摘要: DBA经常会用到的explain来查看SQL语句的执行计划,今天小人斗胆,从MySQL 5.7 Reference Manual中把MySQL EXPLAIN Output Format翻译过来。欢迎拍砖
Explain语句提供了一个select语句执行计划的信息。
Explain为每个用了select语句的表,返回一行信息。它列出了表中的顺序输出,MySQL会读取他们,然后再处理。MySQL解决了所有使用嵌套循环连接方法。这意味着MySQL会读取第一个表中的一行,然后在第二个表中找到一个匹配的行、第三个表,等等。当所有的表都被处理,MySQL输出所选择的列和回溯到的列表信息,直到发现有更多匹配行的表。下一行是从这个表中读取的,这个过程将继续同下一个表。
在MySQL 5.7.3之前,EXTENDED的关键词还在被使用,explain产生的额外信息可以通过explain后面的show warnings解释。EXPLAIN EXTENDED也显示filtered列。在MySQL 5.7.3,扩展输出默认开启,扩展关键词不再必要。
Note: You cannot usethe EXTENDED and PARTITIONS keywords together in the same EXPLAIN statement. In addition, neither of these keywordscan be used together with the FORMAT option. (FORMAT=JSON causesEXPLAIN to display extended and partition informationautomatically; using FORMAT=TRADITIONAL has no effect on EXPLAIN output.)
EXPLAIN Output Columns
本部分主要描述explain所产生的输出列,下部分提供了类型和额外的附加信息。Explain输出的每一行都有关于表的信息。每一行都包含下表总结的值,explain输出列,更详细的描述。列名在表的第一列显示;第二列提供了等效的属性名称,在输出时显示格式为JSON的使用。
Table 9.1 EXPLAIN Output Columns
Column |
JSON Name |
Meaning |
id |
select_id |
选择标识符 |
select_type |
None |
选择类型 |
table |
table_name |
输出行的表 |
partitions |
partitions |
匹配的分区 |
type |
access_type |
连接类型 |
possible_keys |
possible_keys |
可能用到的索引 |
key |
key |
实际用到的索引 |
key_len |
key_length |
用到索引的长度 |
ref |
ref |
列对应的索引 |
rows |
rows |
预测要检查的行数 |
filtered |
filtered |
表条件筛选行的百分比 |
Extra |
None |
额外的信息 |
id (JSON name: select_id)
选择标识符。这是select请求的序列号。如果引用其他行的结果,这个值可 以为null。在这种 情况下,表的列显示的值类似
select_type (JSON name: none)
选择的类型,它可以是下表中的任何一种。一个explain JSON-formatted显示了作为一个query_block属性时的SELECT类型,除非它是简单或主键。JSON的名称(如适用)也在表中显示。
select_type Value |
JSON Name |
Meaning |
SIMPLE |
None |
简单查询(没有union和子查询) |
PRIMARY |
None |
最外层查询 |
UNION |
None |
第二层,在select之后使用union |
DEPENDENT UNION |
dependent (true) |
union 语句中的第二个select,依赖于外部子查询 |
UNION RESULT |
union_result |
从一个union返回结果 |
SUBQUERY |
None |
子查询中的第一个select |
DEPENDENT SUBQUERY |
dependent (true) |
子查询中的第一个select依赖于外部子查询 |
DERIVED |
None |
派生表 select(from子句中的子查询) |
MATERIALIZED |
materialized_from_subquery |
物化子查询(具体化) |
UNCACHEABLE SUBQUERY |
cacheable (false) |
子查询的结果不能被缓存,必须重新评估每行的外部查询 |
UNCACHEABLE UNION |
cacheable (false) |
union中的第二个或后面的select 属于UNCACHEABLE SUBQUERY |
DEPENDENT SUBQUERY 不等价与 UNCACHEABLE SUBQUERY。相关子查询,子查询根据每组不同的值和不同的外部语境只会重新估值一次。不可缓存子查询,子查询根据每行不同的外部语境估值。.
