node.js系统模块
1.file system 文件系统 fs
使用:
var fs = require(‘fs’);
2.fs.Dirent 类
1)dirent.isDirectory() 判断是否是一个文件夹
2)dirent.isFile() 判断是否是一个文件
3)dirent.name 返回文件或者文件夹的名称
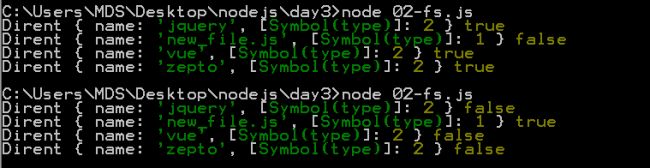
direct 是通过fs获取到的一个文件对象
fs.readdir('node_modules',{withFileTypes:true},function(err,dir){
if(err){
console.log('something error');
}else{
for(var i in dir){
// console.log(dir[i],dir[i].isDirectory());
console.log(dir[i],dir[i].isFile());
}
}
});
3.fs.FSWatcher 类
成功调用 fs.watch() 方法将返回一个新的 fs.FSWatcher 对象。所有 fs.FSWatcher 对象每当修改指定监视的文件,就会触发 'change' 事件。
1) change
当监视的目录或文件中发生更改时触发。
2) close
当监视器停止监视更改时触发。 关闭的 fs.FSWatcher 对象在事件处理函数中不再可用。
watcher.close() 用于关闭文件监视
给定的 fs.FSWatcher 停止监视更改。 一旦停止,则 fs.FSWatcher 对象将不再可用。
3) error
当监视文件时发生错误时触发。 发生错误的 fs.FSWatcher 对象在事件处理函数中不再可用。
4.fs.readStream 类
成功调用 fs.createReadStream() 将返回一个新的 fs.ReadStream 对象。
1) open
当 fs.ReadStream 的文件描述符打开时触发
3) ready
'open' 事件之后立即触发。
4) close
当 fs.ReadStream 的底层文件描述符已关闭时触发。
fs.ReadStream.close() //关闭读取流
5.fs.stats 类


一、缓存区、文件系统、路径 Day03
1.课程介绍
- Buffer缓存区(了解)
- fs文件模块(了解)
- fs读取文件(掌握)
- fs写文件(掌握)
- fs流读写方式(掌握)
- fs管道方式(掌握)
- zlib文件压缩模块(掌握)
1、path路径(掌握)
2、url模块(掌握)
2.Buffer缓存区
2.1.Buffer基本概念
JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。二进制可以存储电脑中任何数据(比如:一段文本、一张图片、一个硬盘,应该说电脑中所有的数据都是二进制。)
缓存区就是一个临时的内存区域,用于存储字节码数据。
NodeJs是服务端在处理像TCP(网络)流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
2.2.Buffer创建
Buffer 对象可以通过多种方式来创建。
2.2.1.方法 1
创建长度为 10 字节(1kb=1024byte 1byte=8bit)的 Buffer 实例:
var buf = new Buffer(10);
注意:创建缓存区时必须指定大小。
2.2.2.方法 2
通过给定的数组创建 Buffer 实例:
//2 创建指定字符的缓存区(可以是字符对应的ASICC编码的数字)
var bf2=new Buffer([97,61,62,63,122]); 97: a 122:z
console.log(bf2,bf2.toString());
注意:只能存数字,不能存字符串
2.2.3.方法 3
通过一个字符串来创建 Buffer 实例:
var buf = new Buffer("www.itsource.com", "utf-8");
utf-8 是默认的编码方式,此外它同样支持以下编码:"ascii", "utf8", "utf16le", "ucs2", "base64" 和 "hex"。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码。
扩展知识:位、字节、进制、编码方式(详解文章末尾)
2.3.Buffer写入内容
语法
buf.write(string[, offset[, length]][, encoding])
参数
