一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
交易猫英雄联盟(LOL)所有商品的爬取
2.主题式网络爬虫爬取的内容与数据特征分析
2.1爬取的内容
操作系统,游戏名称,游戏客户端,游戏区服,价格,游戏商品类型,游戏等级,英雄个数,段位,
皮肤,精粹数量,角色昵称,账号认证,是否绑定成长守护平台,完成时间,商家在线,描述
2.2数据特征分析
分析不同英雄,皮肤下价格的差异
比较不同区服卖号的人数
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
1、通过requests的get方法请求网站地址,并进行头部信息验证
2、利用etree进行网页解析,并通过xpath获取所要的相关数据
3、判断所要的数据是否存在,并进行切片处理
4、并通过循环进行翻页处理
5、通过os、DataFrame进行数据的保存,以便后期进行数据分析和数据清洗
技术难点:
1、在前期的时候获取不到数据,需要设置头部信息
2、获取商品的链接,并进入到商品详细页面中获取消息
3、获取的每一个商品的信息个数都不一样
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
通过浏览器的F12键,并且查找到Elements栏,可以发现当前页面的商品处于当前页面的ul[class="list-con specialList"]标签中,并且是ul[class="list-con specialList"]在当前页面是唯一的。一条商品的信息处于ul下的一个li中。li中的信息可以通过点击标题链接进入商品详细页面进行内容的获取。



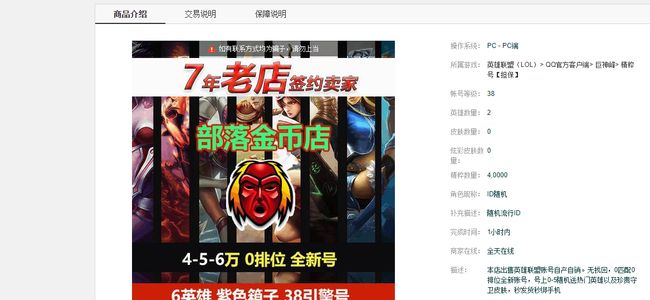
2.Htmls页面解析
可以发现商品的全部信息都处于div[class="goods-properties"]中,每一条信息都处于p[class="row"]中
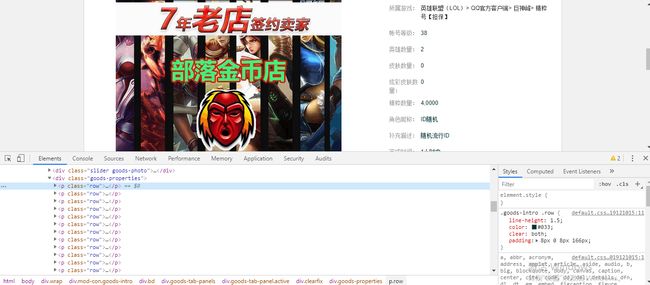
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
先通过etree的HTML方法获取到网页的内容,在通过xpath方法获取到ul节点,再通过ul获取到li节点,接着遍历li节点并获取li节点中的a标签中的href属性,并将该属性的值保存到数组中

