1. 读取数据库的形式创建DataFrame
DataFrameFromJDBC
object DataFrameFromJDBC { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 创建连接数据库需要的参数 val probs: Properties = new Properties() probs.setProperty("driver", "com.mysql.jdbc.Driver") probs.setProperty("user","root") probs.setProperty("password", "feng") // 使用sparksession创建DF val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8", "t_result", probs) // df.printSchema() // import spark.implicits._ // df.where($"total_money" > 500).show() // 此种形式一定要导入隐式转换 df.where("money > 500").show() // 可以不导入隐式转换 } }
2. Parquet格式的数据源
2.1 spark读取的数据源效率高低需要考虑下面三点
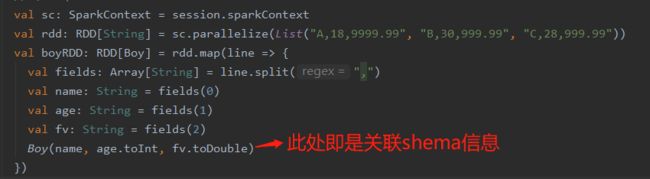
- 1. park SQL可以读取结构化数据,读取对应格式 数据可以返回DataFrame【元数据信息,不返回的话就要自己关联shema信息,如下图】
数据存储格式有schema信息
- 2. 数据存储空间更小
有特殊的序列化机制,可以使用高效的压缩机制
- 3. 读取的效率更高
使用高效的序列化和反序列化机制,可以指定查询哪些列,不select某些列,就不读取对应的数据(以前rdd读取数据的话是每行数据的所有列(字段)都会读取)
2.2 json、csv、Parquet形式的数据源的读取效率对比
2.2.1
(1)json(满足2.1中的1)

数据会有冗余,name、age等字段属性会被多次读取
(2)csv(满足2.1中的2)
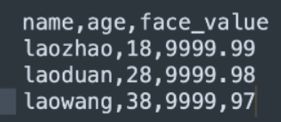
此种形式的数据读取只会读取一次字段属性,效率相比json的形式高点,但它默认没有压缩方式
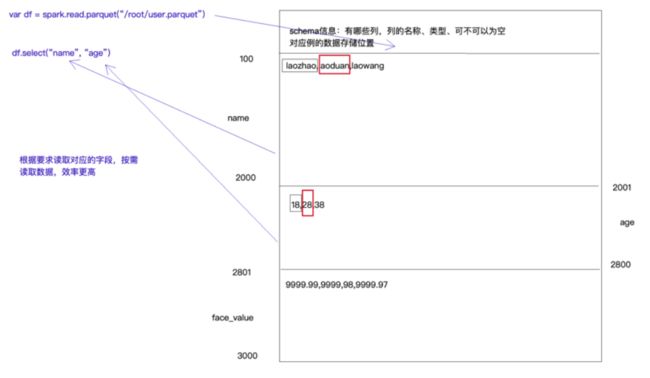
(3)Parquet(满足2.1中的三点,是spark最喜欢的数据源格式)
读取数据可以返回元数据信息、
支持压缩,默认是snappy压缩
更加高效的序反列化,列式存储
2.2.2 案 例:
(1)获取parquet格式数据
object JDBCToParquet { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 创建连接数据库需要的参数 val probs: Properties = new Properties() probs.setProperty("driver", "com.mysql.jdbc.Driver") probs.setProperty("user","root") probs.setProperty("password", "feng") // 使用sparksession创建DF val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8", "t_result", probs) // 将df的数据转换成parquet df.write.parquet("E:/javafile/spark/out1") spark.stop() } }
得到的文件部分内容如下(可见是被处理过的)
(2)读取parquet格式的文件
object JDBCToParquet { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 创建连接数据库需要的参数 val df: DataFrame = spark.read.parquet("E:/javafile/spark/part1.snappy.parquet") //df.show() //parquet格式是列式存储,可以按需查询,效率更高 df.select("cname", "money").show() spark.stop() } }
运行结果
3. Orc格式的数据源
(1)获取Orc格式数据(hive喜欢的数据格式)
package com._51doit.spark08 import java.util.Properties import org.apache.spark.sql.{DataFrame, SparkSession} object JDBCToOrc { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .enableHiveSupport() // 让sparkSQL开启对Hive的支持 .getOrCreate() // 创建连接数据库需要的参数 val probs: Properties = new Properties() probs.setProperty("driver", "com.mysql.jdbc.Driver") probs.setProperty("user","root") probs.setProperty("password", "feng") // 使用sparksession创建DF val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8", "t_result", probs) // 将df数据转换成Orc df.write.orc("E:/javafile/spark/out2") spark.stop() } }
(2)读取Orc格式的文件
object OrcDataSource { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .enableHiveSupport() // 让sparkSQL开启对Hive的支持 .getOrCreate() // 读取Orc数据源 val df: DataFrame = spark.read.orc("E:/javafile/spark/out2") // df.printSchema() df.where("money > 500").show() spark.stop() } }