一、介绍
决策树(Decision Tree)是一个树结构(可以是二叉树或非二叉树),其中每个非叶节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。
决策树最重要的是决策树的构造。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
决策树的属性分裂选择是”贪心“算法,也就是没有回溯的。
二、原理
2.1 信息熵
1948年,香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。信息熵这个词是C.E.香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。
由于信息的冗余性,冗余大小与信息中每个符号(数字、字母或单词)的出现概率或者说不确定性有关。比如:问明天股票涨还是跌;回答:明天NBA决赛,这两者似乎没有什么联系,所以你的信息量很少。但是回答:因为明天大家都去看NBA决赛,没人坐庄导致股票大跌。因为你的回答使不确定变得很确定,包含的信息量也就很大。有些事情本来就很确定了,例如太阳从东边升起,你说一百遍,也没有丝毫信息量,因为这件事情确定的不能确定了。所以说信息量的大小跟事情不确定性的变化有关。
信息熵的三大性质:
单调性,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。
非负性,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑的。
累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和,两个事件相互独立有,信息熵H(A,B)=H(A)+H(B);如果两个事件不相互独立,那么满足H(A,B)=H(A)+H(B)-I(A,B) ,其中I(A,B) 是互信息(mutual information),代表一个随机变量包含另一个随机变量信息量的度量。
那么,不确定性的变化跟什么有关呢?
一,跟事情的可能结果的数量有关;二,跟概率有关。
一个事件的信息量就是这个事件发生的概率的负对数。信息熵是跟所有可能性有关系的。每个可能事件的发生都有个概率。信息熵就是平均而言发生一个事件我们得到的信息量大小(也就是说信息熵代表某元组标号所需的平均信息量)。所以数学上,信息熵其实是信息量的期望。
信息熵数学表达式,如图2-1所示:Ent(D)的值越小,则D的纯度越高
信息增益: 假定离散属性a有V个可能的取值{a1,a2,a3,...,av},若用a来对样本集D进行划分,则会产生V个分支结点,其中第V个分支结点包含D中所有属性a上取值为av的样本,记作DV。数学表达式如图2-2所示:
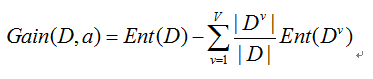
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。
2.2 ID3.5决策树
通过上述介绍,我们知道了信息熵和决策树构造过程是一个提纯的过程,根据信息熵来判断我们决策树构造方向。熵的变化可以被看做是信息增益,决策树ID3算法的核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行划分。
从信息论知识中我们知道,期望信息越小,信息增益越大,从而纯度越高。“纯”就是尽量让一个划分子集中待分类项属于同一类别。
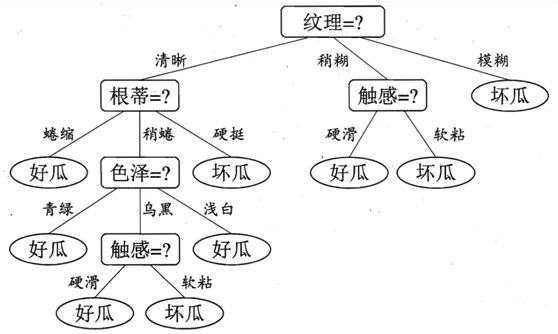
举一个选瓜的例子(周志华《机器学习》),数据如图2-3所示:

正例(好瓜)占 8/17,反例占 9/17 ,根结点的信息熵为,如图2-4所示:
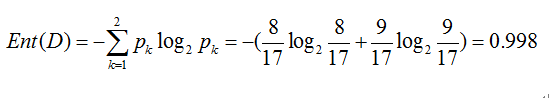
根据数据表可知,特征有色泽、根蒂、敲声、纹理、脐部、触感等六个特征。我们需要计算每个属性的信息增益,以此最大程度的“提纯”。
首先计算“色泽”,共3个子集{青绿,乌黑,浅白},D1(青绿)={1,4,6,10,13,17},D2(乌黑)={2,3,7,8,9,15},D3(浅白)={5,11,12,14,16}。D1(青绿)集合中正例p1=3/6,反例p2=3/6。D2(乌黑)集合正例 p1=4/6,反例p2=2/6。D3(浅白)集合正例 p1=1/5,反例p2=4/5。计算过程如2-5所示:

根据色泽三个子集的信息熵即可计算出,“色泽”属性的信息增益,如图2-6所示:
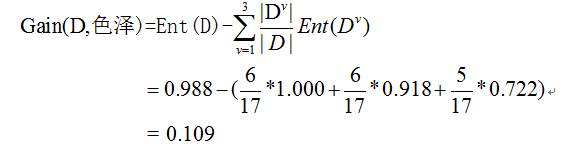
同理,我们计算出其他属性信息增益:Gain(D,根蒂)=0.143;Gain(D,敲声)=0.141
Gain(D,纹理)=0.381;Gain(D,脐部)=0.289;Gain(D,触感)=0.006
根据之前“提纯”的原则,我们选择信息增益最大作为第一个分支节点。划分如图2-7所示:
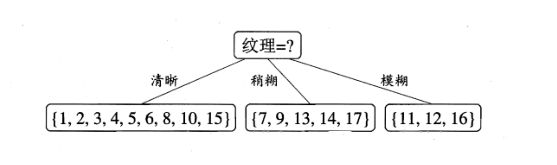
根据纹理划分成3个子集,接下来要对每一个子集进行下一步划分,D1(纹理清晰)={1,2,3,4,5,6,8,10,15},D2(纹理模糊)={7,9,13,14,17},D3(纹理模糊)={11,12,16}。因为D3子集中类别全是坏瓜,所以不需要再做划分。剩下的属性集合{色泽,根蒂,敲声,脐部,触感},计算D1各属性信息增益:
Gain(D1,色泽)=0.043; Gain(D1,根蒂)=0.458; Gain(D1,敲声)=0.331; Gain(D1,脐部)=0.458; Gain(D1,触感)=0.458
根据“提纯”原则,我们继续划分可以任意选择根蒂,脐部,触感三个属性其中一个为划分结点,经过多次划分至只剩单一类别后,得到决策树图2-3所示:
2.3 C4.5决策树
ID3.5使用信息增益作为“提纯”方法,但实际上,信息增益对可取数目较多的属性有所偏好,所以为了减少这种影响,提出用增益率来选择最优划分,也就是C4.5决策树算法。
增益率定义,如图2-9所示: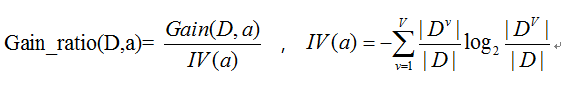
可以从式中看出数目越多(V越大),IV(a)会越大,Gain_ratio越小,所以增益率对可取数目较少的属性有所偏好。因此C4.5并不是直接选取增益率最高的,而是先从划分属性从选取信息增益高于平均水平的属性,再从中选择信息增益率最高的最为划分结点。
2.4 CART决策树
CART决策树使用“基尼指数”(Gini index)来划分属性。数据集D纯度使用基尼值来度量,如图2-10所示:
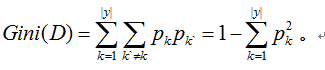
Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此,Gini(D)越小,则数据集D的纯度越高。
属性a的基尼指数定义,如图2-11所示:
于是我们在候选属性集合中选择基尼指数最小的属性作为最优划分属性。
2.5 剪枝处理
剪枝处理是为了解决决策树分支过多而产生的“过拟合”问题。剪枝策略有“预剪枝”和“后剪枝”。
“预剪枝”是决策树生成时,计算并比较每个结点划分前和划分后的验证集精度,若划分前的结点精度要比划分后高,则剪枝。反之则确认划分此结点
“后剪枝”是决策树生成后,自底向上进行计算剪枝前和剪枝后的验证集精度。若剪枝后比剪枝前的结点精度要高则剪枝,反之保留。
优缺点:
“预剪枝”:由于一边划分结点的同时一边计算精度来决定是否剪枝,所以“预剪枝”可以很有效的减少决策树训练时间开销和测试时间开销。但由于很多分支还未完成展开并剪去,基于“贪心”本质也很容易忽略后续优秀的分支,导致欠拟合风险。
“后剪枝”:由于需要完全生成一颗决策树后再进行计算剪枝,导致时间开销的增加,但是欠拟合的风险很小。
2.6 连续值处理
当数据集中出现了连续属性如何使用决策树进行划分结点?由于连续属性相对于离散属性可取数目不是有限的,所以不能直接根据连续属性可选值进行划分。
最简单的策略使用二分法:
样本集D中有连续属性a,我们先进行排序{a1,a2,a3....,an}。划分时,以任意t为例,有1<=t<=n-1,
,即把区间[ai,ai+1)的中位点
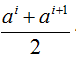
作为候选点。然后即可像考虑离散属性值一样考虑这些划分点:

Gain(D,a,t)是样本集基于划分点t二分后的信息增益,我们选择Gain(D,a,t)最大的为划分点。
2.7 缺失值处理
当遇到样本中某属性的值缺失的情况下如何进行划分属性选择?
我们假设样本集D和属性a,用D~ 表示在D中属性a上没有缺失的样本子集,D+表示在D中属性a上表示的正类,D-表示在D中属性a上的负类(假设二分类问题)。k表示属性a中类别。我们可以用p表示无缺失值样本所占的比例,pk+表示无缺失值样本中第k类正例在第k类中所占的比例,Pk-表示无缺失值样本中第k类负例在第k类中所占的比例,r表示无缺失值样本中第k类在属性a中无缺失样本子集D~所占比例。定义如图2-15 所示:
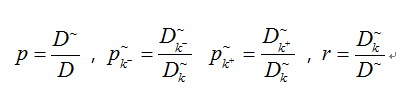
基于上述定义,我们可将信息增益计算公式推广,如图2-16所示:

例:有下列有缺失的西瓜数据集,如图2-17所示:
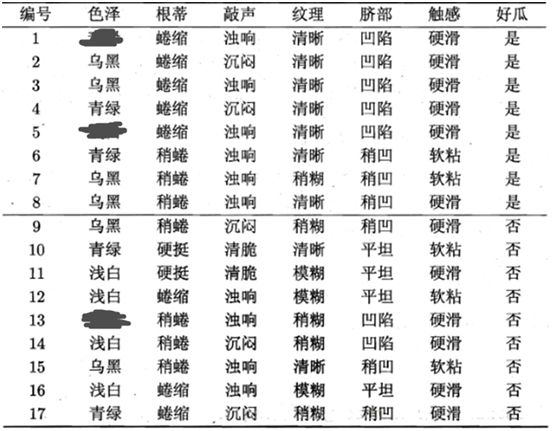
我们以色泽为例来计算色泽属性下各类别的信息增益,以此作为结点划分依据。
样本集D中有17个样例,色泽属性中无缺失的样例子集D~编号有{2,3,4,6,7,8,9,10,11,12,14,15,16,17}。
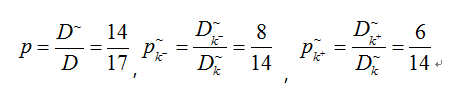
D~信息熵,计算如图2-20所示:

样本集属性为色泽的信息增益为:

然后计算出其它所有属性在D中的信息增益。选择信息增益最大的为最佳划分结点
三、代码实现
3.1 决策树构建流程
-
- 遍历并评估每个特征
-
- 判断是否某个分支下的数据属于同一类型,如果是则返回作为标签,否之继续。
-
- 寻找划分数据集的最好特征
-
- 划分数据集
-
- 创建分支节点
- 递归调用创建新的分支节点函数createBranch
3.2构建决策树预测隐形眼镜类型
参考《机器学习实战》第三章Logistic回归样例:使用决策树预测隐形眼镜类型
预测隐形眼镜训练集样本如图3-1所示:

根据特征划分数据集,这样可以依次计算出各属性的信息增益,以此对比选择最好的划分节点。代码如图3-2所示

计算给定数据集的信息熵,代码如图3-3所示:

8 ~ 12行代码统计了给定样本集分类结果的各占的数量,14~16行计算出样本信息熵 图3-4
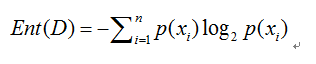
计算出信息熵后,接下来要计算每个属性的信息增益,等到信息增益最大的属性,代码如图3-5所示:
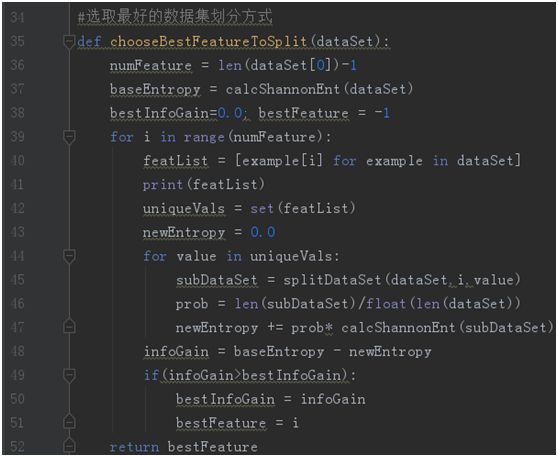
39 ~ 51行遍历属性a中总共有v个可能的值,计算{a1,a2,......,av}各自信息熵和信息增益,并筛选出最大的信息增益,计算信息增益表达式如图3-6所示:

当程序遍历完所有划分数据集的属性或者每个分支所有实例都具有相同的分类,那么就可以结束算法。但是很多情况特征数目并不是每次划分数据分组的时候都减少,如C4.5和CART算法,因此我们可以设置算法划分的一个最大分组数目作为结束分支的阈值。而且如果数据集已处理完了所有属性,但是类标签依然不是唯一的,我们通常会选取分类最多的最为该节点分类。代码如图3-7所示:

最后构建整个决策树的代码如图3-8所示:
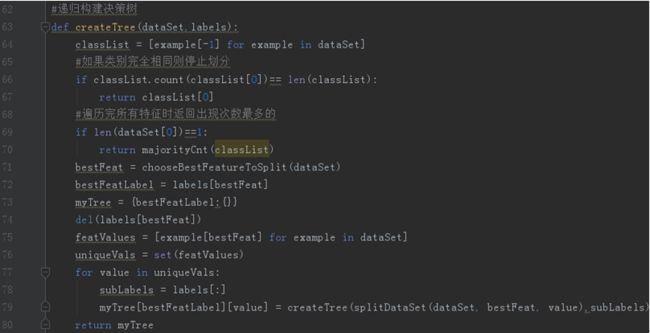
66行~67行,判断类别是否都完全相同,相同则返回此类别结束。
69~70行,判断是否遍历完了所有特征,是则选择属性分类最多的最后的节点。
71~72行,选择最好的划分子节点,获取其标签。
74~79行,将已划分节点的类别从数据集中划分出来,再用数据集剩下的子集划分子树。
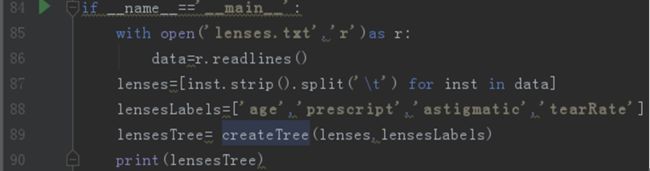
最后导入数据集,得出结果,代码如图3-9所示:
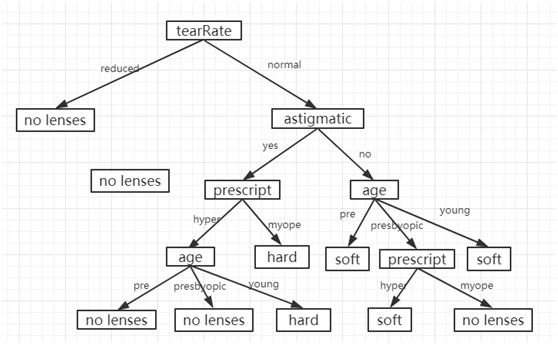
结果树状图如图3-10所示:
四、总结
本章主要介绍了ID3、C4.5、CART决策树算法计算信息的增益、信息增益率、基尼不纯度等方法来度量数据集的无序程度,简单来说就是从一个数据集中随机选取子项,度量其被错误分类到其他分组里的概率。通过这些决策树算法我们能够根据实际情况正确的划分数据集,但是为了避免过拟合问题,又有了前剪枝和后剪枝。对非离散的数据集和缺失的数据集又有合理的解决方案。
决策树优点:
决策树易于理解和实现,它能够直接体现数据的特点,而不需要使用者了解更多的背景知识
数据的准备可以很简单或者是不必要的,而且能够同时处理数据型和常规型属性,在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
易于通过静态测试来对模型进行评测,可以测定模型可信度;如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式
决策树缺点:
对连续性的字段比较难预测。
对有时间顺序的数据,需要很多预处理的工作。
当类别太多时,错误可能就会增加的比较快。
一般的算法分类的时候,只是根据一个字段来分类。
如果您喜欢我的文章,请关注或点击喜欢,您的支持是我最大的动力 ^ ^~!
欢迎指出问题,一起讨论,共同进步
转载请注明作者及其出处
黑羊的皇冠 主页