三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
1 #导入模块 2 import requests 3 from lxml import html 4 etree = html.etree 5 from pandas import DataFrame 6 import os 7 8 #设置请求头 9 headers = { 10 'authority': 'www.jiaoyimao.com', 11 'method': 'GET', 12 'path': '/g5654/', 13 'scheme': 'https', 14 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 15 'accept-encoding': 'gzip, deflate, br', 16 'accept-language': 'zh-CN,zh;q=0.9', 17 'cache-control': 'no-cache', 18 'cookie': 'ssids=1573547997454633; cna=g4UwFvHgf1MCAdyiLR5UtzmI; isg=BA0NWXbxbCbzPcgKPGO5bUlKHCnjqp9j_94kEE-QE6RORiz4FzvijIefsJqFhll0; sfroms=JIAOYIMALL001; Hm_lvt_63bfdb121fda0a8a7846d5aac78f6f37=1573547999,1575375932; historyScanGame=%5B%225654%22%2Cnull%5D; sreferer=www.jiaoyimao.com; Hm_lpvt_63bfdb121fda0a8a7846d5aac78f6f37=1575418199; session=1575416854037509-21', 19 'pragma': 'no-cache', 20 'referer': 'https://www.jiaoyimao.com/g5654/', 21 'sec-fetch-mode': 'navigate', 22 'sec-fetch-site': 'none', 23 'sec-fetch-user': '?1', 24 'upgrade-insecure-requests': '1', 25 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36' 26 } 27 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'JiaoYiMao.csv') #csv文件命名 28 def get_dateil_urls(url): 29 # 获取页面内容 30 #使用requests模块的get函数向url发送一个get请求,将返回值,赋给response 31 response = requests.get(url, headers=headers) 32 #将HTTP响应内容进行解码 33 text = response.content.decode("utf-8"); 34 # 解析页面内容 35 html = etree.HTML(text) 36 #获取ul中class="list-con specialList"的ul 37 ul = html.xpath('//ul[@class="list-con specialList"]')[0] 38 #查找ul下所有的li标签 39 lis = ul.xpath('./li') 40 # 声明数组,用于存储获取到的商品链接 41 date_urls=[] 42 #遍历lis 43 for li in lis: 44 # 获取商品的详细链接 45 game_url = li.xpath('./span[@class="name"]/span[@class="is-account"]/a/@href') 46 # 将lis中的数据取出,以字符串的形式覆盖原来的game_url 47 game_url = game_url[0] 48 #将game_url加入到date_urls中 49 date_urls.append(game_url) 50 return date_urls 51 52 53 54 def main(): 55 #循环遍历前三页的数据 56 page=50 57 for i in range(page): 58 #设置目标url 59 url = "https://www.jiaoyimao.com/g5654/r1-n"+str(i)+".html" 60 #调用函数,获取页面内容,并解析页面 61 #get_dateil_urls(url)不为空则将值赋给date_urls 62 if(get_dateil_urls(url)): 63 date_urls =get_dateil_urls(url) 64 #遍历获取到的链接 65 for data_url in date_urls: 66 Subordinat_game={} #创建字典,用于存入数据 67 # 使用requests模块的get函数向url发送一个get请求,并设置请求头,将返回值赋给response 68 response = requests.get(data_url, headers=headers) 69 text = response.content.decode("utf-8") 70 html = etree.HTML(text) 71 #查找html->div[class=goods-properties]->p[class=row] 72 title=html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 73 #用于提取标签嵌套标签的内容,并去掉空格 74 LOLsystem = title[0].xpath('string()').strip()#获取操作系统 75 #截取标签内容的第153到156位 76 LOLsystem = LOLsystem[153:156] 77 #对获取到的数据进行切片 78 # game_grade = title[2].xpath('string()').strip()[5:] # 获取游戏等级 79 game_price=html.xpath('//div[@class="row"]/span[@class="price"]/text()')[0]#获取价格 80 #html->div->p->span[class=title]的标签内容 81 istext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]/span[@class="title"]/text()') 82 #每次循环都判断”精粹数量:“是否属于istext中的 83 # 判断成立 84 #获取精粹数量 85 if ('精粹数量:' in istext): 86 #获取'精粹数量:'在istext中的位置 87 index = istext.index("精粹数量:") 88 #获取istext的上一级标签 89 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 90 #通过下标索引找到'精粹数量:'在该intext中的位置,并返回内容,进行切片 91 game_money=intext[index].xpath('string()').strip()[5:] 92 #防止英文逗号在csv中被默认为单元格的分隔 93 game_money=game_money.replace(r',',',') 94 else: 95 #'精粹数量:'不在该istext中,则设置为null 96 game_money='null' 97 #获取皮肤数量 98 if("皮肤数量:" in istext): 99 index=istext.index("皮肤数量:") 100 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 101 game_skincount = intext[index].xpath('string()').strip()[5:] 102 else: 103 game_skincount ='null' 104 #获取账号等级或角色等级 105 if("帐号等级:" in istext or "角色等级:" in