在之前的一篇文章中,我们解释了一下为什么下面的两种方式是不同的:
bucket = [[] for _ in range(len(nums)+1)]
bucket1 = [[]] * (len(nums) + 1)
第一种生成的bucket中每个list都是不同的list object ,而第二个bucket中的每个list都是相同的list object。为什么呢?这就涉及到Python中深浅拷贝的知识,接下来,我们就详细介绍一下。
1、Python对象赋值
我们先来看一下下面的一段代码:
will = ["Will", 28, ["Python", "C#", "JavaScript"]]
wilber = will
print id(will)
print will
print [id(ele) for ele in will]
print id(wilber)
print wilber
print [id(ele) for ele in wilber]
will[0] = "Wilber"
will[2].append("CSS")
print id(will)
print will
print [id(ele) for ele in will]
print id(wilber)
print wilber
print [id(ele) for ele in wilber]
上段代码的输出为:
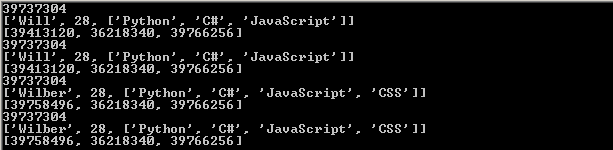
下面来分析一下这段代码:
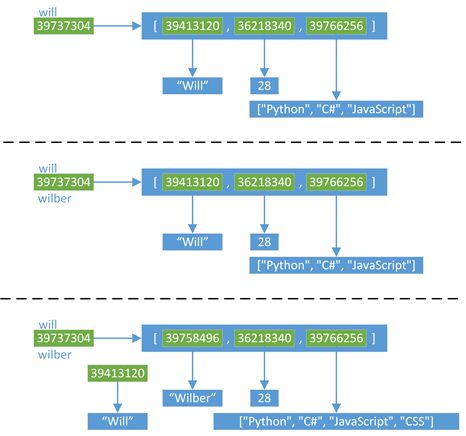
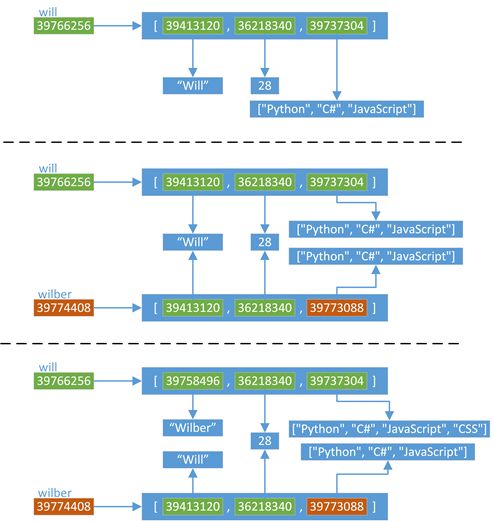
1)首先,创建了一个名为will的变量,这个变量指向一个list对象,从第一张图中可以看到所有对象的地址(每次运行,结果可能不同)
2)然后,通过will变量对wilber变量进行赋值,那么wilber变量将指向will变量对应的对象(内存地址),也就是说"wilber is will","wilber[i] is will[i]"可以理解为,Python中,对象的赋值都是进行对象引用(内存地址)传递
3)由于will和wilber指向同一个对象,所以对will的任何修改都会体现在wilber上。这里需要注意的一点是,str是不可变类型,所以当修改的时候会替换旧的对象,产生一个新的地址39758496。
上面这段代码的过程可以由下面的图进行解释:
2、Python浅拷贝
我们还是来看一个代码示例:
import copy
will = ["Will", 28, ["Python", "C#", "JavaScript"]]
wilber = copy.copy(will)
print id(will)
print will
print [id(ele) for ele in will]
print id(wilber)
print wilber
print [id(ele) for ele in wilber]
will[0] = "Wilber"
will[2].append("CSS")
print id(will)
print will
print [id(ele) for ele in will]
print id(wilber)
print wilber
print [id(ele) for ele in wilber]
这段代码的输出为:
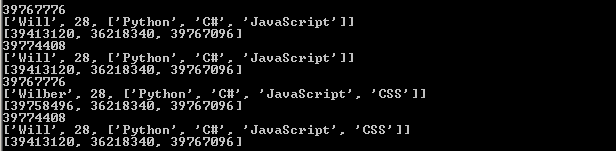
分析一下这段代码:
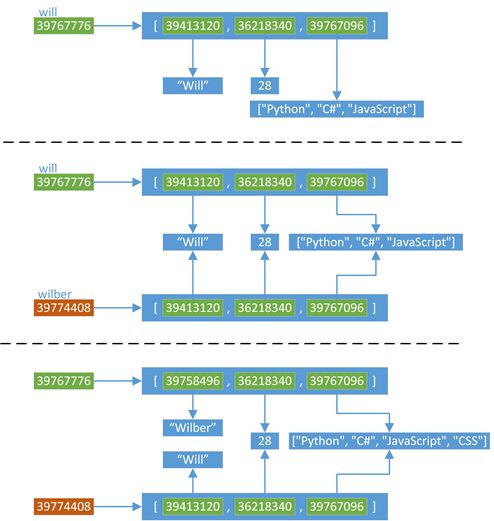
1)首先,依然使用一个will变量,指向一个list类型的对象。然后,通过copy模块里面的浅拷贝函数copy(),对will指向的对象进行浅拷贝,然后浅拷贝生成的新对象赋值给wilber变量。浅拷贝会创建一个新的对象,这个例子中"wilber is not will",但是,对于对象中的元素,浅拷贝就只会使用原始元素的引用(内存地址),也就是说"wilber[i] is will[i]"。
2)当对will进行修改的时候,由于list的第一个元素是不可变类型,所以will对应的list的第一个元素会使用一个新的对象39758496。但是list的第三个元素是一个可不类型,修改操作不会产生新的对象,所以will的修改结果会相应的反应到wilber上。
上面这段代码的过程可以由下面的图进行解释:
除了使用copy模块中的copy方法进行浅拷贝外,python中还有其他几种的浅拷贝方式:
1)使用切片[:]操作
2)使用工厂函数(如list/dir/set)
3)使用copy模块中的copy()函数
第三种方式我们已经介绍过了,通过下面的例子可以看出前两种方式也是浅拷贝:
>>> person = ["name",["savings",100.00]]
>>> hubby = person[:] #切片操作
>>> wifey = list(person) #使用工厂函数
>>> [id(x) for x in person,hubby,wifey]
