说明:不少读者反馈,想使用开源组件搭建Hadoop平台,然后再部署Kylin,但是遇到各种问题。这里我为读者部署一套环境,请朋友们参考一下。如果还有问题,再交流。
系统环境以及各组件版本信息
Linux操作系统:
cat /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)
JDK版本:
java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build25.111-b14, mixed mode)
Hadoop组件版本:
Hive:apache-hive-1.2.1-bin
Hadoop:hadoop-2.7.2
HBase:hbase-1.1.9-bin
Zookeeper:zookeeper-3.4.6
Kylin版本:
apache-kylin-1.5.4.1-hbase1.x-bin
三个节点情况以及安装的组件(仅测试):
192.168.1.129 ldvl-kyli-a01 ldvl-kyli-a01.idc.dream.com
192.168.1.130 ldvl-kyli-a02 ldvl-kyli-a02.idc.dream.com
192.168.1.131 ldvl-kyli-a03 ldvl-kyli-a03.idc.dream.com
基础组件部署
JDK环境搭建(3个节点)
rpm包安装:
rpm -ivh jdk-8u111-linux-x64.rpm
配置环境变量:
vi /etc/profile
export JAVA_HOME=/usr/java/default
export JRE_HOME=/usr/java/default/jre
exportCLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
exportPATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
source /etc/profile
验证:
java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build25.111-b14, mixed mode)
Zookeeper环境搭建(3个节点)
安装:
tar -zxvf zookeeper-3.4.6.tar.gz -C /usr/local/
cd /usr/local/
ln -s zookeeper-3.4.6 zookeeper
创建数据和日志目录
mkdir /usr/local/zookeeper/zkdata
mkdir /usr/local/zookeeper/zkdatalog
配置Zookeeper参数
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
修改好的配置文件如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/zkdata
dataLogDir=/usr/local/zookeeper/zkdatalog
clientPort=2181
server.1=ldvl-kyli-a01:2888:3888
server.2=ldvl-kyli-a02:2888:3888
server.3=ldvl-kyli-a03:2888:3888
创建myid
cd /usr/local/zookeeper/zkdata
echo 1 > myid #每个节点根据上面的配置(server.x)创建对应的文件内容
启动Zookeeper:
zkServer.sh start
查看状态:
192.168.1.129节点:
zkServer.sh status
JMX enabled by default
Using config:/usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
192.168.1.130节点:
zkServer.sh status
JMX enabled by default
Using config:/usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader
192.168.1.131节点:
zkServer.sh status
JMX enabled by default
Using config:/usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
MariaDB数据库
安装:
yum install MariaDB-server MariaDB-client
启动:
systemctl start mariadb
设置root密码,安全加固等:
mysql_secure_installation
关闭防火墙
systemctl disable firewalld
systemctl stop firewalld
同时,也需要关闭SELinux,可修改 /etc/selinux/config 文件,将其中的 SELINUX=enforcing 改为 SELINUX=disabled即可。
三个节点保证时间同步
可以通过ntp服务进行设置
Hadoop组件部署
Hadoop
创建组和用户:
groupadd hadoop
useradd -s /bin/bash -d /app/hadoop -m hadoop-g hadoop
passwd hadoop
下面所有的操作都是在hadoop用户下面操作
切换到hadoop用户下面创建信任关系:
ssh-keygen -t rsa
ssh-copy-id -p 22 [email protected]
ssh-copy-id -p 22 [email protected]
ssh-copy-id -p 22 [email protected]
解压缩:
$ tar -zxvf hadoop-2.7.2.tar.gz
设置软链接:
$ ln -s hadoop-2.7.2 hadoop
配置:
$ cd /app/hadoop/hadoop/etc/hadoop
l core-site.xml
fs.defaultFS
hdfs://ldvl-kyli-a01:9000
hadoop.tmp.dir
file:/app/hadoop/hadoop/tmp
io.file.buffer.size
131702
l hdfs-site.xml
dfs.namenode.name.dir
file:/app/hadoop/hdfs/name
dfs.datanode.data.dir
file:/app/hadoop/hdfs/data
dfs.replication
3
dfs.http.address
ldvl-kyli-a01:50070
dfs.namenode.secondary.http-address
ldvl-kyli-a01:50090
dfs.webhdfs.enabled
true
dfs.permissions
false
dfs.blocksize
268435456
HDFS blocksize of 256MB for largefile-systems.