istext): 106 if("帐号等级:" in istext): 107 index =istext.index('帐号等级:') 108 if("角色等级:" in istext): 109 index = istext.index('角色等级:') 110 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 111 game_grade = intext[index].xpath('string()').strip()[5:] 112 else: 113 game_grade='null' 114 #获取游戏段位 115 if("段位:" not in istext): 116 game_grading='null' 117 if("段位:" in istext): 118 index = istext.index('段位:') 119 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 120 game_grading = intext[index].xpath('string()').strip()[3:] 121 # 获取英雄数量 122 if('英雄数量:' in istext): 123 index=istext.index('英雄数量:') 124 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 125 game_herocount=intext[index].xpath('string()').strip()[5:] 126 if('英雄数量:' not in istext): 127 game_herocount='null' 128 #获取角色昵称 129 if('角色昵称:' in istext): 130 index = istext.index('角色昵称:') 131 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 132 game_username = intext[index].xpath('string()').strip()[5:] 133 else: 134 game_username='null' 135 #获取账号认证 136 if('帐号认证:' in istext): 137 index = istext.index('帐号认证:') 138 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 139 game_authentication = intext[index].xpath('string()').strip()[5:] 140 else: 141 game_authentication='null' 142 #获取是否绑定成长守护平台 143 if ('是否绑定成长守护平台:' in istext): 144 index = istext.index('是否绑定成长守护平台:') 145 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 146 game_Guardian = intext[index].xpath('string()').strip()[11:] 147 else: 148 game_Guardian = 'null' 149 #获取完成时间 150 if ('完成时间:' in istext): 151 index = istext.index('完成时间:') 152 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 153 game_finish = intext[index].xpath('string()').strip()[5:] 154 else: 155 game_finish = 'null' 156 #获取商家在线 157 if ('商家在线:' in istext): 158 index = istext.index('商家在线:') 159 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 160 game_online = intext[index].xpath('string()').strip()[5:] 161 else: 162 game_online = 'null' 163 #获取描述 164 if ('描述:' in istext): 165 index = istext.index('描述:') 166 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 167 game_describe = intext[index].xpath('string()').strip()[3:] 168 # 防止英文逗号在csv中被默认为单元格的分隔 169 game_describe=game_describe.replace(r',',',') 170 else: 171 game_describe = 'null' 172 game_name=html.xpath('//div[@class="goods-properties"]/p[@class="row"]/a/text()')[0] #游戏名称 173 game_client=html.xpath('//div[@class="goods-properties"]/p[@class="row"]/a/text()')[1] #游戏客户端 174 game_district=html.xpath('//div[@class="goods-properties"]/p[@class="row"]/a/text()')[2] #游戏区服 175 game_type=html.xpath('//div[@class="goods-properties"]/p[@class="row"]/a/text()')[3] #游戏商品类型 176 #将各个内容存入到字典中 177 Subordinat_game['操作系统']=LOLsystem 178 Subordinat_game['游戏名称']=game_name 179 Subordinat_game['游戏客户端'] = game_client 180 Subordinat_game['游戏区服'] = game_district 181 Subordinat_game['价格']=game_price 182 Subordinat_game['游戏商品类型'] = game_type 183 Subordinat_game['游戏等级']=game_grade 184 Subordinat_game['英雄个数']=game_herocount 185 Subordinat_game['段位']=game_grading 186 Subordinat_game['皮肤']=game_skincount 187 Subordinat_game['精粹数量']=game_money 188 Subordinat_game['角色昵称'] = game_username 189 Subordinat_game['账号认证']=game_authentication 190 Subordinat_game['是否绑定成长守护平台']=game_Guardian 191 Subordinat_game['完成时间'] = game_finish 192 Subordinat_game['商家在线']=game_online 193 Subordinat_game['描述']=game_describe 194 print(Subordinat_game) 195 # # 保存数据 196 df = DataFrame(Subordinat_game, index=[0]) 197 if os.path.exists(file_path): 198 # 字符编码采用utf-8 199 df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") # 写入数据 200 else: 201 df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig") 202 203 204 if __name__ == '__main__': 205 main()

