Google Creative Lab发布了基于TensorFlow.js的PoseNet模型。
TensorFlow.js:https://js.tensorflow.org/
PoseNet:https://github.com/tensorflow/tfjs-models/tree/master/posenet
Demo:https://storage.googleapis.com/tfjs-models/demos/posenet/camera.html
先来看一看最终的实现效果:

单人姿态估计效果

多人姿态估计效果
人体姿态估计是在图像或视频中检测人物的计算机视觉技术,比如说可以确认视频中人物各个关节点的位置。这项技术并不能识别图像中的人是谁,只是简单的估计身体关键关节的位置。
这项技术的用途很广泛,例如对身体作出反应的交互式装置、增强现实、动画、健身、体育训练等。PoseNet完全开放访问,希望更多的开发人员和制造商尝试将动作检测应用到自己的项目中。虽然目前有许多姿态检测系统都是开源的,但很多都需要专门的硬件以及复杂的系统设置。PoseNet运行在Tensorflow.js上,任何拥有摄像头桌面或者手机的人都可以在浏览器中体验该技术。开发人员借助该开源模型可以实现这个技术,同时由于PoseNet是在浏览器上运行,任何关于用户行为的数据都不会被泄漏。
PoseNet入门
PoseNet可以估计单个形体或者多个形体的姿态,所以该算法有两个版本。先讲解单人姿态估计算法。
高性能的姿态跟踪分为两个阶段:
将RGB图像输入卷积神经网络;
使用单人或多人解码算法解码模型输出的动作和动作置信度,关键点位置和关键点置信度。
先回顾一些关键词的意思:
Pose——PoseNet将返回一个动作对象,其中包含关键点列表以及每个检测到的人的置信度。

PoseNet返回检测到的每个人的姿势和关键点的置信度值
姿态置信度——这确定姿态检测的总体置信度,其范围0~1,可以用来过滤不太明显的姿态。
关键点——估计形体的一部分,例如鼻子、右耳、左膝、右脚等,它包含关键点位置及其置信度。PoseNet目前检测如下图所示的17个关键点:
关键点置信度——它代表关键点位置的准确性,它的值范围在0~1,可以用来过滤不明显的关键点。
关键点位置——检测到关键点的x和y的坐标值。
第一步:导入TensorFlow.js和PoseNet库
很多工作都是抽象出模型的复杂性并将功能封装为易于使用的方法,下面来看如何设置PoseNet项目。
这库可以和npm一起安装:
使用es6模块导入:
或通过页面中的一个捆绑:
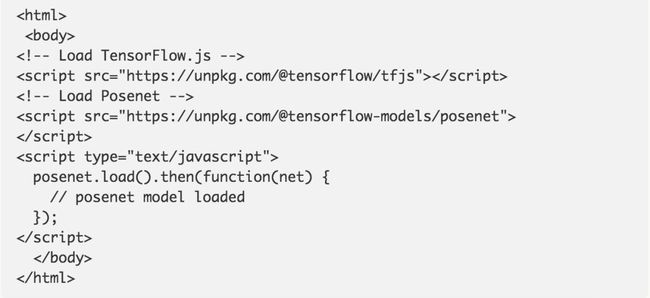
第二步:单个人物姿态估计

单个人物姿态估计算法是比较简单和快速的,理想的用例是上图中只有一个居中的人物。如果图像中有多个人,则来自两个人的关键点可能被认为是一个形体的一部分。
单姿态估计算法的输入:
输入图像——包含要检测图像的Html,例如视频或者图像标记。重要的是,图像和视频元素是方形的。
图像比例因子——介于0.2-1之间的数字,默认为0.5。在输入模型之前用来缩放图像,数字设置的越低输入图像越小,图像质量越低,模型速度越快。
水平翻转——默认为False,如果人物需要进行水平镜像,就设置为ture。
输出步长——这个数值必须是32、16或者8.默认值为16,在内部此参数影响神经网络中特征图的高度和宽度。从性能上看,它影响姿态估计的精度和速度。输出步长值越低,精度越高但速度越慢;步长值越高,速度越快精度越低。查看输出步长对性能的影响,最好是通过使用单姿态估计演示。
单姿态估计算法的输出:
包含姿势的置信度值和17个关键点数组。
每个关键点都包含位置和置信度值。所有关键点位置在输入的图像空间中都有x和y坐标值,并且可以直接映射到图像上。
单人物动作跟踪算法:
输出示例:

第三步:多个人物姿态估计算法

多人动作跟踪算法可以跟踪图像中多人的动作。和单人算法相比更复杂也更慢,它的优点是如果一张图片中出现多个人物,则多人动作跟踪算法检测到的关键点不会匹配错误的人物 。因此,即使上面的用例是跟踪单个人的动作,用多人算法也更理想。
此外,该算法另一个吸引人的特性是它的性能不受输入图像中人数的影响。无论是15人还是5人,计算用的时间都是一样的。
输入:
输入图像元素——和单人算法一样;
图像比例因子——和单人算法一样;
水平翻转——和单人算法一样;
输出步幅——和单人算法一样;
最大人物数量检测——一个整数,默认为5,表示要检测人物的最大数量;
人物姿势置信度阈值——范围是0-1,默认为0.5,该值将控制返回姿态的最低置信度值;
非极大值抑制——以像素为单位,这个值控制返回人物之间的最小距离。这个值默认为20,在大多数情况下是合适的。该值的增加或者减少是过滤不太精确的姿态的一种方式,但只是在调整姿态置信度值不够好的情况下。
输出:
包含姿态信息的数组
每个姿势包含与单人算法中描述的相同的信息
多人姿态估计算法:

输出数组:

感兴趣的小伙伴可以自己根据代码去实现相应的内容哦~文章的下一部分将讨论实现该算法的一些技术细节。
欢迎持续关注我们微信公众号(geetest_jy),还可以添加技术助理微信“geetest1024”微信,一起交流进步!