可缓存的子查询不同于缓存查询的结果。查询缓存发生在子查询完成时,而查询缓存用于存储查询执行完成后的结果。
当使用explain时指定FORMAT=JSON,没有直接的输出等同于select_type,此时等同于把query_block的属性赋予SELECT。性能相当于大部分子查询类型只显示可用(例如 materialized_from_subquery for MATERIALIZED)并在适当的时候显示可用。没有JSON等价SIMPLE or PRIMARY.
在MySQL 5.7.2,select_type 等值non-SELECT 语句,显示受影响表的语句类型。For example, select_type is DELETE for DELETE statements。
table (JSON name: table_name)
输出引用行的表的名字,也可能是以下几种情况
SeeSection 9.2.1.18.2,“Optimizing Subqueries with Subquery Materialization”.
partitions (JSON name: partitions)
查询匹配的记录分区,只有在分区关键词被使用时,这列才会显示。未分区的表值为空。See Section 20.3.5,“Obtaining Information About Partitions”.
type (JSON name: access_type)
连接类型。描述不同的类型, see EXPLAIN JoinTypes
possible_keys (JSON name: possible_keys)
可能的索引列标识,哪个索引MySQL可能选择找到此表中的行。请注意,这列完全独立于explain输出里列表。这意味着一些关键词在 possible_keys里面可能不会被实际应用到。
如果这列为null(或者没有在JSON-formatted输出定义),没有相关的索引。在这种情况下,你可以提升你的请求性能,检查where子句是否引用了一些列或列,适用于索引。如果是这样的话,创建一个合适的索引,然后再用explain检查一遍query。SeeSection 14.1.8, “ALTER TABLE Syntax”.
看表都有什么索引,用SHOW INDEXFROM tbl_name.
key (JSON name: key)
key这列标明了MySQL真实用到的索引。如果MySQL决定使用possible_keys 里面的索引去遍历行,这个索引作为key的值被列出。
key的值也可能不在 possible_keys 里。如果possible_keys里的索引都不适合遍历行,那么所有被查询的列会用其他索引。也就是说,查询的列用到了索引,即使它没有被用来决定检索哪些行,索引扫描也比直接扫描数据有效果。在InnoDB引擎下,即使请求查询主键列也可能用到二级索引,因为InnoDB在每一个二级索引里存储主键值。如果key 是空的,MySQL发现没有索引用来提高查询效率。
强制MySQL去使用或忽略一个在 possible_keys 列的索引, 使用FORCEINDEX, USE INDEX, or IGNORE INDEX in your query. See Section 9.9.4,“Index Hints”.
对于MyISAM 表, 使用 ANALYZE TABLE 帮助优化选择更好的索引。 For MyISAM tables, myisamchk--analyze doesthe same. See Section 14.7.2.1, “ANALYZE TABLE Syntax”, and Section 8.6,“MyISAM Table Maintenance and Crash Recovery”.
key_len (JSON name: key_length)
key_len 这列显示的MySQL使用索引的长度。key_len的值可以让你决定MySQL使用前缀索引的长度。如果key列是null, len_len 列也是 NULL。
由于索引的存储格式,一个null列索引长度可能比not null更大。
ref (JSON name: ref)
ref 列显示哪列或常量常被用来和key配合从表中查出数据。
如果值是 func,它的值是一些函数的结果。去看是哪个函数,使用 EXPLAIN EXTENDED 然后SHOW WARNINGS。函数实际上可能是一个运算符,如算术运算符。
rows (JSON name: rows)
rows 列显示MySQL查询请求必须检查的行数。
对于 InnoDB 表, 这个数字是个约数,并不能总是很精确。
filtered (JSON name: filtered)
filtered 列显示表行的估计百分比。rows显示检查的预计行数,rows × filtered / 100 显示之前连接那个表的行数。在MySQL 5.7.3以前,如果你使用 EXPLAIN EXTENDED,这列会显示。到了MySQL 5.7.3,扩展输出默认开启,扩展关键词也不是必须的。
Extra (JSON name: none)
这列包含关于MySQL如何解决查询问题的更多信息。对于不同值得描述,请看EXPLAIN Extra Information.