2.对数据进行清洗和处理
2.1导包并读取前5行
1 import pandas as pd 2 jiaoyimao=pd.DataFrame(pd.read_csv('E:/Python/代码存放/JiaoYiMao.csv')) 3 jiaoyimao.head()

2.2删除无效行
1 jiaoyimao.drop("是否绑定成长守护平台",axis=1,inplace=True) 2 jiaoyimao.head()

2.3重复值处理
1 jiaoyimao.duplicated()

1 jiaoyimao=jiaoyimao.drop_duplicates() 2 jiaoyimao.duplicated()

2.4空值与缺失值的处理
1 jiaoyimao["段位"].isnull().value_counts()

1 jiaoyimao["段位"]=jiaoyimao["段位"].fillna("未填写") 2 jiaoyimao.head()

2.5异常值处理
1 jiaoyimao.describe()

假设0.000000是异常值,将异常值替换为测试的数量
1 jiaoyimao.replace([0.000000],jiaoyimao["皮肤"].count())
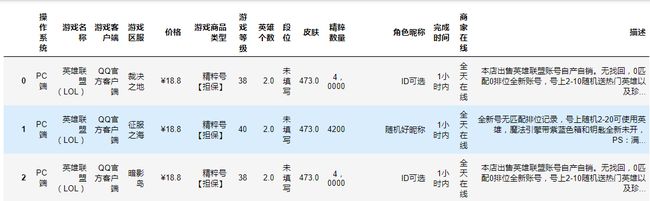
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
因为价格列的数据类型为str类型,所以先将"¥"去掉,在将数据类型转换为float类型
1 jiaoyimao["价格"]=jiaoyimao["价格"].str.replace("¥","") 2 jiaoyimao["价格"]=jiaoyimao["价格"].astype(float)
4.1分析价格与游戏等级之间的关系
1 import seaborn as sns 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 df=pd.read_csv('E:/Python/代码存放/JiaoYiMao.csv') 5 plt.rcParams['font.sans-serif']=['SimHei'] 6 plt.rcParams['axes.unicode_minus'] = False 7 sns.regplot(jiaoyimao["价格"],jiaoyimao["游戏等级"])

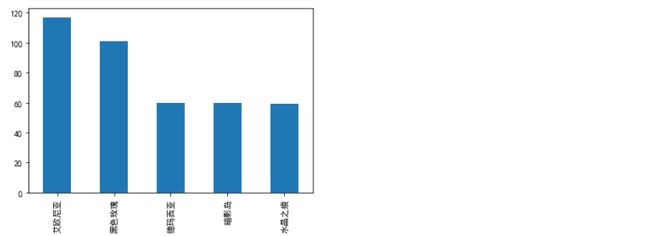
4.2分析数据游戏区服卖号数前五区服
1 jiaoyimao["游戏区服"].value_counts() #获取游戏区服的卖号数量