dfs.datanode.max.xcievers
4096
l yarn-site.xml
l mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
ldvl-kyli-a01:10020
mapreduce.jobhistory.webapp.address
ldvl-kyli-a01:19888
l slaves
ldvl-kyli-a01
ldvl-kyli-a02
ldvl-kyli-a03
l hadoop-env.sh,mapred-env.sh和yarn-env.sh
export JAVA_HOME=/usr/java/default
环境变量配置(这里我将所有的组件的环境变量都配置好了,后面每个组件我就不再说明):
$ cat .bashrc
export JAVA_HOME=/usr/java/default
export JRE_HOME=/usr/java/default/jre
exportCLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export HIVE_HOME=/app/hadoop/hive
export HADOOP_HOME=/app/hadoop/hadoop
export HBASE_HOME=/app/hadoop/hbase
added by HCAT
export HCAT_HOME=/app/hadoop/hive/hcatalog
added by Kylin
export KYLIN_HOME=/app/hadoop/kylin
export KYLIN_CONF=/app/hadoop/kylin/conf
exportPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin:${KYLIN_HOME}/bin:$PATH
创建HDFS的数据目录
$ mkdir -p /app/hadoop/hdfs/data
$ mkdir -p /app/hadoop/hdfs/name
$ mkdir -p /app/hadoop/tmp
加入上面的hadoop所有配置都配置完成了,你也可以全部拷贝到其他节点。
HDFS格式化:
$ hdfs namenode -format
$ start-dfs.sh
$ start-yarn.sh
$ mr-jobhistory-daemon.sh starthistoryserver
然后进行验证操作,比如同通过jps查看进程,通过web页面服务hdfs和yarn,执行wordcount的测试程序等等
Hive组件部署
安装:
$ tar -zxvf apache-hive-1.2.1-bin.tar.gz
$ ln -s apache-hive-1.2.1-bin hive
配置:
$ cd /app/hadoop/hive/conf
l hive-env.sh
export HIVE_HOME=/app/hadoop/hive
HADOOP_HOME=/app/hadoop/hadoop
export HIVE_CONF_DIR=/app/hadoop/hive/conf
l hive-site.xml
l hive-log4j.properties
hive.log.dir=/app/hadoop/hive/log
hive.log.file=hive.log
将mysql-connector-java-5.1.38-bin.jar放到Hive的lib目录下面:
$ cp mysql-connector-java-5.1.38-bin.jar/app/hadoop/hive/lib/
创建Hive元数据库:
MariaDB [(none)]> create database metastore character set latin1;
grant all on metastore.* to hive@"%" identified by "123456" with grant option;
flush privileges;
启动服务:
nohup hive --service metastore -v &
$ tailf nohup.out
Starting Hive Metastore Server
17/03/16 14:10:29 WARN conf.HiveConf:HiveConf of name hive.metastore.local does not exist
Starting hive metastore on port 9083
HBase组件部署
安装:
$ tar -zxvf hbase-1.1.9-bin.tar.gz
$ ln -s hbase-1.1.9 hbase
配置:
l hbase-site.xml
hbase.rootdir
hdfs://ldvl-kyli-a01:9000/hbaseforkylin
hbase.cluster.distributed
true
hbase.master.port
16000
hbase.master.info.port
16010
hbase.zookeeper.quorum
ldvl-kyli-a01,ldvl-kyli-a02,ldvl-kyli-a03
hbase.zookeeper.property.clientPort
2181
hbase.zookeeper.property.dataDir
/usr/local/zookeeper/zkdata
l regionservers
ldvl-kyli-a02
