期比较
def time_compare(notice_date):
tt = time.mktime(time.strptime(notice_date, "%Y-%m-%d"))
# 得到公告的时间戳
if noticeCate == 1:
# A股公告取当日
# 得到本地时间(当日零时)的时间戳
st = time.strftime("%Y-%m-%d", time.localtime(time.time()))
else:
# 新三板公告取前日
# 得到本地时间(当日零时)的时间戳
st = time.strftime(
"%Y-%m-%d", time.localtime(time.time() - 60 * 60 * 24))
t = time.strptime(st, "%Y-%m-%d")
now_ticks = time.mktime(t)
# 周一需要是大于
if tt >= now_ticks:
return True
else:
return False
- excel读写
# 写excel
def write_sheet(workbook, sheetName, rows):
worksheet = workbook.add_sheet(sheetName)
worksheet.write(0, 0, label="代码")
worksheet.write(0, 1, label="名称")
worksheet.write(0, 2, label="公告标题")
worksheet.write(0, 3, label="公告类型")
for x in xrange(0, len(rows)):
row = rows[x]
for y in xrange(0, 4):
if y == 2:
alink = 'HYPERLINK("%s";"%s")' % (row[4], row[2])
worksheet.write(x + 1, y, xlwt.Formula(alink))
else:
item = row[y]
worksheet.write(x + 1, y, item)
# 打开excel
def open_excel(file='file.xls'):
try:
data = xlrd.open_workbook(file)
return data
except Exception, e:
logger.debug(str(e))
- 数据循环下载
def do_notice(notices, plate):
for page in xrange(1, 10):
rt = getRightTime()
code = getCode(8)
url = getUrl(apiurl, plate["codeType"], page, code, rt)
jsdata = download_get_html(url)
if jsdata != None:
json_str = jsdata[15:-1]
datas = json.loads(json_str)["data"]
for data in datas:
# 公告日期
notice = parser_data(data)
if notice != None:
notices.append(notice)
else:
logger.debug("page end notices %s %d"& (plate["name"], len(notices)))
return
else:
logger.debug("no notices %s %d"& (plate["name"], len(notices)))
return
- 数据解析
def parser_data(data):
temp = data["CDSY_SECUCODES"][0]
noteicedate = data["NOTICEDATE"]
date = noteicedate[0:noteicedate.index('T')]
code = temp["SECURITYCODE"]
name = temp["SECURITYSHORTNAME"]
title = data["NOTICETITLE"]
typeName = '公司公告'
if data["ANN_RELCOLUMNS"] and len(data["ANN_RELCOLUMNS"]) > 0:
typeName = data["ANN_RELCOLUMNS"][0]["COLUMNNAME"]
namestr = unicode(name).encode("utf-8")
detailLink = baseurl + '/notices/detail/' + code + '/' + \
data["INFOCODE"] + ',' + \
base64.b64encode(urllib.quote(namestr)) + '.html'
# print date,code,name,title,typeName,detailLink
if time_compare(date):
return [code, name, title, typeName, detailLink, date]
else:
return None