1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 s=pd.Series([117,101,60,60,59],["艾欧尼亚","黑色玫瑰","德玛西亚","暗影岛","水晶之痕"]) 5 s.plot(kind="bar") 6 plt.show()
4.3分析价格与皮肤之间的关系
1 plt.rcParams['font.sans-serif']=['SimHei'] 2 plt.rcParams['axes.unicode_minus'] = False 3 sns.regplot(jiaoyimao["价格"],jiaoyimao["皮肤"])
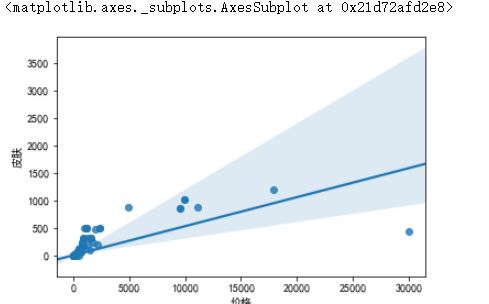
4.4分析价格与游戏等级之间的关系
1 plt.scatter(jiaoyimao["价格"],jiaoyimao["英雄个数"])
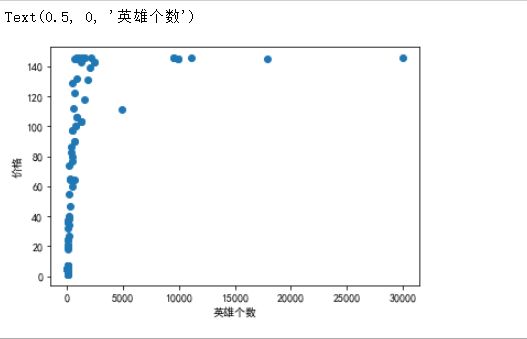
4.5分析价格小于100数据分布
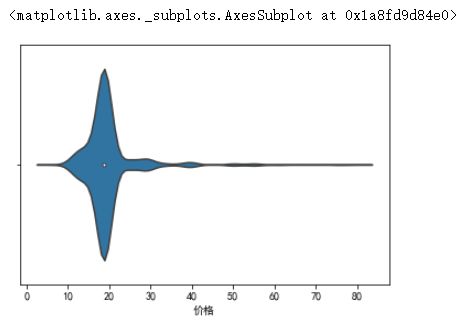
1 sns.violinplot(jiaoyimao[jiaoyimao["价格"]<=100]['价格'])
1 jiaoyimao["价格"].quantile(np.arange(0,1,0.1))