参数描述如下:
string - 写入缓冲区的字符串。
offset - 缓冲区开始写入的索引值,默认为 0 。
length - 写入的字节数,默认为 buffer.length
encoding - 使用的编码。默认为 'utf8' 。
返回值
返回实际写入的大小。如果 buffer 空间不足, 则只会写入部分字符串。
实例:
var buf = new Buffer(256);
len = buf.write("www.itsource.com");
console.log("写入字节数 : "+ len);
2.4.Buffer读取内容(转换为字符串)
语法:
读取 Node 缓冲区数据的语法如下所示:
buf.toString([encoding[, start[, end]]])
参数:
参数描述如下:
encoding - 使用的编码。默认为 'utf8' 。
start - 指定开始读取的索引位置,默认为 0。
end - 结束位置,默认为缓冲区的末尾。
返回值:
解码缓冲区数据并使用指定的编码返回字符串。
var buf = new Buffer([97,98,99]);
console.log(buf.toString());
var s = “qq”;
s+=buf;//转换为字符串
console.log(s);
2.5.Buffer拷贝
拷贝一个Buffer的某一段到操作对象中。
语法
源.copy(目标缓存区)
buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]])
参数
参数描述如下:
targetBuffer - 要拷贝的 Buffer 对象。
targetStart - 数字, 可选, 默认: 0
sourceStart - 数字, 可选, 默认: 0
sourceEnd - 数字, 可选, 默认: buffer.length
返回值:
没有返回值。
实例:
var buffer1 = new Buffer('ABC');
// 拷贝一个缓冲区
var buffer2 = new Buffer(3);
buffer1.copy(buffer2);
console.log("buffer2 content: " + buffer2.toString());
3.fs文件基本操作
文件系统模块fs (file system),可以对文件和文件夹进行读取、写入、删除等操作。
3.1.fs模块
var fs = require("fs"); //引入fs 系统文件模块,对文件进行操作.
Node.js 文件系统(fs 模块)模块中的方法均有异步和同步版本,例如读取文件内容的函数有异步的 fs.readFile() 和同步的 fs.readFileSync()。
3.2.文件读取
var fs = require("fs"); //引入fs 系统文件模块,对文件进行操作.
// 异步读取
fs.`readFile`('input.txt', function (err, data) {
if (err) {
return console.error(err);
}
console.log("异步读取: " + data.toString());
});
// 同步读取
var data = fs.`readFileSync`('input.txt');
console.log("同步读取: " + data.toString());
console.log("程序执行完毕。");
案例:
文件读取:
//文件的读操作
//异步操作
//readFIle
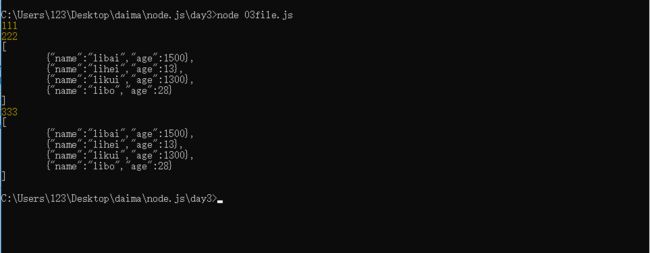
var fs = require('fs');
/*
console.log(111);
fs.readFile('./03.json',function(err,data){
//正确 err == nunll , data ==数据
//错误 err == 错误信息 ,data == undefined
console.log(333);
if(err){
console.log(err);
}else{
console.log(data.toString());
}
})
console.log(222);
*/
//123 李茂
//132 张振
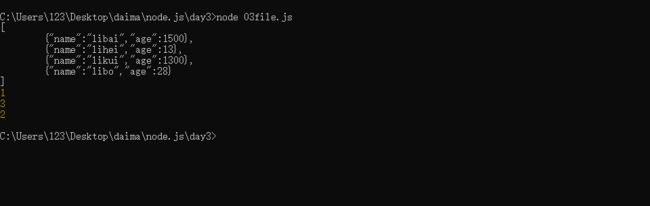
//同步操作 几乎所有的文件操作函数都具有一个同步操作的函数,这个函数在后面添加了Sync,而且同步操作的函数是没有回调函数的
var file = fs.readFileSync('03.json');
