1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课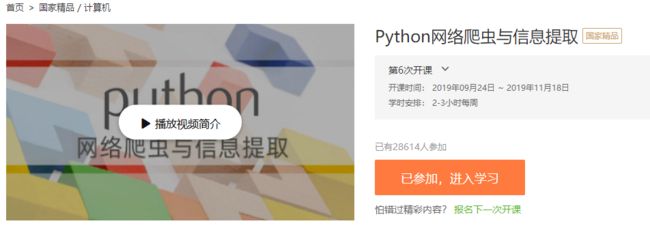
3.学习完成第0周至第4周的课程内容,并完成各周作业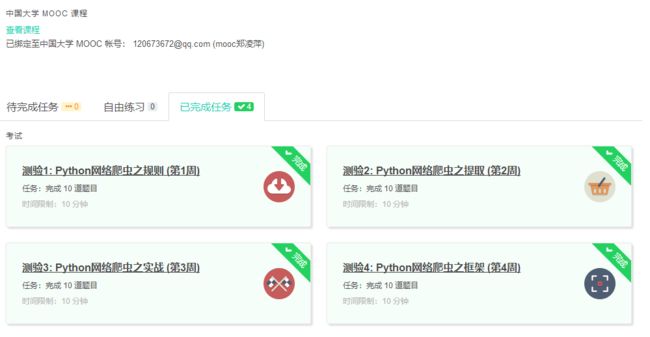
4.提供图片或网站显示的学习进度,证明学习的过程。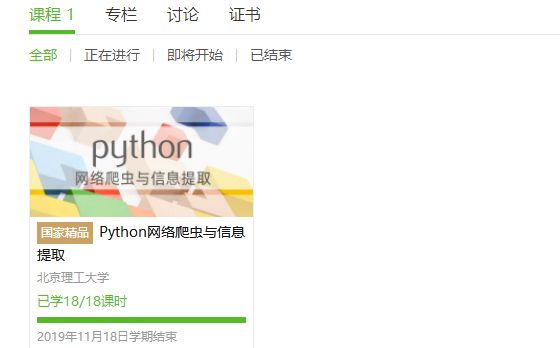
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
学习笔记:这门课程介绍Python计算生态中最优秀的网络数据爬取和解析技术,具体讲授构建网络爬虫功能的两条重要技术路线:requests-bs4-re和Scrapy,课程内容是进入大数据处理、数据挖掘、以数据为中心人工智能领域的必备实践基础。教学内容包括:Python第三方库Requests,讲解通过HTTP/HTTPS协议自动从互联网获取数据并向其提交请求的方法;Python第三方库Beautiful Soup,讲解从所爬取HTML页面中解析完整Web信息的方法;Python标准库Re,讲解从所爬取HTML页面中提取关键信息的方法;python第三方库Scrapy,介绍通过网络爬虫框架构造专业网络爬虫的基本方法。
第一周学习的是Requests,使用命令管理器安装,使用IDLE检测是否安装成功,状态码为200,便是安装成功。老师讲了Requests的七个主要方法,分别是:requests.requests()、requests.get() 、requests.head()、requests.post()、requests.put()、requests.patch()、requests.delete()。老师还讲述了两个重要对象:Response和Request。
Requests能够自动爬取html页面,自动网络请求提交。我们在使用爬虫时虽然能爬取到自己需要的数据,但是网络爬虫还是有可能引起性能骚扰、法律风险、隐私泄露等问题。
五种元素分别是:
1. Tag 标签,最基本的信息组织单元,分别用<> 和标明开头和结尾
2. Name 标签的名字,
…
的名字是'p',格式:3. Attributes 标签的属性,字典形式组织,格式:.attrs
4. NavigableString 标签内非属性字符串,<>…中字符串,格式:
5. Comment 标签内字符串的注释部分,一种特殊的Comment类型
第三周学习的是Re正则表达式。
正则表达式是用来简洁表达一组字符串的表达式,它的优势是简洁。它经常用于表达文本类型的特征(病毒、入侵等)、同时查找或替换一组字符串、匹配字符串的全部或部分。最主要应用在字符串匹配中。
我们还学到了Re库六个主要功能函数:
1. re.search() 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
2. re.match() 从一个字符串的开始位置起匹配正则表达式,返回match对象
3. re.findall() 搜索字符串,以列表类型返回全部能匹配的子串
4. re.split() 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
5. re.finditer() 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
6. re.sub() 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
第四周 网络爬取的框架
介绍了专业的爬虫框架及其基本使用
Scrapy相对于requests 性能较高但入门稍难 然后演示了HTML地址实例
,yield关键字和生成器 CSS Selector的基本使用
实现股票数据Scrapy爬虫的完整配置过程:建立工程和Spider模板然后编写Spider 、Pipeline以及配置优化
在开始学习这门慕课之前对网络爬虫了解并多,网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据。80%爬虫是基于Python开发的,学好爬虫技能,可为后续的大数据分析、挖掘、机器学习等提供重要的数据源。所以这门课程对今后的学习工作的帮助都是很大的。