一.主题式网络爬虫设计方案
1.主题式网络爬虫的名称
58同城租房信息的爬取
2.主题式网络爬虫的内容与数据特征分析
A.爬虫的内容
文章标题,房产位置,房间数量,房间大小,代理人
B.数据特征分析
b1对房间数量,地理位置,代理公司(人)做一个词云
b2对房间数量做一个柱状图
3.主题式网络爬虫设计方案概述(包括实现思路和技术难点)
A.实现思路
创建一个House的类,定义get_info()获取所有的网址,通过get_alldata()函数进行对整体页面的爬取,创建get_page()进行网站的解码,用get_detail()方法进一步获取数据。再创建一个实例对象,调用这些函数。
3.2技术难点
爬取过程中遇到阻拦,需要模拟用户操作进行爬取,一些字符被加密,需要解密。
二.主题页面的结构特征分析
1.主题页面的特征结构
每页选取了25条数据,共计70页,数据项1750,通过F12进行页面的查看。发现所需要爬取的数据都是静态的。
2.HTML页面解析
框框中的数据都是需要爬取的字段。

3.节点(标签)查找方法与遍历发法(必要时画出节点数结构)
查找节点的方法采用BeautifulSoup,用find方法,先找到最大的接点,再用for循环进行遍历,找到要爬取的节点。
三.网络爬虫程序设计
1,爬虫程序主题要包括以下部分,要附源代码及较详解注释,并在每部分程序后面提供输出结果的截图。
# -*- coding: utf-8 -*-
"""
Created on Mon Dec 16 14:00:43 2019
@author: admin
"""
import requests
from bs4 import BeautifulSoup
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
import seaborn as sns
from fontTools.ttLib import TTFont
import base64
from io import BytesIO
from fontTools.ttLib import TTFont
import re
from lxml import etree
#58租房前面固定的url地址,点击后一页变化的是后面的数字
url_title = 'https://qz.58.com/chuzu/pn'
#定义一个空字典用于接收爬取到的数据
house_detail ={}
#===============================================数据爬取================================================
#定义一个类进行爬取
class House:
#获取所有url,将固定的url和可变参数进行结合
def get_info(self):
#空字符串用于接收全部url
list1 = []
#一共有70个网址
for i in range(0,71):
#拼接参数得到完整的url
url = url_title+str(i)
list1.append(url)
return list1
#解析出网页
def get_alldata(self,url):
#模拟用户操作,否则会有反爬机制
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
#设置请求头
headers = {'User-Agent': user_agent}
#通过requets获取页面信息
data = requests.get(url,headers=headers)
#解析全部的页面
soup = BeautifulSoup(data.text,'lxml')
return soup
def get_page_show_ret(self,soup):
font = TTFont(BytesIO(base64.decodebytes(bs64_str.encode())))
c = font.getBestCmap()
ret_list = []
for char in soup:
decode_num = ord(char)
if decode_num in c:
num = c[decode_num]
num = int(num[-2:])-1
ret_list.append(num)
else:
ret_list.append(char)
ret_str_show = ''
for num in ret_list:
ret_str_show += str(num)
return ret_str_show
#获取title,room,area,jjr等,并存入字典
def get_detail(self,soup):
#获取一页前25个数据,每一页的条数是不一样的,所以避免出错取前25个
for i in range(0,25):
#获取整块内容
data1 = soup.select('div[class="des"]')[i]
#获取房屋销售信息的标题
house_title =data1.find_all("h2")
house_title =house_title[0].get_text()
house_title = get_page_show_ret(house_title)
#获取房屋销售信息的房间数
house_room =data1.find_all("p",class_="room")
house_room = house_room[0].get_text()
house_room = get_page_show_ret(house_room)
#获取房屋销售信息的具体地址
house_area =data1.find_all("p",class_="infor")
house_area = house_area[0].get_text()
house_area = get_page_show_ret(house_area)
#获取房屋销售信息的经纪人
house_jjr =data1.find_all("div",class_="jjr")
#如果没有经纪人(为个人房源),则显示为个人房源。
if house_jjr==[]:
house_jjr =data1.find_all("p",class_="geren")
house_jjr = house_jjr[0].get_text()
house_jjr = get_page_show_ret(house_jjr)
#将所有信息存入一个dict
data = {
'house_title':house_title,
'house_room':house_room,
'house_area':house_area,
'house_jjr':house_jjr
}
#用之前定义的空字典接收data
#用data的title做key
house_detail[data["house_title"]] = data
return house_detail
实例化
#创建一个实例对象 house_data = House() #实例对象接收全局的页面信息 house_url =house_data.get_info() #对每一个url进行遍历 for house_item in house_url: #获取一段内容 house_soup= house_data.get_alldata(house_item) #获取具体信息,返回data data = house_data.get_detail(house_soup) #将dict转化成dataframe df = pd.DataFrame.from_dict(data) #将dataframe进行转置 df = df.T #reindex df.index=range(len(df))
数据清洗
'''
对house_title进行清洗
'''
#把整租合租的信息区分出来
df["house_title"]=df["house_title"].apply(lambda x:x.split('|')[0])
#将前后的空格去掉
df["house_title"]=df["house_title"].apply(lambda x:x.strip())
'''
对house_room进行清洗
'''
#把几室几厅和平方区分出来
#房间数量
#把前后空格去了
df["house_room"] = df["house_room"].apply(lambda x:x.strip())
df['room_number']=df["house_room"].apply(lambda x:x.split(" ")[0])
#占地面积
df['room_area']=df["house_room"].apply(lambda x:x.split(" ")[1])
#把house_room去了
del df['house_room']
'''
对house_area清洗
'''
df['house_area']=df['house_area'].apply(lambda x:x.strip())
'''
对house_jjr进行清洗
'''
df['house_jjr']=df['house_jjr'].apply(lambda x:x.strip())
def deal(x):
if x=="来自个人房源":
return x
else:
return x[6:].strip()
df['house_jjrr']=df.house_jjr.apply(deal)
del df['house_jjr']
df.to_excel(r'C:\Users\DATACVG\Desktop\600\58.xlsx')