ldvl-kyli-a03
l hbase-env.sh
export JAVA_HOME=/usr/java/latest
export HBASE_OPTS="-Xmx268435456-XX:+HeapDumpOnOutOfMemoryError -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode-Djava.net.preferIPv4Stack=true $HBASE_OPTS"
exportHBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m-XX:MaxPermSize=128m"
exportHBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m-XX:MaxPermSize=128m"
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_PID_DIR=${HBASE_HOME}/logs
export HBASE_MANAGES_ZK=false
如果日志目录不存在,需要提前创建好。
启动HBase服务:
$ start-hbase.sh
Kylin环境部署(我只选第一个节点安装,仅测试)
安装:
$ tar -zxvf apache-kylin-1.5.4.1-hbase1.x-bin.tar.gz
$ ln -s apache-kylin-1.5.4.1-hbase1.x-bin kylin
配置:
$ cd kylin/conf/
l kylin.properties # 基本默认值
kyin.server.mode=all
kylin.rest.servers=192.168.1.129:7070
kylin.rest.timezone=GMT+8
kylin.hive.client=cli
kylin.hive.keep.flat.table=false
kylin.metadata.url=kylin_metadata@hbase
kylin.storage.url=hbase
kylin.storage.cleanup.time.threshold=172800000
kylin.hdfs.working.dir=/kylin
kylin.hbase.default.compression.codec=none
kylin.hbase.region.cut=5
kylin.hbase.hfile.size.gb=2
kylin.hbase.region.count.min=1
kylin.hbase.region.count.max=50
环境变量配置:
$ cat .bashrc
export JAVA_HOME=/usr/java/default
export JRE_HOME=/usr/java/default/jre
exportCLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
exportPATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export HIVE_HOME=/app/hadoop/hive
export HADOOP_HOME=/app/hadoop/hadoop
export HBASE_HOME=/app/hadoop/hbase
added by HCAT
export HCAT_HOME=/app/hadoop/hive/hcatalog
added by Kylin
export KYLIN_HOME=/app/hadoop/kylin
export KYLIN_CONF=/app/hadoop/kylin/conf
exportPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin:${KYLIN_HOME}/bin:$PATH
检查Kylin用来的环境变量:
$ ${KYLIN_HOME}/bin/check-env.sh
KYLIN_HOME is set to /app/hadoop/kylin
$ kylin/bin/find-hbase-dependency.sh
hbase dependency: /app/hadoop/hbase/lib/hbase-common-1.1.9.jar
$ kylin/bin/find-hive-dependency.sh
Logging initialized using configuration infile:/app/hadoop/apache-hive-1.2.1-bin/conf/hive-log4j.properties
HCAT_HOME is set to:/app/hadoop/hive/hcatalog, use it to find hcatalog path:
hive dependency:/app/hadoop/hive/conf:/app/hadoop/hive/lib/jcommander-1.32.jar:/app/hadoop/hive/lib/stringtemplate-3.2.1.jar:/app/hadoop/hive/lib/hive-shims-0.23-1.2.1.jar:/app/hadoop/hive/lib/hive-jdbc-1.2.1-standalone.jar:/app/hadoop/hive/lib/hamcrest-core-1.1.jar:/app/hadoop/hive/lib/commons-compress-1.4.1.jar:/app/hadoop/hive/lib/xz-1.0.jar:/app/hadoop/hive/lib/hive-common-1.2.1.jar:/app/hadoop/hive/lib/guava-14.0.1.jar:/app/hadoop/hive/lib/commons-collections-3.2.1.jar:/app/hadoop/hive/lib/jta-1.1.jar:/app/hadoop/hive/lib/antlr-2.7.7.jar:/app/hadoop/hive/lib/maven-scm-provider-svn-commons-1.4.jar:/app/hadoop/hive/lib/hive-metastore-1.2.1.jar:/app/hadoop/hive/lib/hive-jdbc-1.2.1.jar:/app/hadoop/hive/lib/commons-httpclient-3.0.1.jar:/app/hadoop/hive/lib/ivy-2.4.0.jar:/app/hadoop/hive/lib/geronimo-annotation_1.0_spec-1.1.1.jar:/app/hadoop/hive/lib/commons-pool-1.5.4.jar:/app/hadoop/hive/lib/maven-scm-api-1.4.jar:/app/hadoop/hive/lib/mysql-connector-java-5.1.38-bin.jar:/app/hadoop/hive/lib/commons-configuration-1.6.jar:/app/hadoop/hive/lib/accumulo-start-1.6.0.jar:/app/hadoop/hive/lib/asm-commons-3.1.jar:/app/hadoop/hive/lib/libfb303-0.9.2.jar:/app/hadoop/hive/lib/commons-dbcp-1.4.jar:/app/hadoop/hive/lib/log4j-1.2.16.jar:/app/hadoop/hive/lib/hive-shims-common-1.2.1.jar:/app/hadoop/hive/lib/junit-4.11.jar:/app/hadoop/hive/lib/antlr-runtime-3.4.jar:/app/hadoop/hive/lib/commons-cli-1.2.jar:/app/hadoop/hive/lib/commons-logging-1.1.3.jar:/app/hadoop/hive/lib/ant-1.9.1.jar:/app/hadoop/hive/lib/hive-contrib-1.2.1.jar:/app/hadoop/hive/lib/httpcore-4.4.jar:/app/hadoop/hive/lib/datanucleus-api-jdo-3.2.6.jar:/app/hadoop/hive/lib/commons-beanutils-1.7.0.jar:/app/hadoop/hive/lib/curator-recipes-2.6.0.jar:/app/hadoop/hive/lib/netty-3.7.0.Final.jar:/app/hadoop/hive/lib/accumulo-trace-1.6.0.jar:/app/hadoop/hive/lib/jetty-all-server-7.6.0.v20120127.jar:/app/hadoop/hive/lib/servlet-api-2.5.jar:/app/hadoop/hive/lib/curator-client-2.6.0.jar:/app/hadoop/hive/lib/hive-shims-scheduler-1.2.1.jar:/app/hadoop/hive/lib/commons-lang-2.6.jar:/app/hadoop/hive/lib/geronimo-jaspic_1.0_spec-1.0.jar:/app/hadoop/hive/lib/curator-framework-2.6.0.jar:/app/hadoop/hive/lib/asm-tree-3.1.jar:/app/hadoop/hive/lib/hive-beeline-1.2.1.jar:/app/hadoop/hive/lib/velocity-1.5.jar:/app/hadoop/hive/lib/maven-scm-provider-svnexe-1.4.jar:/app/hadoop/hive/lib/commons-io-2.4.jar:/app/hadoop/hive/lib/ant-launcher-1.9.1.jar:/app/hadoop/hive/lib/mail-1.4.1.jar:/app/hadoop/hive/lib/accumulo-core-1.6.0.jar:/app/hadoop/hive/lib/geronimo-jta_1.1_spec-1.1.1.jar:/app/hadoop/hive/lib/oro-2.0.8.jar:/app/hadoop/hive/lib/eigenbase-properties-1.1.5.jar:/app/hadoop/hive/lib/commons-math-2.1.jar:/app/hadoop/hive/lib/apache-log4j-extras-1.2.17.jar:/app