TCP三次握手
三次握手(Three-way Handshake),是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。为的是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确认号并交换TCP窗口大小信息,在socket编程中,客户端执行connect()时,将触发三次握手
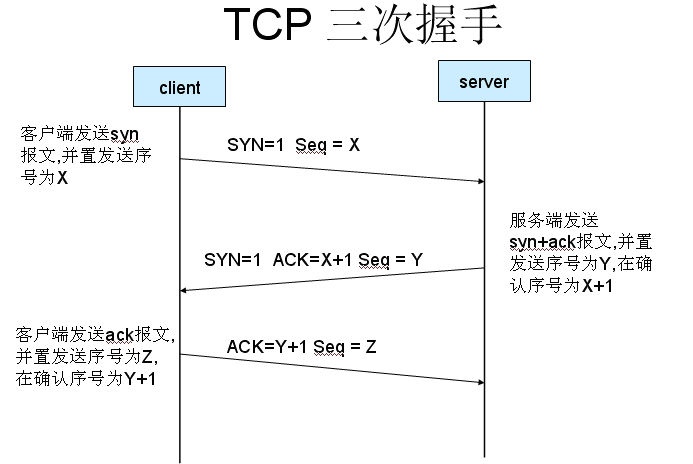
第一次握手:
建立连接时,客户端发送syn包(seq=j)到服务器,并进入SYN——SENT状态,等待服务器确认
SYN(Synchronize Sequence Numbers):同步序列编号
第二次握手
服务器收到syn包,必须确认客户的SYN(ack = j+1),同时自己也发送一个SYN包(seq=k),即SYN+ACK包,此时服务器进入SYN_RECV状态
第三次握手
客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(连接成功)状态,完成三次握手
TCP四次挥手
TCP的连接的拆除需要发送四个包,因此称为四次挥手(four-way handshake)。由于TCP连接是全双工的,因此每个反向都必须单独进行关闭,原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接,收到一个FIN只意外着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。客户端或服务器均可主动发起挥手动作,在socket编程中,任何一方执行close()操作即可产生挥手操作。
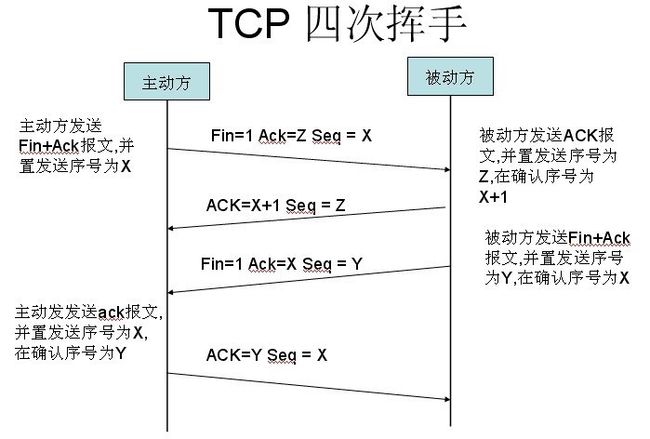
(1)主动方A发送一个FIN,用来关闭A到被动方B的数据传送。
(2)被动方B收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(报文段5)。和SYN一样,一个FIN将占用一个。
(3)被动方B关闭与主动方A的连接,发送一个FIN给客户端A(报文段6)。
(4)客户端A发回ACK报文确认,并将确认序号设置为收到序号加1(报文段7)
代码分析
客户端申请TCP连接
int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = move_addr_to_kernel(uservaddr, addrlen, &address);
if (err < 0)
goto out_put;
err =
security_socket_connect(sock, (struct sockaddr *)&address, addrlen);
if (err)
goto out_put;
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen,
sock->file->f_flags);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
客户端发送SYN报文
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *usin = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct tcp_sock *tp = tcp_sk(sk);
__be16 orig_sport, orig_dport;
__be32 daddr, nexthop;
struct flowi4 *fl4;
struct rtable *rt;
int err;
struct ip_options_rcu *inet_opt;
struct inet_timewait_death_row *tcp_death_row = &sock_net(sk)->ipv4.tcp_death_row;
if (addr_len < sizeof(struct sockaddr_in))
return -EINVAL;
if (usin->sin_family != AF_INET)
return -EAFNOSUPPORT;
nexthop = daddr = usin->sin_addr.s_addr;
inet_opt = rcu_dereference_protected(inet->inet_opt,
lockdep_sock_is_held(sk));
if (inet_opt && inet_opt->opt.srr) {
if (!daddr)
return -EINVAL;
nexthop = inet_opt->opt.faddr;
}
orig_sport = inet->inet_sport;
orig_dport = usin->sin_port;
fl4 = &inet->cork.fl.u.ip4;
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
orig_sport, orig_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
if (err == -ENETUNREACH)
IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES);
return err;
}
if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) {
ip_rt_put(rt);
return -ENETUNREACH;
}
if (!inet_opt || !inet_opt->opt.srr)
daddr = fl4->daddr;
if (!inet->inet_saddr)
inet->inet_saddr = fl4->saddr;
sk_rcv_saddr_set(sk, inet->inet_saddr);
if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) {
/* Reset inherited state */
tp->rx_opt.ts_recent = 0;
tp->rx_opt.ts_recent_stamp = 0;