没有简单的JSON 格式对应 Extra 列;然而,当列表JSON特性或者消息属性的本质,会有值。
EXPLAIN Join Types
Type这列显示的是表连接类型。下面描述的连接类型,默认从最优到最差。
system
这个表只有一行数据(= system table). 这是const连接类型的一个特例。
const
这个表至少有一行匹配,在查询开始时读。因为只有一行,这行中的列值可以被优化器当作常数。Const表非常快,因为只读一次。
当主键或联合索引的所有部分和常量比较时,会用到const。
const is used when you compare all parts of a PRIMARYKEY or UNIQUE
index to constant values. In the following queries,tbl_name canbe used as a const table:

eq_ref
先前表中的每一行在这个表中只能找到一行。除了system和const连接类型,这是最可能的连接类型。连接时,主键或唯一非null索引全部使用时会使用此类型。
eq_ref可以被用在索引列进行“=”号操作符比较时。比较值可以是一个常量或者在这个表之前读取的表中的列的表达式。
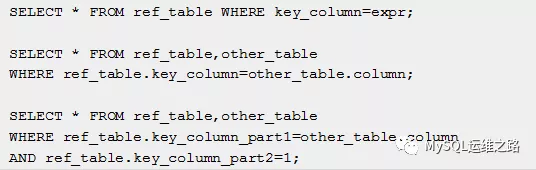
The following examples, MySQL can use an eq_ref join to process ref_table

ref
先前表中的所有行索引匹配值都从这个表中读取。如果连接只用到了最左前 缀索引或者索引不是主键或者唯一索引(换句话说,连接不能基于键值选择简单的一行)使用到ref类型。如果索引只是被用来匹配几行,这是一个好的连接型
ref can be usedfor indexed columns that are compared using the = or <=>
operator. In the following examples, MySQL can use a ref join to process ref_table:
fulltext
全文索引会用到这个链接类型。
ref_or_null
这个连接类型和ref很像,做为补充,MySQL为包含NULL值得行做了其他查询。这种连接类型最常用来解决子查询。
In thefollowing examples, MySQL can use a ref_or_null join to process ref_table:

See Section 9.2.1.8, “IS NULLOptimization”.
index_merge
此连接类型表示使用索引合并优化。在这种情况下,输出的索引列包含使用的索引的列表,key_len显示所用索引的最大部分。
For moreinformation, seeSection 9.2.1.4, “Index MergeOptimization”.
unique_subquery
This typereplaces eq_ref forsome IN subqueriesof the following form:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
Unique_subquery .只是一个索引查找函数来替代子查询获得更好的性能。
index_subquery
这种连接类型类似unique_subquery。它替代in 类型子查询,但是它在非唯一索引的子查询中起作用。
It replaces IN subqueries,but it works for nonunique indexes in subqueries of the following form:
![]()
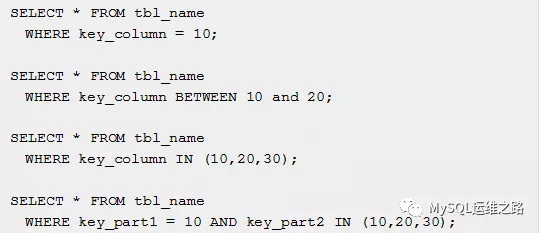
range
只有在给定范围的行中被检索,使用索引查询这些行。再输出的索引列中指明哪个索引被使用。Key_len包含被使用的最大索引长度。这种类型ref列为null。
Range can beused when a key column is compared to a constant using any of the =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, or IN() operators:
index
这种连接类型和all一样,除了扫描索引树。发生在下面两种情况:
1、如果对于查询索引是一个覆盖索引并且可以满足这个表所有数据的查询,只是扫描索引树。这种情况下, Extra 列显示 Using index。index-only类型扫描通常比 ALL类型快,因为索引的大小通常比表数据小。
2、全表扫描利用索引来查找数据行中的索引。Uses index 不出现Extra 列。
当查询索引列的部分时,MySQL 可以使用这种类型。
ALL
全表扫描,性能很差。通常可以添加索引来避免这种情况
A fulltable scan is done for each combination of rows from the previous
tables. This is normally not good if the table is the first table not marked const, andusually very bad in all other cases. Normally, you canavoid ALL by addingindexes that enable row retrieval from the table based on constant values orcolumn values from earlier tables.