console.log(file.toString());
异步操作:
知识点:
定时器、延时器都是异步的操作
//js异步的最小时间
//setTimeout的最短时间间隔是4毫秒;
// setInterval的最短间隔时间是10毫秒
同步操作
知识点:
同步操作 几乎所有的文件操作函数都具有一个同步操作的函数,这个函数在后面添加了Sync,而且同步操作的函数是没有回调函数的
3.3.文件信息
以下为通过异步模式获取文件信息的语法格式:
fs.stat(path, callback)
参数:
参数使用说明如下:
path - 文件路径。
callback - 回调函数,带有两个参数如:(err, stats), stats 是 fs.Stats 对象。
fs.stat(path)执行后,会将stats类的实例返回给其回调函数。可以通过stats类中的
使用方法:
/*
*获取文件信息:
*fs.stat('文件名',function(err,stats){
*stats :是一个包含了文件信息的对象
*.size 文件大小
*.mtime 文件最后一次修改时间
*.isFile() 判断是否是一个文件
*.isDirectory() 判断是否是一个文件夹
* })
*/
判断是否为文件:
var fs = require('fs');
fs.stat('./my.txt', function (err, stats) {
console.log("文件信息对象的属性",stats);
console.log("文件大小byte",stats.size);
console.log("是否是文件",stats.isFile());
console.log("是否是目录",stats.isDirectory());
});
3.4.fs写文件
以下为异步模式下写入文件的语法格式:
fs.writeFile(filename, data[, options], callback)
如果文件存在,该方法写入的内容会覆盖旧的文件内容。
参数
参数使用说明如下:
path - 文件路径。
data - 要写入文件的数据,可以是 String(字符串) 或 Buffer(流) 对象。
options - 该参数是一个对象,包含 {encoding, mode, flag}。默认编码为 utf8, 模式为 0666 , flag 为 'w'
callback - 回调函数,回调函数只包含错误信息参数(err),在写入失败时返回。
实例
接下来我们创建 file.js 文件,代码如下所示:
var fs = require("fs");
console.log("准备写入文件");
fs.writeFile('input.txt', '我是通过写入的文件内容!', function(err) {
if (err) {
return console.error(err);
}
console.log("数据写入成功!");
});
//先读取并保留,然后加入新的数据
fs.readFile("02fileTest.txt",function(err,data){
if(err){
throw err;
}
else{
var oldContent=data;
fs.writeFile("02fileTest.txt",oldContent+",此消息不真实,是假的!!!!",function(err){
if(err){
throw err;
}
else{
console.log("文件追加写入成功!!!");
}
});
}
});
3.5.fs删除文件
语法
以下为删除文件的语法格式:
fs.unlink(path, callback)
参数
参数使用说明如下:
path - 文件路径。
callback - 回调函数,没有参数。
实例
var fs = require("fs");
console.log("准备删除文件!");
fs.unlink('./my.txt', function(err) {
if (err) {
return ;
}
console.log("文件删除成功!");
});
3.6.fs获取目录中的文件
//获取当前目录下面所有的文件及文件夹(列表--数组)
fs.readdir(".",function(err,files){
console.log(files);
});
fs.readdir("..",function(err,files){
console.log(files);
});
3.7.fs创建文件夹
语法
以下为创建文件夹的语法格式:
fs.mkdir(path, callback)
参数
参数使用说明如下:
path - 文件夹路径。
callback - 回调函数,没有参数。
var fs = require(“fs”);
fs.mkdir('./aaa', function(err) {
if (err) {
return ;
}
console.log("文件夹创建成功!");
});
3.8.fs删除空文件夹
语法
以下为删除文件的语法格式:
fs.rmdir(path, callback)
参数
参数使用说明如下:
path - 文件夹路径。
callback - 回调函数,没有参数。
var fs = require(“fs”);
fs.rmdir('./aaa', function(err) {
if (err) {
return ;
}
console.log("文件夹删除成功!");
});
4.fs流读写方式
前面我们已经学习了如何使用fs模块中的readFile方法、readFileSync方法读取文件中内容,及如何使用fs模块中的writeFile方法、writeFileSync方法向一个文件写入内容。
用readFile方法或readFileSync方法读取文件内容时,Node.js首将文件内容完整地读入缓存区,再从该缓存区中读取文件内容。在使用writeFile方法或writeFileSync方法写入文件内容时,Node.js首先将该文件内容完整地读人缓存区,然后再一次性的将缓存区中内容写入到文件中。
无论是read和write都是把文件视为一个整体,也就是说,NodeJs需要在内存中开辟与文件相等大小的空间来缓冲内容,如果文件比较小,这的确没有什么问题,但是如果是一个非常大的(10G)文件会怎样?内存就可能会溢出。
4.1.Stream流介绍
应用程序中,流是一组有序的、有起点和终点的字节数据的传输方式。在应用程序中各种对象之间交换与传输数据的时候,总是先将该对象中所包含的数据转换为各种形式的流数据(即字节数据),再通过流的传输,到达目的对象后再将流数据转换为该对象中可以使用的数据。
4.2.Stream流读取
/*
*读取流
*var stream=fs.createReadStream('文件路径'); //创建可以读取的流
*stream.on(); //然后绑定事件
*data 事件: 读取数据事件,读取到数据时就触发。 默认每次读取数据大小:64Kb
*end 事件: 数据读取结束事件,数据读取结束时触发。
*error事件: 错误事件,读取出错时触发。
*/
var fs = require("fs");
var rs=fs.createReadStream("04fileTest111.txt");
// 设置编码为 utf8。
rs.setEncoding("utf-8");
//存储每次读取的数据,统计读取的次数
var dataAll="",count=0;
//绑定data事件,当读取到数据时执行,每读取64kb就执行一次
rs.on("data",function(data){
dataAll+=data;
count++;
console.log("读取次数: ",count);
});
rs.on("end",function(){
//console.log("读取完毕",dataAll.toString());
console.log("读取完毕");
});
rs.on("error",function(err){
console.error("读取错误",err.message);
});
console.log("程序执行完毕");
4.3.Stream流写入
/*
* 写入流:
* var stream=fs.createWriteStream('文件路径'); //创建写入流
* stream.write('要写入的内容,可以多次写入');
* stream.end(); //结束标记,因为以流的方式可以多次写入,所以必须要有一个明确结束标记。
*
* 事件:
* finish 完成事件
* error 错误事件
*/
var fs = require("fs");
//如果文件不存在则会自动创建文件
var ws=fs.createWriteStream("04fileTest22.txt");
for(var i=1;i<=100;i++){
ws.write(i+"写入流WriteStream\n");
}
//很重要:以流方式写入数据,因为可以多次写入,所以需要一个明确的结束标记。
ws.end();
//绑定finish事件,在写入完成时触发。告诉用户写入成功了。
ws.on("finish",function(){
console.log("流写入完成!!!");
});
