一、通信方式
1.6版本之前Spark的通信机制只采用Akka通信框架;
-
1.6版本之后加入Netty通信框架,并通过配置的方式允许用户自定义使用哪种通信方式;
配置org.apache.spark.rpc.netty.NettyRpcEnvFactory 表示使用 netty 配置org.apache.spark.rpc.akka.AkkaRpcEnvFactory 表示使用 akka 2.0版本之后把Akka去掉,只保留了Netty。
2.0版本中把akka去掉了,主要原因是解决用户的Spark Application 中 Akka 版本和 Spark 内置的 Akka版本冲突的问题。很多Spark用户自己的应用程序中的通信框架也是使用Akka,但是由于Akka版本之间无法互相通信,这就要求用户必须使用跟Spark完全相同的版本,导致用户无法升级Akka。
1.1 RPC通信协议
网络通信需要遵守相同的通信协议,Spark通信采用的RPC通信协议。
RPC即远程过程调用协议,一种通过网络从远程计算机上请求服务而不需要了解底层网络传输技术的协议。
特点:
1. 调用远程就像调用本地一样。
2. 网络协议和网络IO模型对RPC调用者透明
3. 网络传输的信息格式对RPC调用者透明
1.2 Akka
Akka是一个开发库和运行环境,可以用于构建高并发、分布式、可容错、事件驱动的基于JVM的应用。使构建高并发的分布式应用更加容易。Akka最重要的是它的Actor模型。
Actor模型:
在使用Java进行并发编程时需要特别的关注锁和内存原子性等一系列线程问题,而Actor模型内部的状态由它自己维护即它内部数据只能由它自己修改(通过消息传递来进行状态修改),所以使用Actors模型进行并发编程可以很好地避免这些问题,Actor由状态(state)、行为(Behavior)和邮箱(mailBox)三部分组成。
状态(state):Actor中的状态指的是Actor对象的变量信息,状态由Actor自己管理,避免了并发环境下的锁和内存原子性等问题
行为(Behavior):行为指定的是Actor中计算逻辑,通过Actor接收到消息来改变Actor的状态
-
邮箱(mailBox):邮箱是Actor和Actor之间的通信桥梁,邮箱内部通过FIFO消息队列来存储发送方Actor消息,接受方Actor从邮箱队列中获取消息。
Actor的基础是消息通信,使用Actor的优势:
(1)事件模型驱动--Actor之间的通信是异步的,即使Actor在发送消息后也无需阻塞或者等待就能够处理其他事情; (2)强隔离性--Actor中的方法不能由外部直接调用,所有的一切都通过消息传递进行的,从而避免了Actor之间的数据共享,想要观察到另一个Actor的状态变化只能通过消息传递进行询问; (3)位置透明--无论Actor地址是在本地还是在远程机上对于代码来说都是一样的; (4)轻量性--Actor是非常轻量的计算单机,单个Actor仅占400多字节,只需少量内存就能达到高并发。
1.3 Netty
Netty是一款异步的事件驱动的网络应用程序框架,支持快速地开发可维护的高性能的面向协议的服务器和客户端。
Netty 使用不同的事件来通知状态的改变或者是操作的状态。事件可能包括:
- 连接已被激活或者连接失活
- 数据读取;
- 用户事件;
- 错误事件;
- 打开或者关闭到远程节点的连接;
- 将数据写到或者冲刷到套接字。
每个事件都可以被分发给 ChannelHandler 类中的某个用户实现的方法。
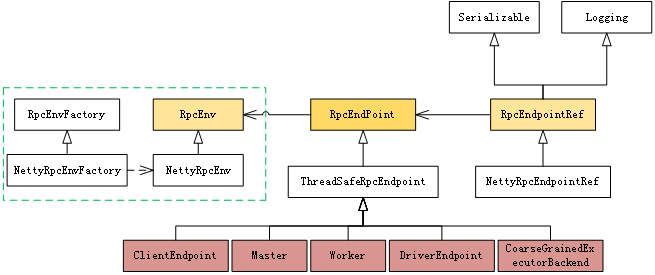
二、消息通信代码结构
三、通信中的概念
3.1 RpcEnv
RpcEnv 管理各个 RpcEndpoint 并将发送自 RpcEndpointRef 或远程节点的消息分发给对应的 RpcEndpoint。对于 RpcEnv 没有 catch 到的异常,会通过 RpcCallContext.sendFailure 将该异常发回给消息发送者或记日志。
3.2 RpcEndpoint
RPCEndpoint是一个通信实体,定义了如何处理消息(即,使用哪个函数来处理指定消息),在通过 name 向Dispatcher完成注册后,RpcEndpoint 就一直存放在 RpcEnv 中。Endpoint和EndpointRef以键值对的形式放在ConcurrentHashMap中。RpcEndpoint 的生命周期按顺序是 onStart,receive 及 onStop,receive 可以被同时调用,如果希望 receive 是线程安全的,可以使用 ThreadSafeRpcEndpoint。
RpcEndpoint提供了多个消息处理方法:
| 方法名 | 说明 |
|---|---|
| receive | 接收消息并处理,但不回复 |
| receiveAndReply | 接收消息处理后,并给客户端回复 |
| onError | 发生异常时,调用 |