EXPLAIN Extra Information
Extra 列是 EXPLAIN 输出的额外信息关于MySQL 解析查询。下面的信息是可能出现在这列的值。每个项目还包含了JSON-formatted 输出信息显示的附加值。对于其中的一些,它是一个特定的属性。其他显示消息属性文本。
如果你想让你的查询尽可能的快,查看 Extra 列的值是否是 Using filesort and Using temporary, 或者 JSON-formatted EXPLAIN output, using_filesort 和 using_temporary_table基本等价。
Child of 'table' pushed join@1 (JSON: message text)
This tableis referenced as the child of table in a join that can be pushed down to the NDBkernel. Applies only in MySQL Cluster, when pushed-down joins are enabled. Seethe description of the ndb_join_pushdown serversystem variable for more information and examples.
const row not found (JSON property: const_row_not_found)
For aquery such as SELECT ... FROM tbl_name,the table was empty.
Deleting all rows (JSON property: message)
For DELETE, some storage engines (such as MyISAM) support a handler methodthat removes all table rows in a simple and fast way. This Extra valueis displayed if the engine uses this optimization.
Distinct (JSON property: distinct)
MySQL 查询不同的值,当它发现第一个匹配的行时停止查找。
FirstMatch(tbl_name) (JSON property: first_match)
Thesemi-join FirstMatch join shortcutting strategy is used for tbl_name.
Full scan on NULL key (JSON property: message)
This occurs for subquery optimization as afallback strategy when the optimizer cannot use an index-lookup access method.
Impossible HAVING (JSON property: message)
HAVING 字句经常错误不能查询任何行。
Impossible WHERE (JSON property: message)
The WHERE clauseis always false and cannot select any rows.
Impossible WHERE noticed after reading const tables (JSONproperty: message)
MySQL hasread all const (and system) tables andnotice that the WHERE clause is always false.
Loose Scan(m..n) (JSON property: message)
Thesemi-join LooseScan strategy is used. m and n are key part numbers.
No matching min/max row (JSON property: message)
No rowsatisfies the condition for a query such as SELECTMIN(...) FROM ... WHERE condition.
no matching row in const table (JSON property: message)
For a query with a join, there was an emptytable or a table with no rows satisfying a unique index condition.
No matching rows after partition pruning (JSONproperty: message)
For DELETE or UPDATE, the optimizer found nothing to delete or updateafter partition pruning. It is similar in meaning to Impossible WHERE for SELECT statements.
No tables used (JSON property: message)
The queryhas no FROM clause,or has a FROM DUAL clause.
For INSERT or REPLACE statements, EXPLAIN displays this value when there is no SELECT part. For example, it appears forEXPLAIN INSERT INTO t VALUES(10) because that is equivalent to EXPLAIN INSERT INTO t SELECT 10 FROM DUAL.
Not exists (JSON property: message)
MySQL wasable to do a LEFT JOIN optimization on the query and does not examine morerows in this table for the previous row combination after it finds one row thatmatches the LEFT JOIN criteria. Here is an example of the type of querythat can be optimized this way:
Assumethat t2.id is defined as NOT NULL. In this case, MySQL scans t1 and looks up the rows in t2 usingthe values oft1.id. If MySQL finds a matching row in t2, it knowsthat t2.id can never be NULL, and does not scan through the rest of the rows in t2 thathave the same id value.In other words, for each row in t1, MySQL needs to do only a single lookup in t2,regardless of how many rows actually match in t2.
Plan isn't ready yet (JSON property: none)
This valueoccurs with EXPLAIN FOR CONNECTION whenthe optimizer has not finished creating the execution plan for the statementexecuting in the named connection. If execution plan output comprises multiplelines, any or all of them could have this Extra value, depending on the progress of the optimizerin determining the full execution plan.
