ElasticSearch是基于lucener的封装,提供一套REST API, 使得用户能够快速的对海量数据进行存储,检索和分析。但是对中文的处理还需要一些额外的插件,本文就以ik为进行基本使用说明
1. 资源准备
a. 由于ik插件没有对最新版es进行适配,因此在官网历史发行版本(https://www.elastic.co/downloads/past-releases)中选择6.3.0这个版本进行下载,解压后启动bin目录下的elasticsearch.bat文件即启动了es服务器,默认端口为9200, 因此访问localhost:9200就可以验证是否启动成功,成功返回如下json串
{
"name": "cc5-WZ7",
"cluster_name": "elasticsearch",
"cluster_uuid": "_5r724yQTs6Lkdc2rP_ncQ",
"version": {
"number": "6.3.0",
"build_flavor": "default",
"build_type": "zip",
"build_hash": "424e937",
"build_date": "2018-06-11T23:38:03.357887Z",
"build_snapshot": false,
"lucene_version": "7.3.1",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
b. 在ik的github页面即可下载对应版本的插件https://github.com/medcl/elasticsearch-analysis-ik/releases, 下载后在es安装目录中plugin文件夹下新建ik目录,并在此目录解压下载下来的压缩包,重启es即可使用
2. 基本使用
在正式使用之前先了解几个es中的基本概念:
Cluster: 集群,由多个es服务器组成
Node: 节点,表示一个es服务器
Index: 索引,也是最重要的概念
Type: 类别,一个Index可以对应多个,但是太多会影响性能,最好一个,后面这个概念可能会移除
Document: Index中的单条记录即为一个Document, 也是核心数据
可以将es理解成一个分布式数据库服务器, 说到数据库最基本的操作当然是增删改查,所以接下来就演示怎么样进行基本的增删改查。
2.1 新建Index
新建一个url为'localhost:9200/user_index'PUT请求,body内容如下:
{
"mappings": {
"person": {
"properties": {
"user": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}
成功后返回:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "user_index"
}
此处采用的的是postman工具,如下图所示:

该过程表示创建一个名称为 user_index的Index, 里面有一个名称为person的Type, person有user,title,desc三个字段, 并且三个字段类型都是text, 字段文本和搜索词的分词的分析器都是'ik_max_word', 由ik插件提供。
访问localhost:9200/_cat/indices?v查看所有的Index情况:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open user_index djAudaiaT8qdyPrGQMkMTA 5 1 0 0 1.2kb 1.2kb
2.2 新建Document
发送一个url为localhost:9200/user_index/person/1的PUT请求,body如下:
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
返回:
{
"_index": "user_index",
"_type": "person",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
注意url最后面的1可以不要,系统会自动给你生成一个随机字符串作为id, 当需要更新时重新发送一个PUT请求就好,需要删除时将PUT请求改为DELETE, 并且不带body。
2.3 查询
查询分为单个查询,即将创建的PUT方法改为GET即可查, 所有查询用localhost:9200/user_index/person/_search, 如下可以看到耗时(单位为毫秒)以及其它的很多信息。
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "user_index",
"_type": "person",
"_id": "1",
"_score": 1,
"_source": {
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
},
{
"_index": "user_index",
"_type": "person",
"_id": "Gk3ga2UBjmkW6Yw8zoQ4",
"_score": 1,
"_source": {
"user": "王五",
"title": "JAVA",
"desc": "后端开发工程师"
}
},
{
"_index": "user_index",
"_type": "person",
"_id": "GU3ga2UBjmkW6Yw8P4R6",
"_score": 1,
"_source": {
"user": "李四",
"title": "工程师",
"desc": "数据库专家"
}
}
]
}
}
接下来看看怎么用全文搜索:
在上面的url加上一个body即可:
{
"query" : { "match" : { "desc" : "数据" }}
}
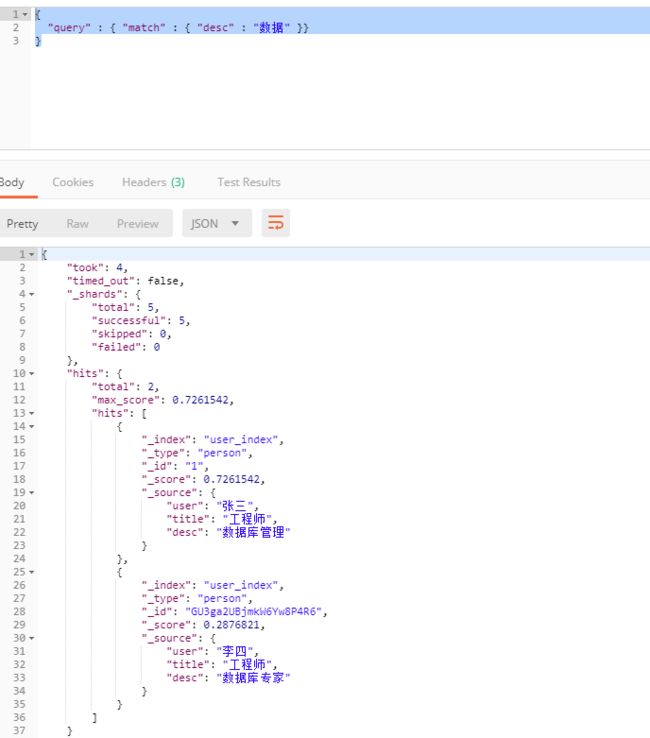
如果多个的话用空格隔开表示or,满足一个词就行
{
"query" : { "match" : { "desc" : "数据 后端" }}
}
如果需要and则应该如下, 需要同时满足两个词:
{
"query": {
"bool": {
"must": [
{ "match": { "desc": "数据" } },
{ "match": { "desc": "专家" } }
]
}
}
}
参考文章:
http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
https://blog.csdn.net/yejingtao703/article/details/78392902