ws.on("error",function(err){
throw err;
});
console.log("程序执行完毕");
整合案例:
//流式操作
var fs = require('fs');
//创建文件读取流
var read_stream = fs.createReadStream('04.txt',{encoding:"utf-8"});
//data 事件
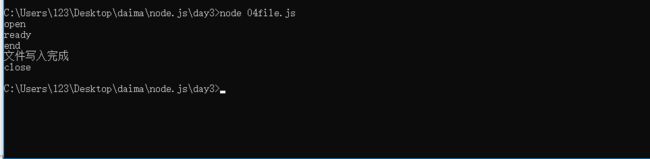
read_stream.on('open',function(){
console.log('open')
})
read_stream.on('ready',function(){
console.log('ready')
})
read_stream.on('close',function(){
console.log('close')
})
read_stream.on('end',function(){
console.log('end')
write_stream.end();
})
read_stream.on('data',function(ls){
write_stream.write(ls);
})
//创建文件写入流
var write_stream = fs.createWriteStream('04-w.txt');
write_stream.on('finish',function(){
console.log('文件写入完成');
})
取读流----》写入流
5.fs管道方式
管道(pipe)提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中。
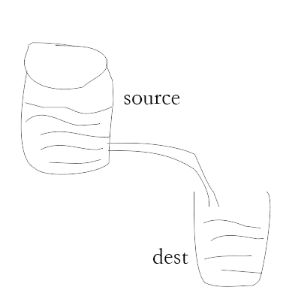
如上面的图片所示,我们把文件比作装水的桶,而水就是文件里的内容,我们用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就慢慢的实现了大文件的复制过程。
/*
* 管道 pipe:
* 管道(pipe)提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中。
* 语法:
* 读取流.pipe(写入流);
*/
//需求:使用流实现大文件的复制
var fs = require("fs");
// 创建一个可读流
var readerStream = fs.createReadStream('input.txt');
// 创建一个可写流
var writerStream = fs.createWriteStream('output.txt');
// 管道读写操作
// 读取 input.txt 文件内容,并将内容写入到 output.txt 文件中
readerStream.pipe(writerStream);
案例:
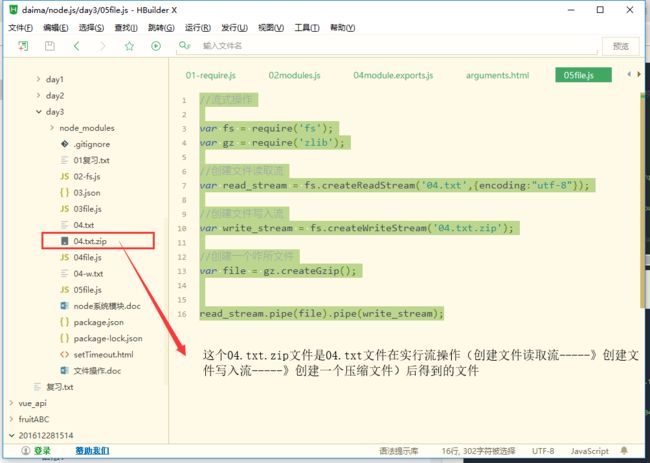
//流式操作
var fs = require('fs');
var gz = require('zlib');
//创建文件读取流
var read_stream = fs.createReadStream('04.txt',{encoding:"utf-8"});
//创建文件写入流
var write_stream = fs.createWriteStream('04.txt.zip');
//创建一个压缩文件
var file = gz.createGzip();
read_stream.pipe(file).pipe(write_stream);

6.链式流
链式是通过连接输出流到另外一个流并创建多个对个流操作链的机制。链式流一般用于管道操作。
/*
* 链式流:
* 从输出流到输入流,中间可以由多个中转流组成,形成一个完整的链式体系。
* 语法:
* 输出流.pipe(中转流).pipe(输入流);
*/
接下来我们就是用管道和链式来压缩和解压文件。
创建 compress.js 文件, 代码如下:
读取文件--压缩--写入文件
//引入文件系统
var fs=require("fs");
//引入压缩模块
var zip=require("zlib");
//读取文件--压缩--写入文件
//创建读取流
var rs=fs.createReadStream("04fileTest2.txt");
//链式流压缩文件
var gzip=zip.createGzip();
//创建写入流(要保留原来的扩展名.txt)