数据可视化
#对house_area进行词云
cut_text = "".join(df['house_area'])
wordcloud = WordCloud(
font_path="C:/Windows/Fonts/simfang.ttf",
background_color="white",width=1000,height=800).generate(cut_text)
plt.imshow(wordcloud,interpolation="bilinear")
plt.axis("off")
plt.show()
#room_nunber进行词云
cut_text1 = "".join(df['room_number'])
wordcloud = WordCloud(
font_path="C:/Windows/Fonts/simfang.ttf",
background_color="white",width=1000,height=800).generate(cut_text1)
plt.imshow(wordcloud,interpolation="bilinear")
plt.axis("off")
plt.show()
#house_jjrr进行词云
cut_text2 = "".join(df['house_jjrr'])
wordcloud = WordCloud(
font_path="C:/Windows/Fonts/simfang.ttf",
background_color="white",width=1000,height=800).generate(cut_text2)
plt.imshow(wordcloud,interpolation="bilinear")
plt.axis("off")
plt.show()
#对room_number绘制柱状图
df1=df['room_number'].value_counts()
sns.barplot(x=df1.index,y=df1.values)
#对room_area绘制折线图
df['room_area'] = df['room_area'].apply(lambda x:x.split("㎡")[0])
df['room_area'] = df['room_area'].apply(lambda x:float(x))
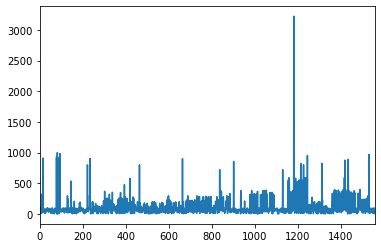
df['room_area'].plot()
四、数据可视化
对house_price进行词云

对house_jjrr进行词云

对room_number进行词云分析

对room_area绘制折线图
数据可视化
写入excel文件

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.1 客户比较偏爱两室一厅或者一室一厅。
1.2 世贸摩天城的房子出租的较多。
1.3 占地1200平的房子最多
通过本次作业,学会了很多的知识,也对数据分析有了初步的认识,加油。