| onConnected | 当客户端与当前节点连接上后调用 |
| onDisconnected | 当客户端与当前节点失去连接上后调用 |
| onNetworkError | 当网络连接发生错误进行处理 |
| onStart | 在 RpcEndpoint 处理消息前调用,可以在 RpcEndpoint 正式工作前做一些准备工作 |
| onStop | 在停止 RpcEndpoint 前调用,可以在 RpcEndpoint 结束前做一些收尾工作 |
Spark通信过程中会及到下面几个endpoint。

3.3 RpcEndpointRef
RpcEndpointRef 是 RpcEnv 中的 RpcEndpoint 的引用,是一个序列化的实体以便于通过网络传送或保存以供之后使用。要向远端的一个RpcEndpoint发起请求,必须拿到RpcEndpoint的引用。
一个 RpcEndpointRef 有一个地址和名字。可以调用 RpcEndpointRef 的 send 方法发送异步的单向的消息给对应的 RpcEndpoint。RpcEndpointRef 指定了 ip 和 port,是一个类似 spark://host:port/name 这种的地址。
3.4 Inbox
一个本地端点对应一个收件箱,Inbox 里面有一个 InboxMessage 的链表,InboxMessage 有很多子类,可以是远程调用过来的 RpcMessage,可以是远程调用过来的 fire-and-forget 的单向消息 OneWayMessage,还可以是各种服务启动,链路建立断开等 Message,这些 Message 都会在 Inbox 内部的方法内做模式匹配,调用相应的 RpcEndpoint 的函数。
InboxMessage包括的子类消息如下图:

3.5 Outbox
一个远程端点对应一个发件箱,NettyRpcEnv 中包含一个 ConcurrentHashMap[RpcAddress, Outbox]。当消息放入 Outbox 后,紧接着将消息通过 TransportClient 发送出去。
OutMessage包括的子类消息如下图:

3.6 EndPointData
Dispatcher进行消息分发,分发的就是EndpointData对象,封装了endpoint的name、Endpoint、EndpointRef、Inbox。
3.7 Dispatcher
消息分发器,负责将 RpcMessage 分发至对应的 RpcEndpoint。Dispatcher 中包含一个 MessageLoop,它读取 LinkedBlockingQueue 中的投递 RpcMessage,根据客户端指定的 Endpoint 标识,找到 Endpoint 的 Inbox,然后投递进去,由于是阻塞队列,当没有消息的时候自然阻塞,一旦有消息,就开始工作。Dispatcher 的 ThreadPool 负责消费这些 Message,由ThreadPool中的MessageLoop进行处理。
可以有效提高NettyRpcEnv消息异步处理能力和并行处理能力,负责将RPC消息路由到应该对此消息处理的RpcEndpoint端点。
RpcEndpoint启动时都要注册到Dispatcher中。首先RpcEndpoint启动调用RpcEnv的setupEndpoint方法,该方法内部其实调用了dispatcher的regiserRpcEndpoint方法,该方法具体流程如下:
1. 获取RpcEndpoint的address
2. 获取Endpoint的ref信息
3. new EndpointData,并将endpoint的name和endpointData放入到enpoints映射map中。(new EndpointData时会new一个InBox,在new Inbox过程中会将endpoint的onStart消息放入该Inbox的messages列表中)
4. 将endpoint和endpointRef放入到endpointRefs的映射Map中。
5. 将endpointData放入Dispatcher的消息阻塞队列中。
6. Dispatcher的threadpool就会处理endpoint的onStart消息了。
3.8 概念之间关系
系统启动时,RpcEnv有一个核心方法setupEndpoint,用于在Dispatcher中注册endpoint:
1)注册endpoint的name与EndpointData的映射
2)注册endpoint与endpointRef的映射
3)填充receivers阻塞队列
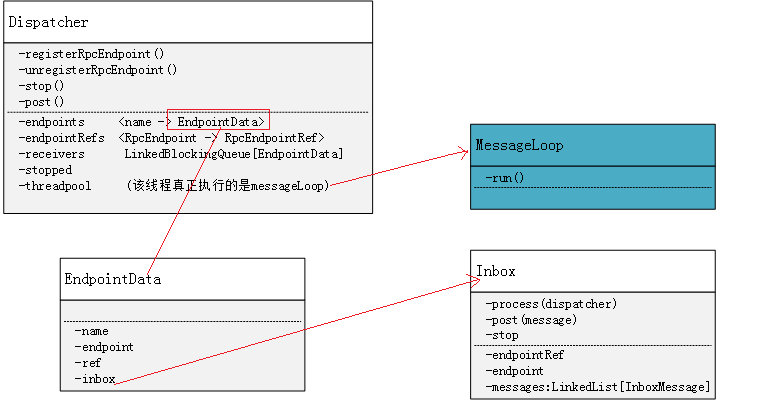
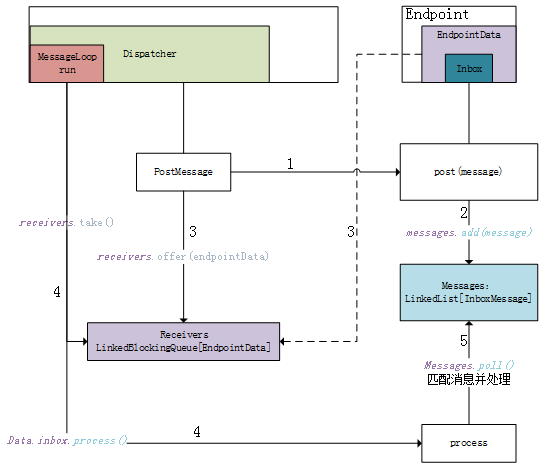
Inbox中的messages来源:
(1)注册endpoint