var ws=fs.createWriteStream("04fileTest2.txt.zip");
//读取的文件流利用管道压缩后,在通过管道流入写入文件流
rs.pipe(gzip).pipe(ws);
console.log("文件压缩成功!");
7.path路径
NodeJs中,提供了一个path模块,在这个模块中,提供了许多实用的、可被用来处理与转换文件路径的方法及属性。
/*
* path模块:用来处理与转换文件路径的方法及属性。
path.normalize(p) 规范化路径
path.join([path1][, path2][, ...]) 用于连接路径
path.dirname(p) 返回路径中代表文件夹
path.basename(p[, ext]) 返回路径中的文件名称
path.extname(p) 返回路径中文件的后缀名
path.parse() 返回一个对象包含路径中的每一个部分
* .dir 返回路径中的目录路径
* .base 返回含扩展名的文件名
* .ext 返回扩展名
* .name 返回文件名
*/
7.1.API方法和属性
方法:
| 方法 & 描述 |
|---|
path.normalize(p)规范化路径,注意'..' 和 '.'。 |
path.join([path1][, path2][, ...])用于连接路径。该方法的主要用途在于,会正确使用当前系统的路径分隔符,Unix系统是"/",Windows系统是""。 |
| path.resolve([from ...], to)将 to 参数解析为绝对路径。 |
path.isAbsolute(path)判断参数 path 是否是绝对路径。 |
path.relative(from, to)用于将路径转为相对路径。 |
path.dirname(p)返回路径中代表文件夹的部分,同 Unix 的dirname 命令类似。 |
path.basename(p[, ext])返回路径中的最后一部分。同 Unix 命令 bashname 类似。 |
path.extname(p)返回路径中文件的后缀名,即路径中最后一个'.'之后的部分。如果一个路径中并不包含'.'或该路径只包含一个'.' 且这个'.'为路径的第一个字符,则此命令返回空字符串。 |
path.parse(pathString)返回路径字符串的对象。 |
path.format(pathObject)从对象中返回路径字符串,和 path.parse 相反。 |
属性:
path.sep |
| 平台的文件路径分隔符,'' 或 '/'。 |
path.delimiter平台的分隔符, ; or ':'. |
path.posix提供上述 path 的方法,不过总是以 posix 兼容的方式交互。 |
path.win32提供上述 path 的方法,不过总是以 win32 兼容的方式交互。 |
7.2.Path的使用
//路径的规范
var testURL=".././test/././demo.mp4";
var commonURL=path.normalize(testURL);
console.log("不规范: ",testURL,"规范: ",commonURL);
//连接路径
var myPath="itsource/h5/";
var joinPath=path.join(myPath,commonURL);
console.log("链接后: ",joinPath); //itsource/test/demo.mp4
//目录名
var dirname=path.dirname(joinPath);
console.log("目录名",dirname,"目录名2",path.parse(joinPath).dir);
//文件名
var filename=path.basename(joinPath);
console.log("文件名",filename,"文件名2",path.parse(joinPath).base,"文件名3",path.parse(joinPath).name);
//扩展名
var extname=path.extname(joinPath);
console.log("扩展名",extname,"扩展名2",path.parse(joinPath).ext);
8.url模块(重点)
url 模块提供了一些实用函数,用于 URL 处理与解析。 url模块提供了两套API来处理:一个是Node.js遗留的API,另一个则是通常使用在web浏览器中 实现了WHATWG URL Standard的API。
1.1.什么是URL?(重点中的重点)
/*
* URL模块:
* 1\. 什么是URL?