Range checked for each record (index map: N) (JSONproperty: message)
MySQLfound no good index to use, but found that some of indexes might be used aftercolumn values from preceding tables are known. For each row combination in thepreceding tables, MySQL checks whether it is possible to use a range orindex_merge accessmethod to retrieve rows. This is not very fast, but is faster than performing ajoin with no index at all. The applicability criteria are as described in Section 9.2.1.3, “Range Optimization”,and Section 9.2.1.4, “Index MergeOptimization”, with the exception that all column values for thepreceding table are known and considered to be constants.
Indexesare numbered beginning with 1, in the same order as shown by SHOW INDEX for the table. Theindex map value N is a bitmask value that indicates which indexes arecandidates. For example, a value of 0x19 (binary 11001) means that indexes 1, 4, and 5 willbe considered.
Scanned N databases (JSON property: message)
Thisindicates how many directory scans the server performs when processing a queryfor INFORMATION_SCHEMA tables, as described in Section 9.2.4,“Optimizing INFORMATION_SCHEMA Queries”. The value of N canbe 0, 1, or all.
Select tables optimized away (JSON property: message)
The optimizer determined 1) that at mostone row should be returned, and 2) that to produce this row, a deterministicset of rows must be read. When the rows to be read can be read during theoptimization phase (for example, by reading index rows), there is no need toread any tables during query execution.
The firstcondition is fulfilled when the query is implicitly grouped (contains anaggregate function but no GROUP BY clause). The second condition is fulfilled when onerow lookup is performed per index used. The number of indexes read determinesthe number of rows to read.
Consider the following implicitly groupedquery:![]() Supposethat MIN(c1) can be retrieved by reading one index row and MIN(c2) canbe retrieved by reading one row from a different index. That is, for eachcolumn c1 and c2, thereexists an index where the column is the first column of the index. In thiscase, one row is returned, produced by reading two deterministic rows.
Supposethat MIN(c1) can be retrieved by reading one index row and MIN(c2) canbe retrieved by reading one row from a different index. That is, for eachcolumn c1 and c2, thereexists an index where the column is the first column of the index. In thiscase, one row is returned, produced by reading two deterministic rows.
This Extra valuedoes not occur if the rows to read are not deterministic. Consider this query: ![]()
Supposethat (c1, c2) is a covering index. Using this index, all rowswith c1 <= 10 must be scanned to find the minimumc2 value.By contrast, consider this query:![]()
In thiscase, the first index row with c1 = 10 contains the minimum c2 value. Only one row must be read to produce thereturned row.
Forstorage engines that maintain an exact row count per table (such as MyISAM, butnot InnoDB), this Extra value can occur for COUNT(*) queries for which the WHERE clause is missing or always true and there isno GROUP BY clause. (This is an instance of an implicitlygrouped query where the storage engine influences whether a deterministicnumber of rows can be read.)
Skip_open_table, Open_frm_only, Open_full_table (JSONproperty: message)
Thesevalues indicate file-opening optimizations that apply to queries for INFORMATION_SCHEMA tables, as described inSection 9.2.4,“Optimizing INFORMATION_SCHEMA Queries”.
1、Skip_open_table:Table files do not need to be opened. The information has already becomeavailable within the query by scanning the database directory.
2、Open_frm_only:Only the table's .frm file need be opened.
3、Open_full_table:The unoptimized information lookup. The .frm, .MYD, and .MYI files must be opened.
Start temporary, End temporary (JSONproperty: message)
This indicates temporary table use for thesemi-join Duplicate Weedout strategy.
unique row not found (JSON property: message)
For aquery such as SELECT ... FROM tbl_name,no rows satisfy the condition for a UNIQUE index or PRIMARYKEY on the table.
Using filesort (JSON property: using_filesort)
MySQL 需要做一个额外的排序去查找如何检索排序中的行。排序通过所有行的连接类型和索引的存储顺序和指向行的指针去匹配where字句。索引排序然后根据排序检索行。See Section 9.2.1.15, “ORDER BYOptimization”.
