1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
4.提供图片或网站显示的学习进度,证明学习的过程。
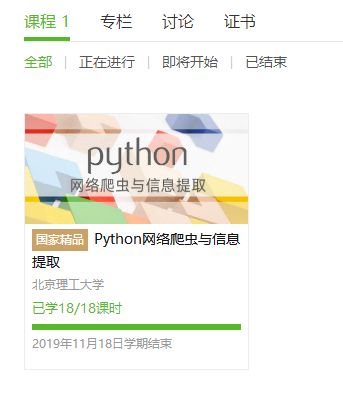
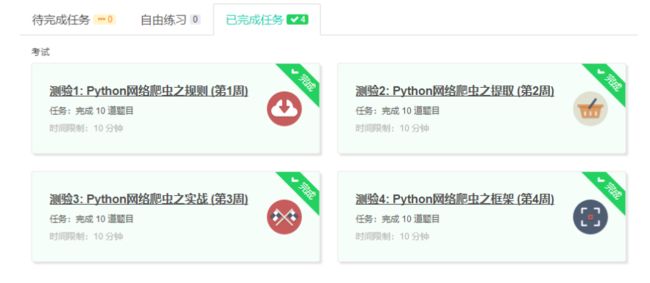
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
网上有很多很多关于这一类东西的教程,我也仅仅是可以实现,并且停留在一知半解的程度,在代码过程中添加了很多对Python的新的理解,对编程这个大集合的更深层的理解。
其实本质上来说爬虫就是一段程序代码。任何程序语言都可以做爬虫,只是繁简程度不同而已。从定义上来说,爬虫就是模拟用户自动浏览并且保存网络数据的程序,当然,大部分的爬虫都是爬取网页信息
爬虫架构:URL管理器,网页下载器,网页解析器
URL管理器:管理待抓取URL集合和已抓取URL集合 防止重复抓取。
URL管理器实现方法: 缓存数据库:大公司,性能高 内存:个人,小公司 关系数据库:永久保存URL数据或节约内存
网页下载器:将URL对应的网页以HTML下载到本地,用于后续分析 常见网页下载器:Python官方基础模块:urllib2 第三方功能包:requests
python 3.x中urllib库和urilib2库合并成了urllib库。 其中urllib2.urlopen()变成了urllib.request.urlopen() urllib2.Request()变成了urllib.request.Request()
现实上,我犯了一个错误,当我拥有了python这一爬虫工具后,我就自以爲掌握了爬虫的钥匙,无坚不摧,所向无敌,但是我无视了所针对的对象——网页是千变万化,多种多样的,掌握了一种办法,不一定能用在其他中央。只要掌握了对象的实质与共通点,你才干融会贯穿。爬虫就相当于我们手里有了一个机器人,它会替代我们去向这座大厦发送拜访请求,会假装本人来应对反爬虫机制,会将整个大厦的布局降维输入,构成立体图(文本),会依据立体图精准定位每个房间的某个标志爲price的盒子,并将一切房间的一切盒子里的信息抓取到。
开始编码爬虫
如果用urllib库发送请求,则需要自己编码Cookie这一块(虽然也只要几行代码),但用Requests库就不需要这样,在目前最新版本中,requests.Session提供了自己管理Cookie的持久性以及一系列配置,可以省事不少。
关于失败了验证的方法,我强烈建议下载fiddler,利用新建视图,把登录过程中所有的图片,CSS等文件去掉以后放到新视图中,然后利用程序登录的过程也放一个视图当中,如果没有在响应中找到需要的Cookie,还可以在视图中方便的查看各个JS文件,比浏览器自带的F12好用太多了。
总之,经过这段时间的学习,我对爬虫也有了个初步的了解,在这方面,也有了自己做法:
抓包请求 —> 模仿请求头和表单—>如果请求失败,则仔细对比正常访问和程序访问的数据包 —>成功则根据内容结构进行解析—>清清洗数据并展示