* url全球统一资源定位符,对网站资源的一种简洁表达形式,也称为网址。
*
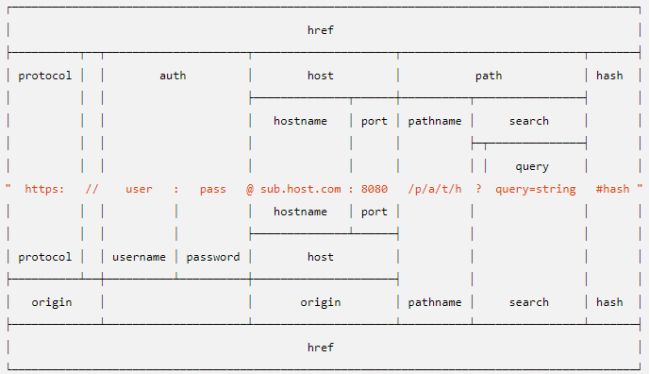
* 2\. URL的构成
* //完整结构
* 协议://用户名:密码@主机名.名.域:端口号/目录名/文件名.扩展名?参数名=参数值&参数名2=参数值2#hash
*
* //http协议的URL常见结构:
* 协议://主机名.名.域:端口/目录名/文件名.扩展名?参数名=参数值&参数名2=参数值2#hash
*
* https://www.baidu.com:443/img/bd_logo1.png
* http://music.163.com:80/#/discover/playlist
*
* 3\. node.js的URL模块
* 在node.js中提供了两套对于url进行处理的API功能。
* 1) 老的node.js url模块
* 2) 新的url模块(WHATWG URL标准模块)
*/
一个 URL 字符串是一个结构化的字符串,它包含多个有意义的组成部分。 当被解析时,会返回一个 URL 对象,它包含每个组成部分作为属性。
1.2.API方法和属性
方法:
| 方法 & 描述 |
|---|
Class: URL(网址)WHATWG URL标准的实现 |
属性:
url.hash获取及设置URL的分段(hash)部分。 |
url.host获取及设置URL的主机(host)部分。 |
url.hostname获取及设置URL的主机名(hostname)部分。 |
url.href获取及设置序列化的URL。 |
url.origin获取只读序列化的URL origin部分。 |
url.pathname获取及设置URL的路径(path)部分。 |
url.search获取及设置URL的序列化查询(query)部分。 |
| ... |
var url=require("url");
var imgUrl="http://www.uml.org.cn/DevProcess/images/20076614557200.jpg";
//1\. 老的node.js 的url模块
var oldUrl=url.parse(imgUrl);
console.log("老的URL中的各个部分",oldUrl);
/*
Url {
protocol: 'http:',
slashes: true,
auth: null,
host: 'www.uml.org.cn',
port: null,
hostname: 'www.uml.org.cn',
hash: null,
search: null,
query: null,
pathname: '/DevProcess/images/20076614557200.jpg',
path: '/DevProcess/images/20076614557200.jpg',
href: 'http://www.uml.org.cn/DevProcess/images/20076614557200.jpg' }
*/
//2\. 新的url模块(符合WHATWG标准)
var newUrl=new url.Url (imgUrl);
console.log("新的URL中的各个部分",newUrl);
/*
URL {
href: 'http://www.uml.org.cn/DevProcess/images/20076614557200.jpg',
origin: 'http://www.uml.org.cn',
protocol: 'http:',
username: '',
password: '',
host: 'www.uml.org.cn',
hostname: 'www.uml.org.cn',
port: '',
pathname: '/DevProcess/images/20076614557200.jpg',
search: '',
searchParams: URLSearchParams {},
hash: '' }
*/
mode.js仿Apach服务创建
const http = require('http');
const fs = require('fs');
const url = require('url');
//创建服务
let server = http.createServer(function(request,response){
//根据自己服务器文件的创建目录的规则,创建查找文件的格式
//fs.Stats 对象提供有关文件的信息。
fs.stat('work' + request.url,function(error,stat){ //['work']----->文件的名称 [request.url]------->请求文件下的文件路径 [function(error,stat){}]-----》回调函数,用于判断请求的文件是否找到。
if(error){
//response.writeHead向请求发送响应头。
response.writeHead(404 ,'not found' ,{"Content-Type":"text/plain;charset=utf-8"} ) //"Content-Type":"text/plain;charset=utf-8" 请求的类型 //[text/plain]普通文本
response.write('文件未找到');
response.end() //打断
}else{
//当浏览器可以找到文件是判断文件是否是空文件,或者包含子目录
if(stat.isFile()){
//异步地读取文件的全部内容。
fs.resdFile('work' + request.url,function(error,data){
if(error){
response.writeHead(500, 'server error' , {"Content-type":"text/plain;charset=utf-8"}) //[500, 'server error' ,]------->但浏览器可以打开文件时判断是否可以找到文件下的某一文件
response.write('服务器错误');
response.end() //打断
}else{
response.writeHead(200, 'ok',{"Content-type":"text/html;charset=utf-8"})
response.write(data);
response.end() //打断
}
});
}else{
//当在文件目录中没有找到文件时
var file = path.join('work' +request.url,function(error,data){
if(error){
//response.writeHead向请求发送响应头。
response.writeHead(404 ,'not found' ,{"Content-Type":"text/plain;charset=utf-8"} ) //"Content-Type":"text/plain;charset=utf-8" 请求的类型 //[text/plain]普通文本
response.write('文件未找到');
response.end() //打断
}else{
response.writeHead(200, 'ok',{"Content-type":"text/html;charset=utf-8"})
response.write(data);
response.end() //打断
}
});
}
}
});
});
console.log(11111111111111111111);
//开启监听端口
server.listen('13000',function(){
console.log('服务器已开启')
});
9.课程总结
9.1.重点
1.缓存区读写
2.文件系统基本操作
3.文件流读写
9.2.难点
1.流读写
9.3.如何掌握?