5.数据持久化
6 完整程序代码
1 #导入模块 2 import requests 3 from lxml import html 4 etree = html.etree 5 from pandas import DataFrame 6 import os 7 8 #设置请求头 9 headers = { 10 'authority': 'www.jiaoyimao.com', 11 'method': 'GET', 12 'path': '/g5654/', 13 'scheme': 'https', 14 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 15 'accept-encoding': 'gzip, deflate, br', 16 'accept-language': 'zh-CN,zh;q=0.9', 17 'cache-control': 'no-cache', 18 'cookie': 'ssids=1573547997454633; cna=g4UwFvHgf1MCAdyiLR5UtzmI; isg=BA0NWXbxbCbzPcgKPGO5bUlKHCnjqp9j_94kEE-QE6RORiz4FzvijIefsJqFhll0; sfroms=JIAOYIMALL001; Hm_lvt_63bfdb121fda0a8a7846d5aac78f6f37=1573547999,1575375932; historyScanGame=%5B%225654%22%2Cnull%5D; sreferer=www.jiaoyimao.com; Hm_lpvt_63bfdb121fda0a8a7846d5aac78f6f37=1575418199; session=1575416854037509-21', 19 'pragma': 'no-cache', 20 'referer': 'https://www.jiaoyimao.com/g5654/', 21 'sec-fetch-mode': 'navigate', 22 'sec-fetch-site': 'none', 23 'sec-fetch-user': '?1', 24 'upgrade-insecure-requests': '1', 25 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36' 26 } 27 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'JiaoYiMao.csv') #csv文件命名 28 def get_dateil_urls(url): 29 # 获取页面内容 30 #使用requests模块的get函数向url发送一个get请求,将返回值,赋给response 31 response = requests.get(url, headers=headers) 32 #将HTTP响应内容进行解码 33 text = response.content.decode("utf-8"); 34 # 解析页面内容 35 html = etree.HTML(text) 36 #获取ul中class="list-con specialList"的ul 37 ul = html.xpath('//ul[@class="list-con specialList"]')[0] 38 #查找ul下所有的li标签 39 lis = ul.xpath('./li') 40 # 声明数组,用于存储获取到的商品链接 41 date_urls=[] 42 #遍历lis 43 for li in lis: 44 # 获取商品的详细链接 45 game_url = li.xpath('./span[@class="name"]/span[@class="is-account"]/a/@href') 46 # 将lis中的数据取出,以字符串的形式覆盖原来的game_url 47 game_url = game_url[0] 48 #将game_url加入到date_urls中 49 date_urls.append(game_url) 50 return date_urls 51 52 53 54 def main(): 55 #循环遍历前三页的数据 56 page=50 57 for i in range(page): 58 #设置目标url 59 url = "https://www.jiaoyimao.com/g5654/r1-n"+str(i)+".html" 60 #调用函数,获取页面内容,并解析页面 61 #get_dateil_urls(url)不为空则将值赋给date_urls 62 if(get_dateil_urls(url)): 63 date_urls =get_dateil_urls(url) 64 #遍历获取到的链接 65 for data_url in date_urls: 66 Subordinat_game={} #创建字典,用于存入数据 67 # 使用requests模块的get函数向url发送一个get请求,并设置请求头,将返回值赋给response 68 response = requests.get(data_url, headers=headers) 69 text = response.content.decode("utf-8") 70 html = etree.HTML(text) 71 #查找html->div[class=goods-properties]->p[class=row] 72 title=html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 73 #用于提取标签嵌套标签的内容,并去掉空格 74 LOLsystem = title[0].xpath('string()').strip()#获取操作系统 75 #截取标签内容的第153到156位 76 LOLsystem = LOLsystem[153:156] 77 #对获取到的数据进行切片 78 # game_grade = title[2].xpath('string()').strip()[5:] # 获取游戏等级 79 game_price=html.xpath('//div[@class="row"]/span[@class="price"]/text()')[0]#获取价格 80 #html->div->p->span[class=title]的标签内容 81 istext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]/span[@class="title"]/text()') 82 #每次循环都判断”精粹数量:“是否属于istext中的 83 # 判断成立 84 #获取精粹数量 85 if ('精粹数量:' in istext): 86 #获取'精粹数量:'在istext中的位置 87 index = istext.index("精粹数量:") 88 #获取istext的上一级标签 89 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 90 #通过下标索引找到'精粹数量:'在该intext中的位置,并返回内容,进行切片 91 game_money=intext[index].xpath('string()').strip()[5:] 92 #防止英文逗号在csv中被默认为单元格的分隔 93 game_money=game_money.replace(r',',',') 94 else: 95 #'精粹数量:'不在该istext中,则设置为null 96 game_money='null' 97 #获取皮肤数量 98 if("皮肤数量:" in istext): 99 index=istext.index("皮肤数量:") 100 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 101 game_skincount = intext[index].xpath('string()').strip()[5:] 102 else: 103 game_skincount ='null' 104 #获取账号等级或角色等级 105 if("帐号等级:" in istext or "角色等级:" in istext): 106 if("帐号等级:" in istext): 107 index =istext.index('帐号等级:') 108 if("角色等级:" in istext): 109 index = istext.index('角色等级:') 110 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 