1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
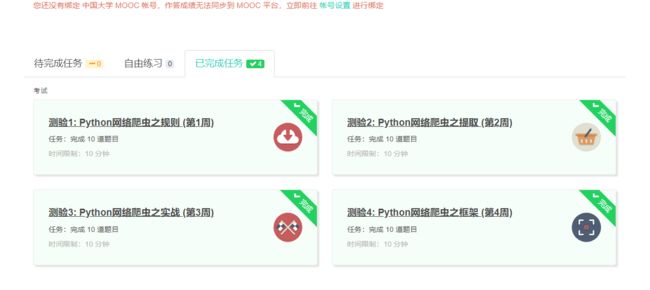
4.提供图片或网站显示的学习进度,证明学习的过程。
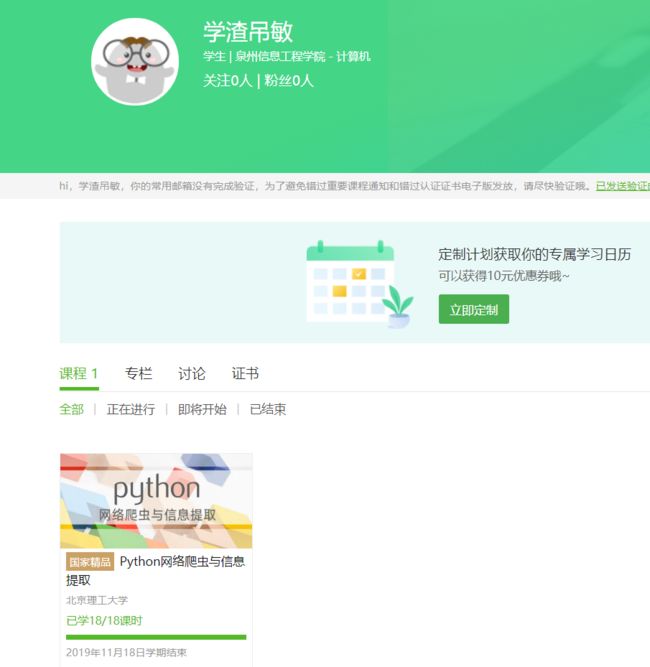
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
首先是对Python软件的基础了解。最常用的Python IDE工具:IDLE,Sublime Text,PyCharm,Anaconda&Spyder。
1).IDLE优点有:自带,默认,常用,入门级。建议300行以下
2).Sublime Text:这是一个专为程序员开发的第三方专用编程工具,有专业的编程体验,有多重编程风格,是非常适合程序员的一款
3).PyCharm:社区版免费,较为简单且集成度高,适合较为复杂的工程
4).Anaconda:开源免费,支持近800个第三方库
下面是正式的学习环节:
先安装Requests库与测试,成功后开始认识Requests库的主要方法,大概有7个:request,get,head,post,put,patch和delete。其功能都是对应HTTP里的功能。
Response对象一共有5个,status_code(HTTP请求的返回状态,200表示成功,404表示失败),text(url对应的页面内容),enconding(从HTTP header中猜测的响应内容编码方式),apparent_encoding(从内容中分析出的响应内容编码方式)和content(HTTP响应内容的二进制形式)。
Requests库异常:
1)requests.ConnectionError:网络连接错误异常。
2)requests.HTTPError:HTTP错误异常
3)requests.URLRequired:URL缺失异常
4)requests.TooManyRedirects:超过最大重定向次数,产生重定向异常
5)requests.ConnectTimeout:连接远程服务器超时异常
6)requests.Timeout:请求URL超时,产生超时异常。
HTTP协议对资源的操作:GET:请求获取URL位置的资源。 HEAD:请求获取该资源头部信息。 POST:请求向URL位置的资源后附加新数据。 PUT:请求向URL位置存储一个资源,覆盖原位置的资源 。PATCH:请求局部更新URL位置的资源,即改变该处资源的部分内容 。DELETE:请求删除URL位置存储的资源。
网络爬虫的法律风险:
1)服务器上的数据有产权归属
2)网络爬虫获取的数据牟利后将带来法律风险
3)网络爬虫可能具备突破简单控制的能力,获得被保护数据,从而泄露个人隐私
网络爬虫的限制:
1)来源审查:判断User-Agent进行限制(检查来访HTTP协议头的User-Agent域,只响应浏览器或友好爬虫的访问)
2)发布公告:Robots协议(告知所有爬虫网站的爬取策略,要求爬虫遵守)
Beautiful Soup库解析器:soup=BeautifulSoup(‘data’,’html.parser’)
解析器:
1) bs4的HTML解析器:BeautifulSoup(mk,’html.parser’)--条件:安装
2) bs4 lxml的HTML解析器:BeautifulSoup(mk,’lxml’)--条件:pip install lxml
3) lxml的XML解析器:BeautifulSoup(mk,’xml’)--条件:pip install lxml
4) html5lib的解析器:BeautifulSoup(mk,’html5lib’)--条件:pip install html5lib
BeautifulSoup的基本元素:
1)Tag:标签,最基本的信息组织单元,分别用<>和表明开头和结尾
2)Name:标签的名字,
的名字是’p’,格式:3)Attributes:标签的属性,字典形式组织,格式:
4)NavigableString:标签内非属性字符串,<>...中字符串,格式:
5)Comment:标签内字符串的注释部分,一种特殊的Comment类型
标签数的下行遍历:
1).contents:子节点的列表,将
2).Children:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
3).descendants:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历。
BeautifulSoup类型是标签数的根节点。
标签数的上行遍历:
1).parent:节点的父亲标签
2).parents:节点先辈标签的迭代类型,用于循坏遍历先辈节点。
标签数的平行遍历:
1).next_sibling:返回按照HTML文本顺序的下一个平行节点标签
2).previous_sibling:返回按照HTML文本顺序的上一个平行节点标签
3).next_siblings:迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
4).previous_siblings:迭代类型,返回按照HTML文本顺序的前续所有平行节点标签。
总结:通过这些天嵩天老师的教诲,我受益匪浅。初步踏入Python爬虫殿堂的大门,我深刻地认识到了爬虫的强大。也让我打下了坚实的基础。希望能更进一步学习。