注册endpoint时Dispatcher的registerRpcEndpoint()方法需要为endpoint new一个EndpointData对象,new EndpointData 时都会创建一个与之对应的 Inbox,在 Inbox 中会将 OnStart 消息加入其 messages 列表,之后Dispatcher将该endpoint的EndpointData放入receivers中,由于receivers是阻塞队列,有消息后 MessageLoop 线程就会消费该消息。
(2)注销endpoint
注销endpoint时需要将EndpointData从endpoints的映射中移除,然后inbox向messages列表中发送OnStop消息,并将该EndpointData放入receivers阻塞队列中由MessageLoop线程处理。
(3)发送消息PostMessage
PostMessage有两个必传参数,分别是endpointName和message,即表示向谁发送什么样的消息。首先在Dispatcher中基于endpointName拿到对应的EndpointData,将消息发送到该data的inbox中,并将data放入receiveres中由MessageLoop处理。
(4)stop掉Dispatcher
停止Dispatcher时首先将所有的endpoint注销掉,会想receivers中放入PoisonPill毒药,使得receivers中全是null,是MessageLoop线程停止,之后显示地关闭线程池。
四、通信消息分类
Worker ——> Master
| 消息 | 说明 |
|---|---|
| RegisterWorker | 向master注册worker |
| Heartbeat | 向master发送心跳 |
| ExecutorStateChanged | 告诉master自己的executor状态变了 |
| DriverStateChanged | 告诉master自己的driver状态变了 |
| WorkerSchedulerStateResponse | 告诉master自己的调度状态 |
| WorkerLatestState | 向master报告自己最新的状态 |
Worker ——> Worker
| 消息 | 说明 |
|---|---|
| WorkDirCleanup | 清理应用程序目录 |
| ReregisterWithMaster | 当worker试图重连master时使用 |
Master ——> Worker
| 消息 | 说明 |
|---|---|
| RegisteredWorker | 告诉worker注册成功 |
| RegisterWorkerFailed | 告诉worker注册失败 |
| MasterInStandby | 告诉worker所注册的master是standby模式 |
| ReconnectWorker | 让worker重连 |
| SendHeartbeat | 让worker向自己发送心跳 |
| LaunchExecutor | 启动分配executor |
| KillExecutor | kill掉worker的executor |
| LaunchDriver | 启动分配driver |
| KillDriver | kill掉worker的driver |
| ApplicationFinishe | 告诉worker应用程序结束 |
| MasterChanged | Master变动 |
Appclient ——> Master
| 消息 | 说明 |
|---|---|
| RegisterApplication | 向master注册应用程序 |
| UnregisterApplication | 向master注销应用程序 |
| MasterChangeAcknowledged | 确认master变更 |
| RequestExecutors | 申请分配executor |
| KillExecutors | kill掉分配的executor |
Master——> Appclient
| 消息 | 说明 |
|---|---|
| RegisteredApplication | 通知Appclient应用程序注册成功 |
| ExecutorAdded | 通知appclient新分配的executor |
| ExecutorUpdated | 通知appclient更新的executor |
| ApplicationRemoved | 通知Appclient应用程序被移除 |
| WorkerRemoved | 通知Appclient有worker被移除 |
DriverClient <——> Master
| 消息 | 说明 |
|---|---|
| RequestSubmitDriver | driver -> master |
| SubmitDriverResponse | master -> driver |