111 game_grade = intext[index].xpath('string()').strip()[5:] 112 else: 113 game_grade='null' 114 #获取游戏段位 115 if("段位:" not in istext): 116 game_grading='null' 117 if("段位:" in istext): 118 index = istext.index('段位:') 119 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 120 game_grading = intext[index].xpath('string()').strip()[3:] 121 # 获取英雄数量 122 if('英雄数量:' in istext): 123 index=istext.index('英雄数量:') 124 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 125 game_herocount=intext[index].xpath('string()').strip()[5:] 126 if('英雄数量:' not in istext): 127 game_herocount='null' 128 #获取角色昵称 129 if('角色昵称:' in istext): 130 index = istext.index('角色昵称:') 131 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 132 game_username = intext[index].xpath('string()').strip()[5:] 133 else: 134 game_username='null' 135 #获取账号认证 136 if('帐号认证:' in istext): 137 index = istext.index('帐号认证:') 138 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 139 game_authentication = intext[index].xpath('string()').strip()[5:] 140 else: 141 game_authentication='null' 142 #获取是否绑定成长守护平台 143 if ('是否绑定成长守护平台:' in istext): 144 index = istext.index('是否绑定成长守护平台:') 145 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 146 game_Guardian = intext[index].xpath('string()').strip()[11:] 147 else: 148 game_Guardian = 'null' 149 #获取完成时间 150 if ('完成时间:' in istext): 151 index = istext.index('完成时间:') 152 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 153 game_finish = intext[index].xpath('string()').strip()[5:] 154 else: 155 game_finish = 'null' 156 #获取商家在线 157 if ('商家在线:' in istext): 158 index = istext.index('商家在线:') 159 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 160 game_online = intext[index].xpath('string()').strip()[5:] 161 else: 162 game_online = 'null' 163 #获取描述 164 if ('描述:' in istext): 165 index = istext.index('描述:') 166 intext = html.xpath('//div[@class="goods-properties"]/p[@class="row"]') 167 game_describe = intext[index].xpath('string()').strip()[3:] 168 # 防止英文逗号在csv中被默认为单元格的分隔 169 game_describe=game_describe.replace(r',',',') 170 else: 171 game_describe = 'null' 172 game_name=html.xpath('//div[@class="goods-properties"]/p[@class="row"]/a/text()')[0] #游戏名称 173 game_client=html.xpath('//div[@class="goods-properties"]/p[@class="row"]/a/text()')[1] #游戏客户端 174 game_district=html.xpath('//div[@class="goods-properties"]/p[@class="row"]/a/text()')[2] #游戏区服 175 game_type=html.xpath('//div[@class="goods-properties"]/p[@class="row"]/a/text()')[3] #游戏商品类型 176 #将各个内容存入到字典中 177 Subordinat_game['操作系统']=LOLsystem 178 Subordinat_game['游戏名称']=game_name 179 Subordinat_game['游戏客户端'] = game_client 180 Subordinat_game['游戏区服'] = game_district 181 Subordinat_game['价格']=game_price 182 Subordinat_game['游戏商品类型'] = game_type 183 Subordinat_game['游戏等级']=game_grade 184 Subordinat_game['英雄个数']=game_herocount 185 Subordinat_game['段位']=game_grading 186 Subordinat_game['皮肤']=game_skincount 187 Subordinat_game['精粹数量']=game_money 188 Subordinat_game['角色昵称'] = game_username 189 Subordinat_game['账号认证']=game_authentication 190 Subordinat_game['是否绑定成长守护平台']=game_Guardian 191 Subordinat_game['完成时间'] = game_finish 192 Subordinat_game['商家在线']=game_online 193 Subordinat_game['描述']=game_describe 194 print(Subordinat_game) 195 # # 保存数据 196 df = DataFrame(Subordinat_game, index=[0]) 197 if os.path.exists(file_path): 198 # 字符编码采用utf-8 199 df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") # 写入数据 200 else: 201 df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig") 202 203 204 if __name__ == '__main__': 205 main()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1、游戏等级越高价格越贵,但是存在部分异常值
2、卖号的人数艾欧尼亚较多
3、皮肤数量越多,价格越贵,但是存在部分异常值
4、物品价格分布偏左,80%物品售价为0~19之间,90%商品在29以内,说明该平台上的账号普遍卖得比较便宜
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次的爬虫我对使用xpath爬取网页数据的流程有了一定的了解,让我发现自己的不足之处,也增加了我对爬虫的兴趣。巩固了老师所传授的 知识,加深了自己的编程能力。希望后期能对Python学习能更进一步。