1.此技能通过使用升级。
2.将常见的用法截图保存到文件夹中,时常回顾。
9.4.排错技巧(技巧)
1.console.log()方法。
10.作业
作业难度: ☆☆☆
1、Buffer有什么作用?
2、文件读取方式的有几种,方法名是那些?
3、说说你对管道流的理解。
4、path模块的作用? 有哪些常用的方法?
5、url模块的作用? 有哪些常用的方法?
6、使用管道操作实现对一个文件体积较大的文件的复制
7、使用链式流实现对文件的压缩
8、使用代码删除某个文件夹,该文件夹不为空。(递归实现)
11.面试题
1.说说你对管道流的理解?
12.扩展知识或课外阅读推荐(可选)
12.1.扩展知识
在计算机中最小的【运算】单位是: 二进制位 bit
在计算机中最小的【存储】单位是: 字节 byte
1个字节 = 8个二进制位 >> 1byte = 8bit
1个字节:
0000 0000
需求: 向计算机中存储一个数字 5 ,怎么存?
1)需要将 5 转换成为二进制
2)进行存储
进制:
十进制: 逢十进一,如何表示: 0 1 2 3 4 5 6 7 8 9 10
二进制: 逢二进一,如何表示: 0 1 10 11 100 101
八进制: 逢八进一,如何表示: 0 1 2 3 4 5 6 7 10
十六进制:逢十六进一,如何表示: 0 1 2 3 4 5 6 7 8 9 a b c d e f 10
ff0000 == rgb(255,0,0)
进制转换:
1)十进制转其它进制(二进制、八进制、十六进制)
除法取余,倒回来读
示例: 十进制 22 => 二进制 10110
22 % 2 余数 0
11 % 2 余数 1
5 % 2 余数 1
2 % 2 余数 0
1 % 2 余数 1
0
2)其它进制转十进制
乘法
示例: 二进制 10110 > 十进制 22
12^4 + 02^3 + 12^2 + 12^1 + 0*2^0 = 16 + 0 + 4 + 2 + 0 = 22
十六进制ff > 十进制 255
f16^1 + f16^0 = 1516 + 151 = 240+15 = 255
编码:
ascii 美国通用信息编码集, 0--127 => 二进制 0-- 0111 1111 , 占1个字节
utf-8 全球通用信息编码集,一个中文占三个字节
0011 0001
0000 0000 0000 0000 0011 0001
8123000 张
8123001 李
8123002 王 => 0111 1011 1111 0010 0111 1010
gbk 中国国家通用信息编码集,一个中文占两个字节
0000 0000 0000 0000
256 张
257 李 => 0000 0001 0000 0001
258 王 => 0000 0001 0000 0010
big5 繁体中文
unicode 全球通用信息编码集,大字符集
0000 0000 0000 0000 0000 0000 0011 0001
注意:计算机在存储时,存储的是字符在编码集中的编号(编号是一个数字,数字可以转换成为二进制)
//如果目录有多级目录和文件,需定义递归函数,并且使用同步操作来删除
function delDir(dirName){
var fileList=fs.readdirSync(dirName);//获取文件或者目录列表
for(var i=0;i