一:组件
1、hadoop(包含了yarn和hdfs),hadoop 2.8.5版本
2、flink,版本 flink-1.7.2-bin-hadoop28-scala_2.11.tgz
3、centos7
二:步骤。
1、自行安装hadoop集群,很多帖子,随意找。
1)关于配置 core-site.xml
2)关于配置hadoop-env.sh
export JAVA_HOME=/data/soft/jdk1.8.0_181
3)关于配置hdfs-site.xml
4)关于配置mapred-env.sh
export JAVA_HOME=/data/soft/jdk1.8.0_181
5)关于配置 mapred-site.xml
mapred-site.xml文件默认是没有的,需要cp mapred-site.xml.template mapred-site.xml
报错如下:
Diagnostics: Container [pid=16377,containerID=container_1533988876407_0004_02_000001] is running beyond virtual memory limits. Current usage: 59.9 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.
6)关于配置slaves(此时把master也当做一个slave了)
vim slaves
master
slave1
slave2
7)关于配置 yarn-site.xml
注:日志聚集功能不配置

这点点进去会报错。
三:flink部署
下载flink包
1)配置flink-conf.yaml
#Jobmanager的IP地址,即master地址。
jobmanager.rpc.address: master
#每一个TaskManager的堆大小(单位是MB),由于每个taskmanager要运行operator的各种函数(Map、Reduce、CoGroup等,包含sorting、hashing、caching),因此这个值应该尽可能的大。如果集群仅仅跑Flink的程序,建议此值等于机器的内存大小减去1、2G,剩余的1、2GB用于操作系统。如果是Yarn模式,这个值通过指定tm参数来分配给container,同样要减去操作系统可以容忍的大小(1、2GB)。
#本地方设置6G
taskmanager.heap.size: 6144
#每个TaskManager的并行度。一个slot对应一个core,默认值是1.一个并行度对应一个线程。总的内存大小要且分给不同的线程使用。
taskmanager.numberOfTaskSlots: 4
#启动job默认用的parallelism数量
parallelism.default:8
#临时目录
taskmanager.tmp.dirs: /tmp
#JobManager的堆大小(单位是MB)。当长时间运行operator非常多的程序时,需要增加此值。具体设置多少只能通过测试不断调整。
jobmanager.heap.size: 2048
#jobmanager.web.port: 8081
#JobMamanger的端口,默认是6123。
jobmanager.rpc.port: 6123
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs:///flink/checkpoints
fs.hdfs.hadoopconf: /var/apps/hadoop285/etc/hadoop
注:如果配置高可用,这里面少了zookeeper的配置
2)配置master
vim masters
master:8081
3)配置slaves
vim slaves
slave1
slave2
三:启动yarn 和flink
四:提交任务。
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -d -c com.xxxxx.flink.app.xxxxxFlinkData /var/apps/xxxx-xxxxx.jar
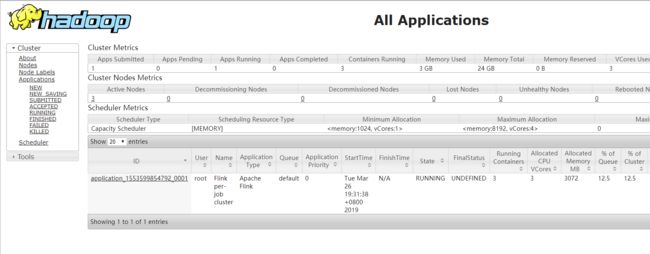
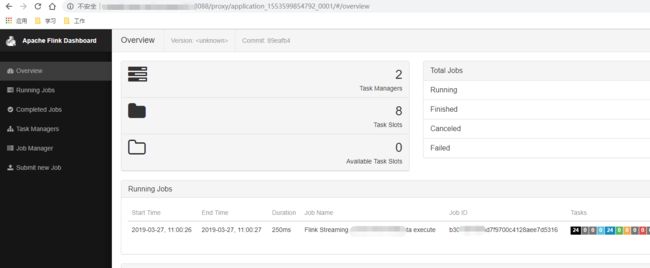
页面如下:
完成!