| RequestKillDriver | driver -> master |
| KillDriverResponse | master -> driver |
| RequestDriverStatus | driver -> master |
| DriverStatusResponse | master -> driver |
五、消息通信流程
5.1 本地消息通信
Endoint通信终端点调用NettyRpcEndpointRef的send和ask方法,向本地节点的RpcEndpoint发送消息,由于是在同一节点,所以直接调用Dispatcher的postLocalMessage或postOneWayMessage方法,将消息放入EndpointData内部的Inbox的message列表中。
5.2 远程消息通信
Endoint通信终端点通过NettyRpcEndpointRef的send方法和ask方法向远端节点的RpcEndpoint发送消息,首先将消息封装成OutboxMessage,然后放入Outbox的message列表中。(每个Outbox与RpcEndpoint是一一对应的)。
每个Outbox中会调用drainOutbox方法不断循环,从messages列表中取得OutboxMessage。Outbox中会使用内部的TransportClient向远端的NettyRpcEnv发送OutboxMessage。和远端的NettyRpcEnv的TransportServer建立了连接后,请求消息首先经过Netty管道的处理,然后经由NettyRpcHandler的处理,最后来自服务端NettyRpcServer的回复消息会触发NettyRpcHandler的receive方法,进而调用Dispatcher的postRemoteMessage或者postOneWayMessage方法。
远程消息通信过程如下图所示。

消息分发器Dispatcher把消息分发到每个endpoint并进行消息处理的流程如下图所示。
六、Spark启动时消息通信
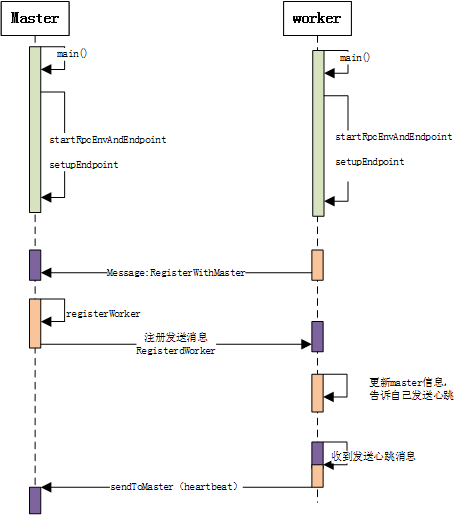
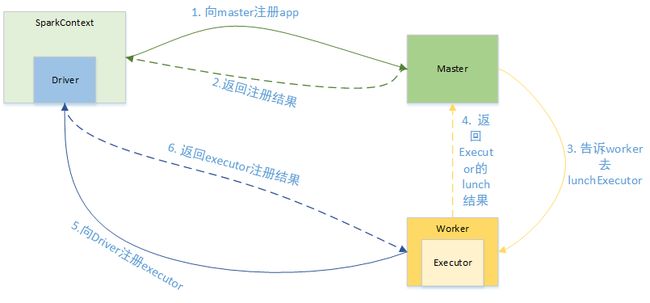
Spark启动时主要是Master启动以及Worker启动时向master注册。
1. Master和Worker都是RpcEndPoint终端点,在启动时首先由RpcEnv进行setupEndpoint注册。
2. 在setupEndpoint注册时会将终端点内部定义的自己的onStart消息放入Inbox的InboxMessage列表中,并将Master和Worker对应的EndpointData放入Dispatcher的receivers阻塞队列中。
3. Dispatcher的MessageLoop消费阻塞队列中的消息,做好初始步骤。
3.1 Master的初始步骤是进行配置的读取和设置,如Master的webui设置、rest.prot设置、recovery_mode等;
3.2 Worker的初始步骤是创建worker的工作目录、webui设置、向master注册自己。
4. Worker向Master注册自己是通过消息通信进行的。
七、Spark运行时消息通信
运行时通信主要是application启动时内部的通信过程,涉及到AppClient、DriverRpcEndpoint、ExecutorRpcEndpoint、Master、Worker之间的通信。
其他
BlockingQueue的核心方法
1.放入数据
offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.(本方法不阻塞当前执行方法的线程);
offer(E o, long timeout, TimeUnit unit):可以设定等待的时间,如果在指定的时间内,还不能往队列中加入BlockingQueue,则返回失败。
put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
- 获取数据
poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null;
poll(long timeout, TimeUnit unit):从BlockingQueue取出一个队首的对象,如果在指定时间内,队列一旦有数据可取,则立即返回队列中的数据。否则知道时间超时还没有数据可取,返回失败。
take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到BlockingQueue有新的数据被加入;
drainTo():一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数),通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。