/hadoop/hive/lib/commons-compiler-2.7.6.jar:/app/hadoop/hive/lib/commons-digester-1.8.jar:/app/hadoop/hive/lib/ST4-4.0.4.jar:/app/hadoop/hive/lib/parquet-hadoop-bundle-1.6.0.jar:/app/hadoop/hive/lib/datanucleus-core-3.2.10.jar:/app/hadoop/hive/lib/json-20090211.jar:/app/hadoop/hive/lib/bonecp-0.8.0.RELEASE.jar:/app/hadoop/hive/lib/hive-service-1.2.1.jar:/app/hadoop/hive/lib/snappy-java-1.0.5.jar:/app/hadoop/hive/lib/stax-api-1.0.1.jar:/app/hadoop/hive/lib/jetty-all-7.6.0.v20120127.jar:/app/hadoop/hive/lib/jline-2.12.jar:/app/hadoop/hive/lib/libthrift-0.9.2.jar:/app/hadoop/hive/lib/hive-testutils-1.2.1.jar:/app/hadoop/hive/lib/accumulo-fate-1.6.0.jar:/app/hadoop/hive/lib/hive-cli-1.2.1.jar:/app/hadoop/hive/lib/hive-accumulo-handler-1.2.1.jar:/app/hadoop/hive/lib/jpam-1.1.jar:/app/hadoop/hive/lib/groovy-all-2.1.6.jar:/app/hadoop/hive/lib/httpclient-4.4.jar:/app/hadoop/hive/lib/avro-1.7.5.jar:/app/hadoop/hive/lib/zookeeper-3.4.6.jar:/app/hadoop/hive/lib/hive-hwi-1.2.1.jar:/app/hadoop/hive/lib/hive-exec-1.2.1.jar:/app/hadoop/hive/lib/hive-shims-0.20S-1.2.1.jar:/app/hadoop/hive/lib/super-csv-2.2.0.jar:/app/hadoop/hive/lib/opencsv-2.3.jar:/app/hadoop/hive/lib/commons-vfs2-2.0.jar:/app/hadoop/hive/lib/hive-serde-1.2.1.jar:/app/hadoop/hive/lib/commons-beanutils-core-1.8.0.jar:/app/hadoop/hive/lib/derby-10.10.2.0.jar:/app/hadoop/hive/lib/plexus-utils-1.5.6.jar:/app/hadoop/hive/lib/datanucleus-rdbms-3.2.9.jar:/app/hadoop/hive/lib/jdo-api-3.0.1.jar:/app/hadoop/hive/lib/joda-time-2.5.jar:/app/hadoop/hive/lib/activation-1.1.jar:/app/hadoop/hive/lib/janino-2.7.6.jar:/app/hadoop/hive/lib/regexp-1.3.jar:/app/hadoop/hive/lib/hive-shims-1.2.1.jar:/app/hadoop/hive/lib/paranamer-2.3.jar:/app/hadoop/hive/lib/hive-hbase-handler-1.2.1.jar:/app/hadoop/hive/lib/tempus-fugit-1.1.jar:/app/hadoop/hive/lib/commons-codec-1.4.jar:/app/hadoop/hive/lib/hive-ant-1.2.1.jar:/app/hadoop/hive/lib/jsr305-3.0.0.jar:/app/hadoop/hive/lib/pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar:/app/hadoop/hive/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar
环境检查没有问题,开始启动Kylin服务:
kylin.sh start
导入样例:
$ sample.sh
然后通过Kylin的Web页面重新加载元数据,然后构建Cube就可以查询了:
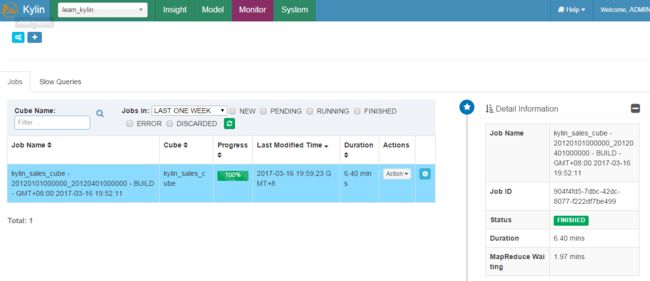
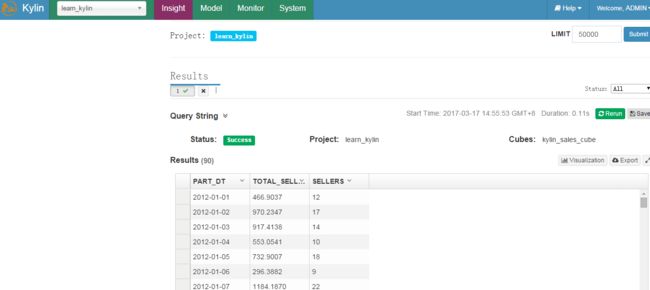
查询:
select part_dt, sum(price) as total_selled,count(distinct seller_id) as sellers from kylin_sales group by part_dt order bypart_dt
转自 http://blog.csdn.net/jiangshouzhuang/article/details/64151586