Using index (JSON property: using_index)
从表中读取列信息仅仅使用索引树中的信息,没有必须额外去回表。这个策略可以被使用在查询仅使用了索引列的一部分。
InnoDB 表有一个自定义的聚集索引,即使 Extra列没有Usingindex也会被使用。如果 type is index and key is PRIMARY,发生这种情况。
Using index condition (JSON property: using_index_condition)
Tables areread by accessing index tuples and testing them first to determine whether toread full table rows. In this way, index information is used to defer (“push down”) reading full table rows unless it is necessary.See Section 9.2.1.6,“Index Condition Pushdown Optimization”.
IndexCondition Pushdown (ICP)是MySQL 5.6版本中的新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式。
1、当关闭ICP时,index 仅仅是data access 的一种访问方式,存储引擎通过索引回表获取的数据会传递到MySQL Server层进行where条件过滤。
2、当打开ICP时,如果部分where条件能使用索引中的字段,MySQL Server会把这部分下推到引擎层,可以利用index过滤的where条件在存储引擎层进行数据过滤,而非将所有通过index access的结果传递到MySQL server层进行where过滤。
优化效果:ICP能减少引擎层访问基表的次数和MySQL Server访问存储引擎的次数,减少IO次数,提高查询语句性能。
Using index for group-by (JSON property: using_index_for_group_by)
类似使用索引访问表的方法, Using index for group-by 表明MySQL 发现一个索引可以被用来检索所有列关于GROUP BY or DISTINCT 查询,没有任何额外的访问磁盘回表。此外,这个索引被使用最有效的方式对每个group,只有几个索引被读取。
Fordetails, seeSection 9.2.1.16, “GROUP BYOptimization”.
Using join buffer (Block Nested Loop), Using joinbuffer (Batched Key Access) (JSON property:using_join_buffer)
将join前面的表的一部分放到join buffer中,然后用buffer中的记录跟当前表执行join操作。(Block Nested Loop) 表示使用Block Nested-Loop算法,(Batched Key Access) 表示使用Batched Key Access算法。就是说,前面的key列中出现的字段会放到join buffer中,然后从出现 Using join buffer 的那一行table字段列出的表中分批取回匹配的行。
InJSON-formatted output, the value of using_join_buffer is always either one of Block Nested Loop or BatchedKey Access.
Using MRR (JSON property: message)
Tables areread using the Multi-Range Read optimization strategy. See Section 9.2.1.13, “Multi-RangeRead Optimization”.
Using sort_union(...), Using union(...), Usingintersect(...) (JSON property: message)
Theseindicate how index scans are merged for the index_merge jointype. See Section 9.2.1.4, “Index MergeOptimization”.
Using temporary (JSON property: using_temporary_table)
为了处理查询,需要创建临时表保存结果。如果查询语句包含GROUP BY和ORDER BY并且列出的字段不一样,Extra会出现此信息。
Using where (JSON property: attached_condition)
WHERE子句用于限制返回给客户端或与下一个表匹配的记录。除非你确实想要获取或检查表的所有行,否则查询会有问题,若Extra不包含Using where并且连接类型为ALL或index。
Using where has no direct counterpart in JSON-formatted output;the attached_condition property contains any WHEREcondition used.
Using where with pushed condition (JSONproperty: message)
This itemapplies to NDB tables only. It meansthat MySQL Cluster is using the Condition Pushdown optimization to improve theefficiency of a direct comparison between a nonindexed column and a constant.In such cases, the condition is “pushed down” tothe cluster's data nodes and is evaluated on all data nodes simultaneously.This eliminates the need to send nonmatching rows over the network, and canspeed up such queries by a factor of 5 to 10 times over cases where ConditionPushdown could be but is not used. For more information, see Section 9.2.1.5,“Engine Condition Pushdown Optimization”.
Zero limit (JSON property: message)
The queryhad a LIMIT 0 clause and cannot select any rows.
为了方便大家交流,本人开通了微信公众号,和QQ群291519319。喜欢我的一起来交流吧