[139797546486384, 139797546556592, 139797546557240]
>>> [id(x) for x in hubby]
[139797546838128, 139797546485808]
>>> [id(x) for x in wifey]
[139797546838128, 139797546485808]
>>> hubby[0] = "kel"
>>> wifey[0] = "jane"
>>> hubby[1][1] = 50.0
>>> [id(x) for x in hubby,wifey]
[139797546556592, 139797546557240]
>>> [id(x) for x in hubby]
[139797546592368, 139797546485808]
>>> [id(x) for x in wifey]
[139797546592416, 139797546485808]
>>> hubby
['kel', ['savings', 50.0]]
>>> wifey
['jane', ['savings', 50.0]]
3、Python深拷贝
最后来看看深拷贝:
import copy
will = ["Will", 28, ["Python", "C#", "JavaScript"]]
wilber = copy.deepcopy(will)
print id(will)
print will
print [id(ele) for ele in will]
print id(wilber)
print wilber
print [id(ele) for ele in wilber]
will[0] = "Wilber"
will[2].append("CSS")
print id(will)
print will
print [id(ele) for ele in will]
print id(wilber)
print wilber
print [id(ele) for ele in wilber]
代码的结果为:
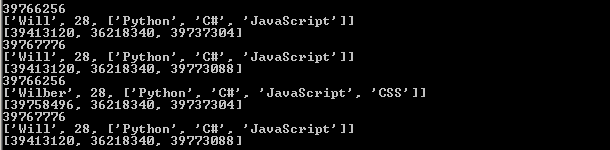
分析一下这段代码:
1)首先,同样使用一个will变量,指向一个list类型的对象
2)然后,通过copy模块里面的深拷贝函数deepcopy(),对will指向的对象进行深拷贝,然后深拷贝生成的新对象赋值给wilber变量。跟浅拷贝类似,深拷贝也会创建一个新的对象,这个例子中"wilber is not will"。但是,对于对象中的元素,深拷贝都会重新生成一份(有特殊情况,下面会说明),而不是简单的使用原始元素的引用(内存地址)。例子中will的第三个元素指向39737304,而wilber的第三个元素是一个全新的对象39773088,也就是说,"wilber[2] is not will[2]"
当对will进行修改的时候
3)由于list的第一个元素是不可变类型,所以will对应的list的第一个元素会使用一个新的对象39758496。但是list的第三个元素是一个可不类型,修改操作不会产生新的对象,但是由于"wilber[2] is not will[2]",所以will的修改不会影响wilber。
上面这段代码的过程可以由下面的图进行解释:
4、再回首
首先,我们总结一下Python中的对象赋值和深浅拷贝操作:
1)Python中对象的赋值都是进行对象引用(内存地址)传递。
2)使用copy.copy(),数组切片操作或者是使用工厂函数(如list/dir/set),可以进行对象的浅拷贝,它复制了对象,但对于对象中的元素,依然使用原始的引用。
3)如果需要复制一个容器对象,以及它里面的所有元素(包含元素的子元素),可以使用copy.deepcopy()进行深拷贝。
4)对于str等不可变类型,所以当修改的时候会替换旧的对象,产生一个新的地址。
那么对于之前提到过的例子:
bucket = [[] for _ in range(len(nums)+1)]
bucket1 = [[]] * (len(nums) + 1)
我们就可以做出如下的解释:
1)使用*进行list“复制”,其生成的新数组与被复制的数组其实是在同一段内存地址当中,这样的复制方式成为浅拷贝。
2)浅复制进行初始化的结果就是,在对复制之后的对象进行相关操作时,被复制的对象会受到同样的影响,因为他们本质是同一段list,均位于相同的地址。
3)使用for循环进行初始化,进行初始化时,相当于每循环一次就生成了一个新的list,所以在实际问题中,推荐使用这种方式。
参考文献:
图解Python深拷贝和浅拷贝:http://www.cnblogs.com/wilber2013/p/4645353.html
python中的深拷贝与浅拷贝:
http://www.cnblogs.com/kellyseeme/p/5525067.html
python list的深拷贝与浅拷贝-以及初始化空白list的方法(1):
http://www.cnblogs.com/koliverpool/p/6789854.html