编译运行Hello!
Hello!
编译运行Vadd!
实验于虚拟机上运行,因此OpenCL运行时间实际不如CPU串行快。
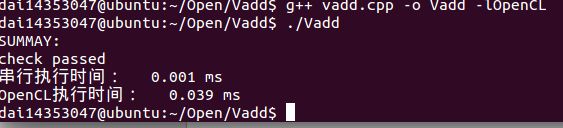
Vadd(Vecsize=6)
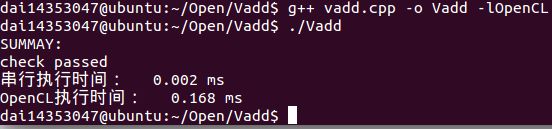
Vadd(Vecsize=10)
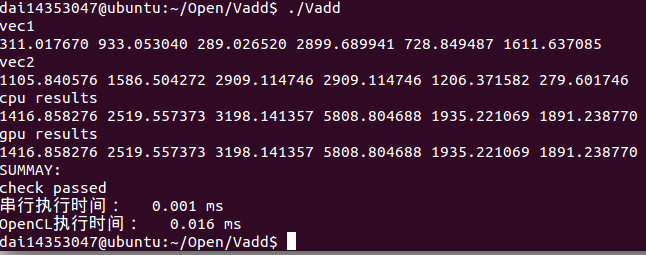
可通过定义print_vec来输出向量查看
编写矩阵乘法并运行
基本思想:
暴力三重循环
C++
for ( i = 0; i < VECSIZE; i++)
{
for ( j = 0; j < VECSIZE; j++)
{
buf[i][j]=0;
for (int k = 0; k < VECSIZE; k++)
{
buf[i][j]+=buf1[i][k]*buf2[k][j];
}
}
}
OpenCL实现
继续采集kernel的维数(这里为2),然后将两个变量作为row和col放到原来的三重循环中并在函数调用中加入新参数W。在设置kernel参数时自然也要加上这个参数的设置。
__kernel void matrix(
__global float* c, __global const float* a, __global const float* b, int VECSIZE) {
int id0 = get_global_id(1);
int id1 = get_global_id(0);
printf("[%d , %d ]",get_global_id(1),get_global_id(0));
float tmp=0;
for (int k = 0;k数组升级到二维数组后对源代码的调整
总的来讲就是指针的加次
void showVec(const char* name , float** vec)
float** const buf1 = (float**)malloc(VECSIZE * sizeof(float*));
for(i=0;i与数量相关的由1变成2
//Set local and global workgroup sizes
size_t global_work_size[2] = {VECSIZE,VECSIZE};
//执行kernel
status=clEnqueueNDRangeKernel(
queue , kernel,
2, 0, global_work_size,NULL,
0, NULL, &prof_event);
与空间有关的由W变成W*W。
//创建三个OpenCL内存对象
cl_mem clbuf1 = clCreateBuffer(context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
VECSIZE * VECSIZE * sizeof(cl_float), buf1,
NULL );
//设置Kernel参数
cl_int length = VECSIZE*VECSIZE;
//数据拷回host内存
float* op_data = 0;
op_data = (cl_float*) clEnqueueMapBuffer( queue,
cloutbuf,
CL_TRUE,
CL_MAP_READ,
0,
VECSIZE * VECSIZE * sizeof(cl_float),
0, NULL, NULL, NULL );
结果
结果不尽人意。C++的运算结果应该正确,然而GPU的结果不禁数据有问题,而且有缺失,具体情况为WW的数组中只有(W-2)(W-2)个数据,即W=4时只采集到4个数据,W=6时只采集到16个数据,等等。
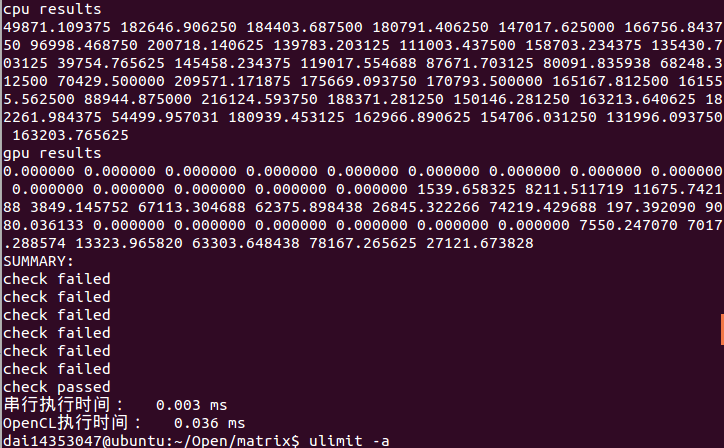
实验结果1
后来我试着在kernel函数中输出了get_global_id(),可以看出get_global_id(0)一直是0,而它理应也有变化才能实现循环,这是导致结果出错的原因。我会早日解决之。

实验结果2
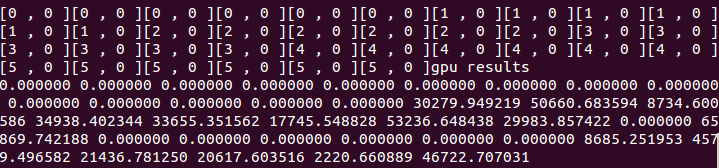
实验结果3