if (likely(!tp->repair))
tp->write_seq = 0;
}
inet->inet_dport = usin->sin_port;
sk_daddr_set(sk, daddr);
inet_csk(sk)->icsk_ext_hdr_len = 0;
if (inet_opt)
inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen;
tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT;
tcp_set_state(sk, TCP_SYN_SENT);
err = inet_hash_connect(tcp_death_row, sk);
if (err)
goto failure;
sk_set_txhash(sk);
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
rt = NULL;
goto failure;
}
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
rt = NULL;
if (likely(!tp->repair)) {
if (!tp->write_seq)
tp->write_seq = secure_tcp_seq(inet->inet_saddr,
inet->inet_daddr,
inet->inet_sport,
usin->sin_port);
tp->tsoffset = secure_tcp_ts_off(sock_net(sk),
inet->inet_saddr,
inet->inet_daddr);
}
inet->inet_id = tp->write_seq ^ jiffies;
if (tcp_fastopen_defer_connect(sk, &err))
return err;
if (err)
goto failure;
err = tcp_connect(sk);
if (err)
goto failure;
return 0;
failure:
tcp_set_state(sk, TCP_CLOSE);
ip_rt_put(rt);
sk->sk_route_caps = 0;
inet->inet_dport = 0;
return err;
}
服务器等待连接请求
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
struct request_sock *req;
struct sock *newsk;
int error;
lock_sock(sk);
error = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
goto out_err;
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
error = -EAGAIN;
if (!timeo)
goto out_err;
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
req = reqsk_queue_remove(queue, sk);
newsk = req->sk;
if (sk->sk_protocol == IPPROTO_TCP &&
tcp_rsk(req)->tfo_listener) {
spin_lock_bh(&queue->fastopenq.lock);
if (tcp_rsk(req)->tfo_listener) {
req->sk = NULL;
req = NULL;
}
spin_unlock_bh(&queue->fastopenq.lock);
}
out:
release_sock(sk);
if (req)
reqsk_put(req);
return newsk;
out_err:
newsk = NULL;
req = NULL;
*err = error;
goto out;
}
服务器接收SYN,发送SYN+ACK
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
struct dst_entry *dst = sk->sk_rx_dst;
sock_rps_save_rxhash(sk, skb);
sk_mark_napi_id(sk, skb);
if (dst) {
if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif ||
!dst->ops->check(dst, 0)) {
dst_release(dst);
sk->sk_rx_dst = NULL;
}
}
tcp_rcv_established(sk, skb);
return 0;
}
if (tcp_checksum_complete(skb))
goto csum_err;
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_cookie_check(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
} else
sock_rps_save_rxhash(sk, skb);
if (tcp_rcv_state_process(sk, skb)) {
rsk = sk;
goto reset;
}
return 0;
reset:
tcp_v4_send_reset(rsk, skb);
discard:
kfree_skb(skb);
return 0;
csum_err:
TCP_INC_STATS(sock_net(sk), TCP_MIB_CSUMERRORS);
TCP_INC_STATS(sock_net(sk), TCP_MIB_INERRS);
goto discard;
}
客户端收到SYN+ACK,发送ACK
static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th, unsigned int len)
{
..
tcp_send_ack(sk);
...
}